
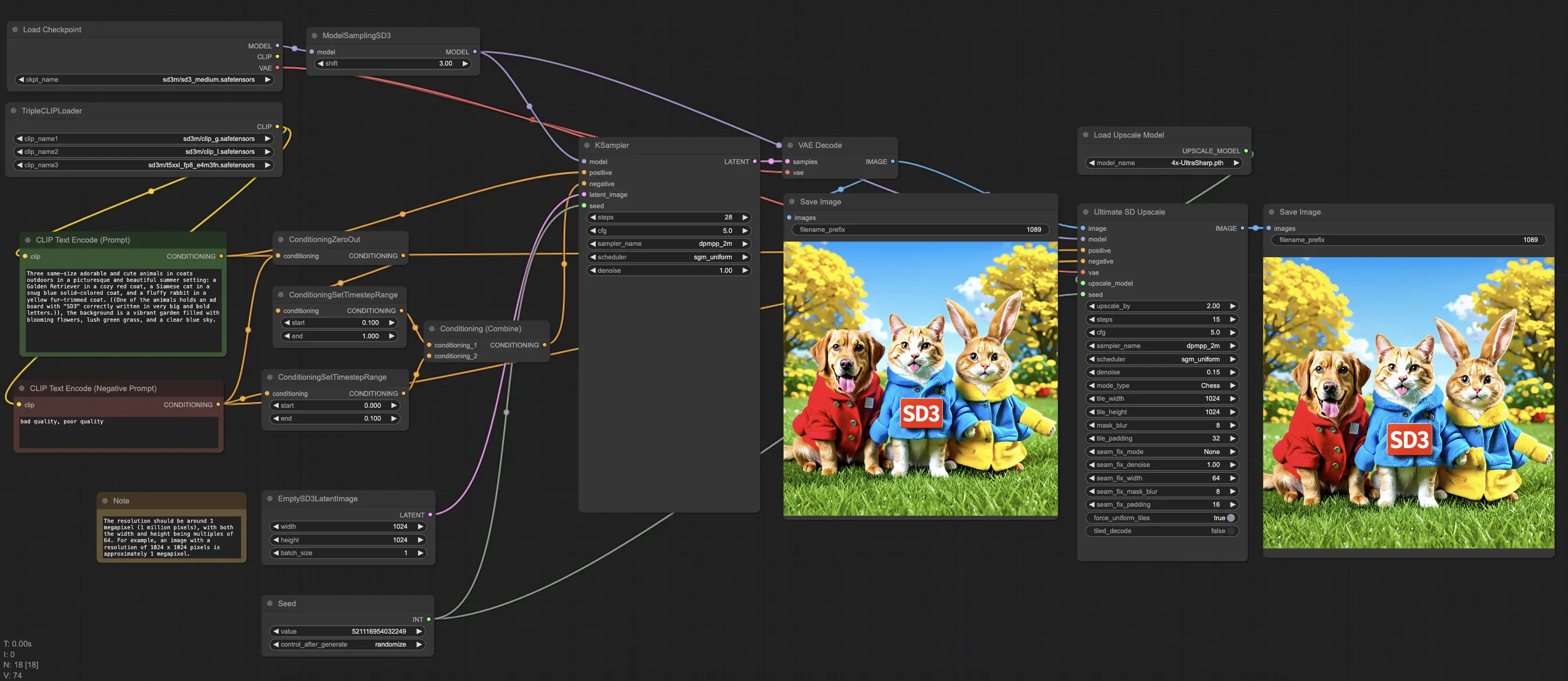



1. ComfyUI Stable Diffusion 3를 사용한 창의적 프로세스 향상#
🌟🌟🌟Stable Diffusion 3 Medium 모델과 관련 노드가 이제 RunComfy의 ComfyUI Beta Version (Version 24.06.13.0)에 사전 로드되었습니다!!!🌟🌟🌟 ComfyUI 워크플로우 내에서 Stable Diffusion 3 Medium을 직접 사용하거나 기존 ComfyUI 워크플로우에 원활하게 통합할 수 있습니다.
ComfyUI Stable Diffusion 3 워크플로우는 모든 필요한 Stable Diffusion 3 Medium 모델을 포함합니다. 다양한 프롬프트나 파라미터를 실험하여 경험해보세요!
1.1. ComfyUI에 사전 로드된 Stable Diffusion 3 Medium 모델#
sd3_medium.safetensors: MMDiT 및 VAE 가중치를 포함하지만 텍스트 인코더는 포함되지 않습니다.sd3_medium_incl_clips_t5xxlfp16.safetensors: T5XXL 텍스트 인코더의 fp16 버전을 포함한 모든 필요한 가중치를 포함합니다.sd3_medium_incl_clips_t5xxlfp8.safetensors: T5XXL 텍스트 인코더의 fp8 버전을 포함하여 품질과 자원 요구 사항의 균형을 제공합니다.sd3_medium_incl_clips.safetensors: T5XXL 텍스트 인코더를 제외한 모든 필요한 가중치를 포함합니다. 이 버전은 최소한의 자원을 필요로 하지만, T5XXL 텍스트 인코더가 없으면 모델의 성능이 다를 수 있습니다.text_encoders폴더에는 세 개의 텍스트 인코더와 사용자의 편의를 위한 원본 모델 카드 링크가 포함되어 있습니다. 이 폴더 내의 모든 구성 요소(및 다른 패키지에 포함된 동등한 구성 요소)는 해당 원본 라이선스에 따라 사용됩니다.
1.2 Stable Diffusion 3 Medium의 전체 품질 및 사실성#
Stable Diffusion 3 Medium은 AI 아트 커뮤니티에서 이미지 품질의 새로운 기준을 설정합니다. 이 모델은 뛰어난 세부 묘사, 색상 정확도, 현실적인 조명으로 이미지를 제공합니다. 다음과 같은 기대를 할 수 있습니다:
- 세부 사항 및 해상도: 복잡한 세부 사항을 렌더링하는 향상된 능력으로, 클로즈업 및 복잡한 구성에 이상적입니다.
- 색상 및 조명: 향상된 알고리즘은 색상이 생동감 있고 사실적으로 보이도록 하며, 동적 조명 효과가 깊이와 현실감을 더합니다.
- 얼굴과 손의 사실성: 16채널 변량 오토인코더(VAE)와 같은 혁신 덕분에 왜곡된 손과 얼굴과 같은 일반적인 문제점이 크게 감소했습니다.
1.3 Stable Diffusion 3 Medium의 프롬프트 이해력#
SD3 Medium의 뛰어난 기능 중 하나는 정교한 프롬프트 이해력입니다. 이 모델은 공간적 추론, 구성 요소, 동작 및 스타일을 포함하는 길고 복잡한 프롬프트를 해석할 수 있습니다. 다음과 같은 하이라이트가 있습니다:
- 텍스트 인코더: 성능과 효율성의 균형을 맞추기 위해 세 개의 텍스트 인코더를 사용합니다. 이를 통해 상세한 프롬프트의 미묘한 이해와 실행이 가능합니다.
- 구성 인식: 공간적 관계를 유지하고 설명된 장면을 정확히 묘사할 수 있어 시각적 스토리텔링에 이상적입니다.
1.4 Stable Diffusion 3 Medium의 타이포그래피#
텍스트-이미지 생성에서 타이포그래피는 항상 도전 과제였습니다. SD3 Medium은 이 문제를 놀라운 성공으로 해결합니다:
- 텍스트 품질: 철자, 자간, 글자 형성 및 간격에서 전례 없는 정확성을 달성합니다.
- Diffusion Transformer Architecture: 이 고급 아키텍처는 이미지 내 텍스트의 더 정확한 렌더링을 가능하게 하여 오류를 줄이고 시각적 일관성을 향상시킵니다.
1.5 Stable Diffusion 3 Medium의 자원 효율성#
고급 기능에도 불구하고 SD3 Medium은 자원 효율성을 염두에 두고 설계되었습니다:
- 낮은 VRAM 사용량: 성능 저하 없이 표준 소비자 GPU에서 실행할 수 있어 고품질 AI 아트를 더 넓은 관객에게 제공합니다.
- 효율성을 위한 최적화: 컴퓨팅 요구와 출력 품질의 균형을 맞추어, 덜 강력한 하드웨어에서도 원활한 작동을 보장합니다.
1.6 Stable Diffusion 3 Medium의 세부 조정#
AI 예술가에게 맞춤화는 중요한 측면이며, SD3 Medium은 이 분야에서 뛰어납니다:
- 세부 사항 흡수: 소규모 데이터셋으로 세부 조정이 가능하여 예술가들이 고유한 스타일을 적용하거나 특정 프로젝트 요구 사항을 충족할 수 있습니다.
- 다양성: 특정 테마, 스타일 또는 복잡한 세부 사항을 작업하든 SD3 Medium은 개인화된 예술 작품을 위한 유연성을 제공합니다.
2. Stable Diffusion 3란 무엇인가#
Stable Diffusion 3는 프롬프트에서 이미지를 생성하도록 설계된 최첨단 AI 모델입니다. Stable Diffusion 시리즈의 세 번째 버전을 대표하며, 이전 버전 및 DALL·E 3, Midjourney v6, Ideogram v1과 같은 다른 모델에 비해 향상된 정확도, 프롬프트의 미묘한 차이를 잘 반영하며, 뛰어난 시각적 미학을 제공합니다.
3. Stable Diffusion 3 모델#
Stable Diffusion 3는 서로 다른 요구 사항과 계산 능력을 충족하는 세 가지 모델을 제공합니다:
3.1. Stable Diffusion 3 Medium#
🌟🌟🌟 이 워크플로우에 직접 통합됨 🌟🌟🌟
- 파라미터: 20억
- 주요 기능:
- 고품질의 사실적인 이미지
- 복잡한 프롬프트에 대한 고급 이해력
- 뛰어난 타이포그래피 기능
- 자원 효율적이며 소비자 GPU에 적합
- 소규모 데이터셋으로 세부 조정에 적합
3.2. Stable Diffusion 3 Large#
Stability AI Developer Platform API를 통해 이용 가능
- 파라미터: 80억
- 주요 기능:
- 향상된 이미지 품질과 세부 사항
- 복잡한 프롬프트 및 스타일 처리 능력 향상
- 고해상도 및 충실도가 필요한 전문 프로젝트에 이상적
3.3. Stable Diffusion 3 Large Turbo#
Stability AI Developer Platform API를 통해 이용 가능
- 파라미터: 80억 (최적화된 추론 시간과 함께)
- 주요 기능:
- SD3 Large와 동일한 높은 성능
- 빠른 추론으로 실시간 애플리케이션 및 신속한 프로토타이핑에 적합
4. Stable Diffusion 3의 기술 아키텍처#
Stable Diffusion 3의 핵심은 Multimodal Diffusion Transformer (MMDiT) 아키텍처입니다. 이 혁신적인 프레임워크는 모델이 텍스트 및 시각적 정보를 처리하고 통합하는 방식을 향상시킵니다. 이전 버전이 이미지 및 텍스트 처리를 위해 단일 신경망 가중치 집합을 사용한 것과 달리, Stable Diffusion 3는 각 모달리티에 대해 별도의 가중치 집합을 사용합니다. 이 분리는 텍스트와 이미지 데이터를 더 전문적으로 처리할 수 있게 하여 생성된 이미지에서 텍스트 이해력과 철자 정확도를 향상시킵니다.
4.1. MMDiT 아키텍처의 구성 요소#
- 텍스트 임베더: Stable Diffusion 3는 텍스트를 AI가 이해하고 처리할 수 있는 형식으로 변환하기 위해 두 개의 CLIP 모델과 T5를 포함한 세 개의 텍스트 임베딩 모델 조합을 사용합니다.
- 이미지 인코더: 이미지를 AI가 조작하고 새로운 시각적 콘텐츠를 생성할 수 있는 형태로 변환하는 향상된 오토인코딩 모델을 사용합니다.
- 이중 트랜스포머 접근법: 이 아키텍처는 텍스트와 이미지를 위한 두 개의 독립적인 트랜스포머를 특징으로 하며, 이들은 독립적으로 작동하지만 주의 연산을 위해 상호 연결됩니다. 이 설정은 두 모달리티가 서로 직접 영향을 미치도록 하여 텍스트 입력과 이미지 출력 간의 일관성을 향상시킵니다.
5. Stable Diffusion 3의 새로운 기능과 개선 사항#
- 프롬프트 준수: SD3는 복잡한 장면이나 여러 주제를 포함하는 사용자 프롬프트의 세부 사항을 충실히 따르는 데 탁월합니다. 이 정밀한 이해력과 세부 프롬프트 렌더링 능력 덕분에 DALL·E 3, Midjourney v6, Ideogram v1과 같은 다른 주요 모델을 능가하며, 주어진 지침을 엄격히 준수해야 하는 프로젝트에 매우 신뢰할 수 있습니다.
- 이미지 내 텍스트: 고급 Multimodal Diffusion Transformer (MMDiT) 아키텍처를 통해 SD3는 이미지 내 텍스트의 명확성과 가독성을 크게 향상시킵니다. 이미지 및 언어 데이터 처리를 위한 별도의 가중치 집합을 사용함으로써 모델은 텍스트 이해력과 철자 정확도를 크게 향상시킵니다. 이것은 텍스트-이미지 AI 응용 프로그램에서 흔히 발생하는 문제를 해결한 중요한 개선 사항입니다.
- 시각적 품질: SD3는 경쟁 모델이 생성한 이미지의 시각적 품질을 뛰어넘을 뿐만 아니라, 프롬프트에 대한 높은 충실도를 유지합니다. 모델의 텍스트 설명 해석 및 시각화 능력이 정제되어 생성된 이미지는 미적으로 뛰어나고, 사용자들이 우수한 시각적 미학을 추구할 때 최선의 선택이 됩니다.

모델에 대한 자세한 내용은 Stable Diffusion 3의 연구 논문을 참조하세요.








