
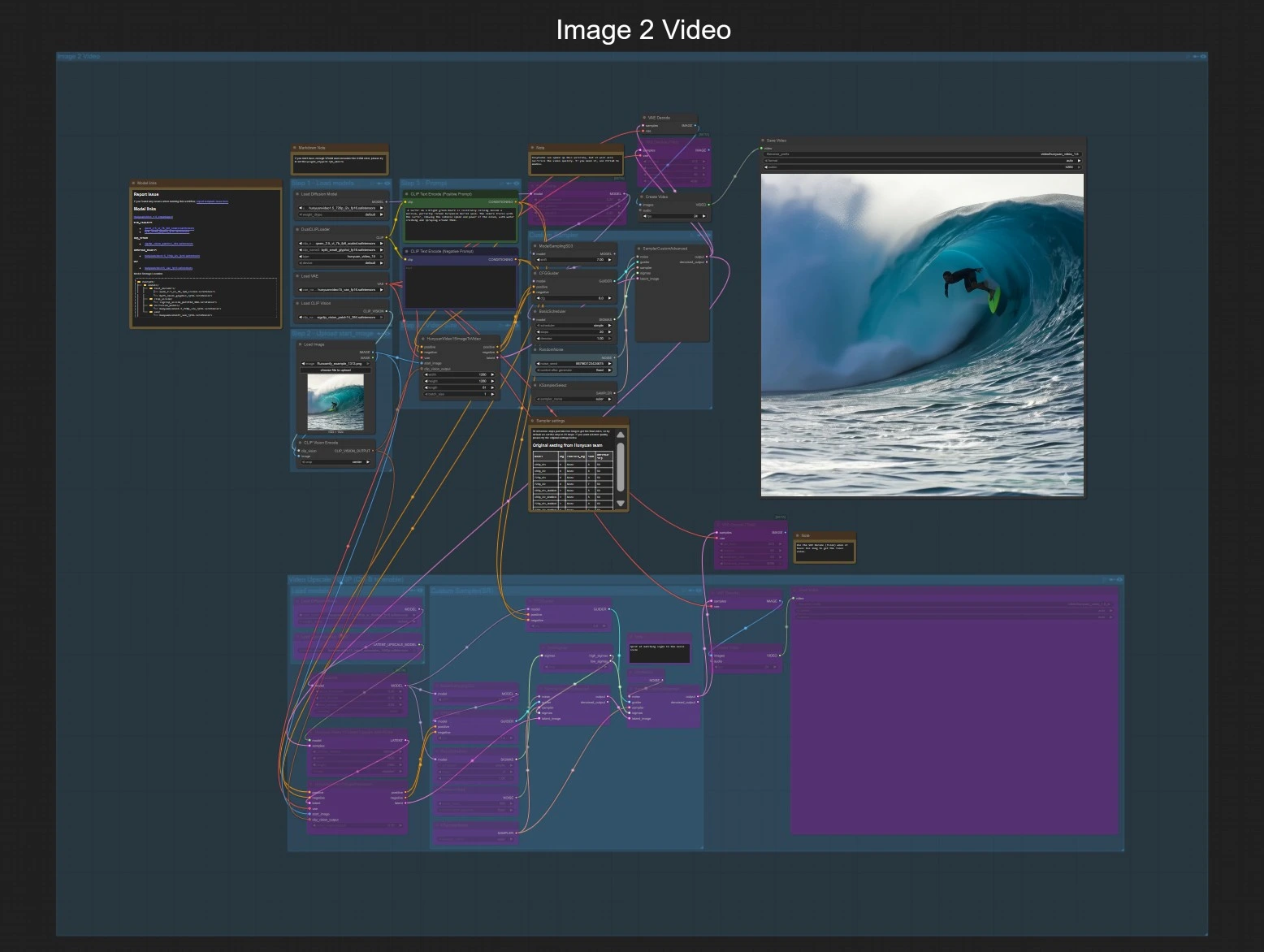
Hunyuan Video 1.5 ComfyUI 워크플로우: 빠른 텍스트-비디오 및 이미지-비디오 1080p 슈퍼 해상도#
이 워크플로우는 Hunyuan Video 1.5를 ComfyUI에 포함시켜 소비자 GPU에서 빠르고 일관된 비디오 생성을 제공합니다. 텍스트-비디오 및 이미지-비디오 모두를 지원하며, 전용 잠재 업샘플러와 증류된 슈퍼 해상도 모델을 사용하여 1080p로 업스케일링합니다. 내부적으로, Hunyuan Video 1.5는 Diffusion Transformer를 3D causal VAE와 선택적 슬라이딩-타일 주의 전략과 결합하여 품질, 모션 충실도, 속도의 균형을 맞춥니다.
창작자, 제품 팀, 연구자들은 이 ComfyUI Hunyuan Video 1.5 워크플로우를 사용하여 프롬프트 또는 단일 정지 이미지에서 빠르게 반복 작업을 수행하고, 필요 시 720p로 미리 보고, 선명한 1080p 출력으로 마무리할 수 있습니다.
Comfyui Hunyuan Video 1.5 워크플로우의 주요 모델#
- HunyuanVideo 1.5 720p 이미지-비디오 UNet. 시작 이미지에서 모션 및 시간적 일관성을 생성합니다. 가중치는 Hugging Face Comfy-Org/HunyuanVideo_1.5_repackaged에 있는 Comfy-Org 재패키지에 제공됩니다.
- HunyuanVideo 1.5 720p 텍스트-비디오 UNet. 동일한 핵심 아키텍처를 사용하여 텍스트 프롬프트에서 직접 비디오를 생성하며, 프롬프트 우선 워크플로우에 맞게 조정되었습니다. 위의 재패키지 저장소를 참조하세요.
- HunyuanVideo 1.5 1080p 슈퍼 해상도 UNet (증류됨). 모션 및 장면 구조를 유지하면서 720p 잠재를 더 높은 세부 사항으로 정제합니다. 동일한 재패키지에 포함되어 있습니다.
- HunyuanVideo 1.5 3D VAE. 효율적인 생성 및 타일 디코딩을 위한 비디오 잠재 인코딩 및 디코딩.
- HunyuanVideo 1.5 Latent Upsampler 1080p. SR 정제를 위한 1920×1080으로 잠재 시퀀스를 리스케일하여 속도와 메모리 효율성을 제공합니다.
- Qwen 2.5 VL 7B 텍스트 인코더와 ByT5 소형 텍스트 인코더. 다양한 프롬프트에 대한 견고한 지침 따르기 및 토큰화를 제공하며, 이 워크플로우를 위해 Hugging Face 번들에 재패키지되었습니다. ByT5의 원본 모델 카드: google/byt5-small.
- SigCLIP Vision (ViT-L/14, 384). 시작 이미지에서 고품질 시각적 특징을 추출하여 이미지-비디오 조건을 안내합니다: Comfy-Org/sigclip_vision_384.
Comfyui Hunyuan Video 1.5 워크플로우 사용 방법#
이 그래프는 동일한 내보내기 및 선택적 1080p 마무리 단계를 공유하는 두 개의 독립 경로를 노출합니다. 이미지-비디오 또는 텍스트-비디오 중 하나를 선택한 다음 선택적으로 1080p 그룹을 활성화하여 마무리합니다.
이미지-비디오#
Step 1 — 모델 로드 로더는 Hunyuan Video 1.5 UNet을 이미지-비디오, 3D VAE, 이중 텍스트 인코더 및 SigCLIP 비전을 가져옵니다. 이로써 워크플로우가 단일 시작 이미지와 프롬프트를 수용할 준비가 됩니다. 사용자는 모델이 사용 가능함을 확인하는 것 외에 다른 조치가 필요하지 않습니다.
Step 2 — 시작 이미지 업로드 LoadImage (#80)에서 깨끗하고 잘 노출된 이미지를 제공하세요. 그래프는 이 이미지를 CLIPVisionEncode (#79)로 인코딩하여 Hunyuan Video 1.5가 모션과 스타일을 참조에 고정할 수 있게 합니다. 잘라내거나 패딩을 줄이기 위해 대상 해상도와 대략적으로 일치하는 이미지를 선호하세요.
Step 3 — 프롬프트 CLIP Text Encode (Positive Prompt) (#44)에서 설명을 작성하세요. 부정적 프롬프트 CLIP Text Encode (Negative Prompt) (#93)를 사용하여 원치 않는 아티팩트나 스타일을 피하세요. 주제, 모션, 카메라 동작에 대해 간결하지만 구체적으로 프롬프트를 유지하세요.
Step 4 — 비디오 크기 및 지속 시간 HunyuanVideo15ImageToVideo (#78)에서 공간 해상도와 합성할 프레임 수를 설정하세요. 긴 시퀀스는 더 많은 VRAM과 시간이 필요하므로, 모션이 마음에 들면 더 짧게 시작하여 확장하세요.
Custom sampling 샘플러 스택 (ModelSamplingSD3 (#130), CFGGuider (#129), BasicScheduler (#126), KSamplerSelect (#128), RandomNoise (#127), SamplerCustomAdvanced (#125))은 안내 강도, 단계, 샘플러 유형, 씨드를 제어합니다. 더 많은 세부 사항과 안정성을 위해 단계를 높이고, 프롬프트를 반복할 때 결과를 재현하기 위해 고정 씨드를 사용하세요.
Preview and save 잠재 시퀀스는 VAEDecode (#8)로 디코딩되고, CreateVideo (#101)로 24 fps 비디오로 구성되어 SaveVideo (#102)로 저장됩니다. 이는 검토할 준비가 된 빠른 720p 미리보기를 제공합니다.
1080p 마무리 (선택 사항) "Video Upscale 1080P" 그룹을 토글하여 마무리 체인을 활성화하세요. 잠재 업샘플러는 1920×1080으로 확장되고, 증류된 슈퍼 해상도 UNet이 두 단계로 세부 사항을 정제합니다. VAEDecodeTiled와 두 번째 CreateVideo/SaveVideo 쌍이 1080p 결과를 내보냅니다.
텍스트-비디오#
Step 1 — 모델 로드 로더는 Hunyuan Video 1.5 720p 텍스트-비디오 UNet, 3D VAE, 이중 텍스트 인코더를 가져옵니다. 이 경로에는 시작 이미지가 필요하지 않습니다.
Step 3 — 프롬프트 양성 인코더 CLIP Text Encode (Positive Prompt) (#149)에 설명을 입력하고, CLIP Text Encode (Negative Prompt) (#155)에 부정적 프롬프트를 선택적으로 추가하세요. 장면, 주제, 모션, 카메라를 설명하며 구체적인 언어를 사용하세요.
Step 4 — 비디오 크기 및 지속 시간 EmptyHunyuanVideo15Latent (#183)는 선택한 너비, 높이, 프레임 수로 초기 잠재를 할당합니다. 이를 사용하여 비디오의 길이와 크기를 설정하세요.
Custom sampling ModelSamplingSD3 (#165), CFGGuider (#164), BasicScheduler (#161), KSamplerSelect (#163), RandomNoise (#162), SamplerCustomAdvanced (#166)는 노이즈를 텍스트로 안내된 일관된 비디오로 변환합니다. 속도를 충실도와 교환하기 위해 단계와 지침을 조정하고, 실행을 비교 가능하게 하려면 씨드를 고정하세요.
Preview and save 디코딩된 프레임은 CreateVideo (#168)로 조립되고 SaveVideo (#167)로 저장되어 24 fps에서 빠른 720p 리뷰를 제공합니다.
1080p 마무리 (선택 사항) "Video Upscale 1080P" 그룹을 활성화하여 잠재를 1080p로 업스케일하고 증류된 SR UNet으로 정제하세요. 두 단계 샘플링은 모션을 유지하면서 선명도를 향상시킵니다. 타일 디코더와 두 번째 저장 단계가 최종 1080p 비디오를 내보냅니다.
Comfyui Hunyuan Video 1.5 워크플로우의 주요 노드#
HunyuanVideo15ImageToVideo (#78) 시작 이미지와 프롬프트를 조건으로 비디오를 생성합니다. 해상도와 총 프레임을 조정하여 창의적 목표에 맞추세요. 더 높은 해상도와 긴 클립은 VRAM과 시간을 증가시킵니다. 이 노드는 샘플링 전에 CLIP-Vision 기능과 텍스트 지침을 융합하여 이미지-비디오 품질에 중심적입니다.
EmptyHunyuanVideo15Latent (#183) 텍스트-비디오를 위한 잠재 그리드를 너비, 높이, 프레임 수로 초기화합니다. 이를 사용하여 시퀀스 길이를 미리 정의하여 스케줄러와 샘플러가 안정적인 디노이징 궤적을 계획할 수 있습니다. 추가 패딩을 피하기 위해 의도한 출력과 일관된 종횡비를 유지하세요.
CFGGuider (#129) 분류기-프리 지침 강도를 설정하여 프롬프트 준수와 자연스러움의 균형을 맞춥니다. 지침을 증가시켜 프롬프트를 더 엄격하게 따르고, 과포화 및 깜박임을 줄이기 위해 낮추세요. 기본 생성 중에는 중간값을 사용하고, 슈퍼 해상도 정제에는 낮은 지침을 사용하세요.
BasicScheduler (#126) 디노이징 단계 수와 일정을 제어합니다. 더 많은 단계는 일반적으로 더 나은 세부 사항과 안정성을 의미하지만 렌더링 시간이 길어집니다. 최상의 결과를 위해 단계 수를 샘플러 선택과 짝지어 사용하세요; 이 워크플로우는 빠르고 일반적인 용도의 샘플러를 기본값으로 설정합니다.
SamplerCustomAdvanced (#125) 선택한 샘플러와 지침으로 디노이징 루프를 실행합니다. 1080p 마무리 체인에서는 SplitSigmas로 나뉘어 처음에는 높은 노이즈에서 구조를 설정한 다음 낮은 노이즈의 세부 사항을 정제합니다. 단계와 지침을 조정하면서 씨드를 고정하여 출력을 신뢰할 수 있도록 비교하세요.
HunyuanVideo15LatentUpscaleWithModel (#109) 재패키지된 가중치에서 전용 업샘플러를 사용하여 잠재 시퀀스를 1920×1080으로 리스케일합니다. 잠재 공간에서의 업스케일링은 픽셀 공간 리사이징보다 빠르고 메모리 친화적이며, 증류된 SR 모델이 세부 사항을 추가할 수 있는 무대를 설정합니다. 더 큰 대상은 더 많은 VRAM을 요구합니다; 최상의 처리량을 위해 16:9를 유지하세요.
HunyuanVideo15SuperResolution (#113) Hunyuan Video 1.5 번들에서 1080p SR 증류 UNet으로 업스케일된 잠재를 정제하며, 일관성을 위해 시작 이미지와 CLIP-Vision 큐를 선택적으로 사용합니다. 이는 모션을 유지하면서 선명한 텍스처와 선 작업을 추가합니다. SR 가중치는 Comfy-Org/HunyuanVideo_1.5_repackaged에서 사용 가능합니다.
EasyCache (#116) 미리보기 반복을 가속화하기 위해 중간 모델 상태를 캐시합니다. 더 빠른 전환이 필요할 때 활성화하고, 최종 패스에서 최대 품질을 원할 때 비활성화하세요. 동일한 해상도와 지속 시간으로 프롬프트를 반복할 때 특히 유용합니다.
선택적 추가 기능#
- 프롬프트를 구체적으로 유지하세요. 주제, 모션 동사, 카메라 움직임을 설명하세요. 반복적으로 나타나는 아티팩트를 억제하기 위해 짧은 부정적 프롬프트를 사용하세요.
- 이미지-비디오에 깨끗하고 고대비의 시작 이미지를 선호하세요. 패딩을 최소화하기 위해 대상 해상도와 종횡비를 일치시키세요.
- 속도를 위해, 더 짧은 지속 시간과 720p에서 반복하세요; 최종 실행에만 1080p 그룹을 켜세요.
- VRAM이 부족한 경우 타일 VAE 디코드를 토글하고 모델 로더에서 노출된 낮은 정밀도 설정으로 가중치를 로드하는 것을 고려하세요.
- 단계를 조정하고, 지침을 조정하고, 프롬프트를 수정할 때 씨드를 고정하여 실행 간 변경을 측정 가능하게 만드세요.
감사의 글#
이 워크플로우는 다음 작업 및 리소스를 구현하고 구축합니다. 우리는 Comfy.org의 Hunyuan Video 1.5 워크플로우 튜토리얼에 대한 기여와 유지 보수에 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하세요.
리소스#
- Hunyuan Video 1.5 소스
- 문서 / 릴리스 노트: Hunyuan Video 1.5 소스
참고: 참조된 모델, 데이터세트 및 코드는 해당 작성자 및 유지 관리자가 제공한 라이선스 및 약관에 따라 사용해야 합니다.