
ComfyUI를 위한 Fish Audio S2 TTS: 고품질 TTS, 음성 클로닝, 다중 화자 대화#
Fish Audio S2 TTS는 텍스트를 자연스러운 음성으로 변환하고, 짧은 참조 클립에서 음성을 클로닝하며, 다중 화자 대화를 생성하는 준비된 ComfyUI 워크플로우입니다. 이는 Fish Audio S2‑Pro 패밀리에 의해 구동되며, [excited], [whisper], [laughing]과 같은 감정 및 운율 태그를 통한 풍부한 스타일 제어를 지원합니다.
이 워크플로우는 ComfyUI 내에서 유연하고 표현력 있는 음성 합성을 원하는 크리에이터, 제품 팀, 개발자에게 이상적입니다. 빠른 전사 캡처를 위한 선택적 음성-텍스트 변환, 자동 언어 감지, fp8 및 sage_attention과 같은 효율적인 추론을 위한 여러 정밀도 선택을 포함합니다.
참고: 이 워크플로우는 2X Large 이상의 기계에서 실행하세요. 더 작은 인스턴스는 메모리 부족(OOM)이 발생할 수 있습니다.
Comfyui Fish Audio S2 TTS 워크플로우의 주요 모델#
- Fish Audio S2‑Pro — 단일 화자 TTS, 음성 클로닝 및 다중 화자 대화에 사용되는 핵심 생성 텍스트-음성 변환 모델입니다. 광범위한 스타일 토큰과 다국어 합성을 지원하는 모델 카드이며, Fish‑Speech 프로젝트 repo의 일부입니다.
- Fish Audio S2‑Pro FP8 — VRAM 필요성을 줄이면서 품질 손실이 최소화된 메모리 효율적인 S2‑Pro 변형으로, 제한된 GPU에 권장됩니다. 모델 카드.
- OpenAI Whisper large‑v3 — 음성 클로닝 프롬프트를 준비할 때 참조 오디오를 자동으로 전사하는 선택적 음성-텍스트 모델입니다. repo.
Comfyui Fish Audio S2 TTS 워크플로우 사용 방법#
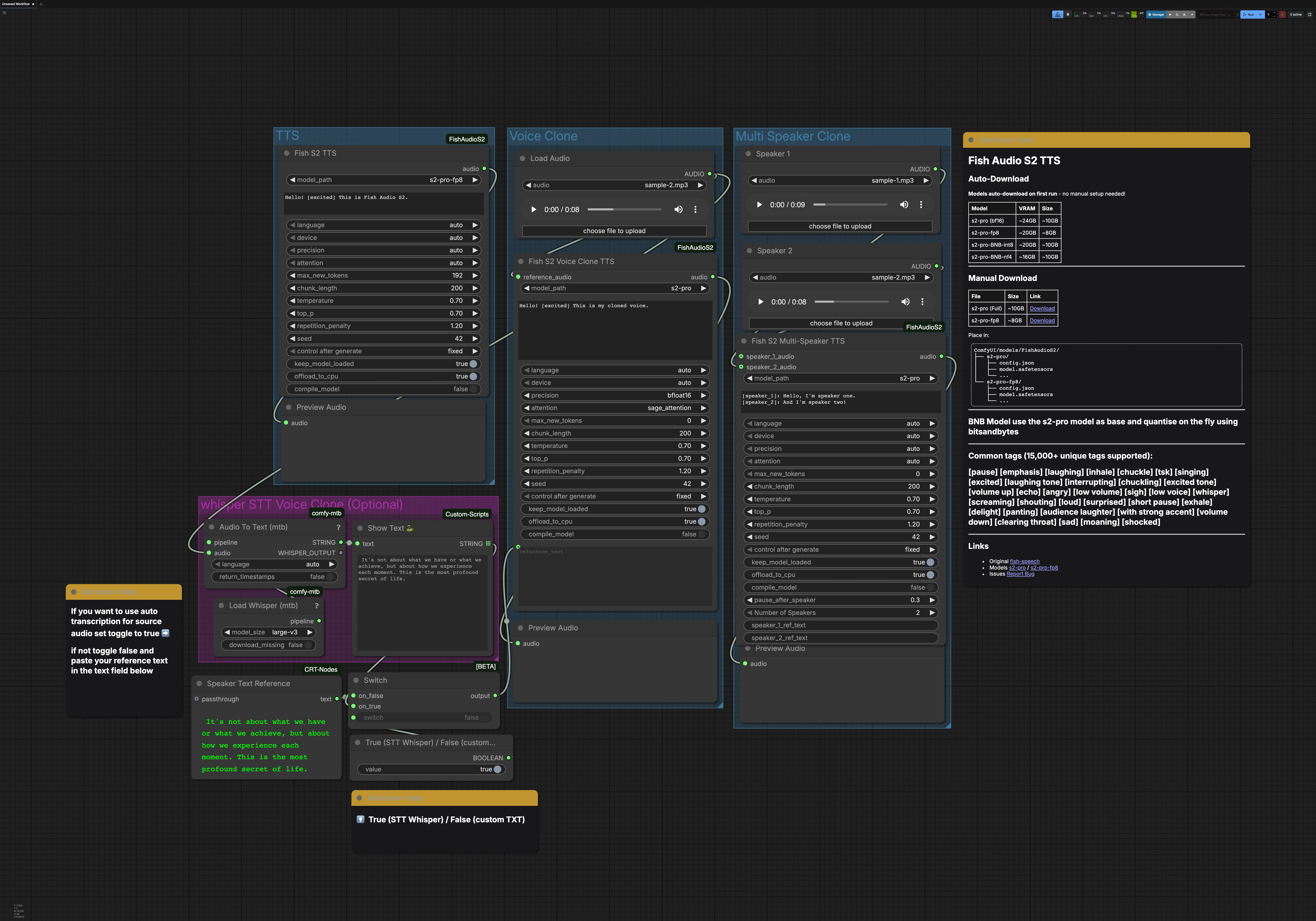
이 워크플로우는 독립적으로 실행할 수 있는 세 가지 주요 경로를 포함합니다: TTS, 음성 클론, 다중 화자 클론. 선택적 Whisper STT 그룹은 음성 클로닝을 위한 전사를 생성할 수 있습니다. 각 경로는 오디오 미리보기로 끝나므로 결과를 빠르게 모니터링할 수 있습니다.
TTS 그룹#
FishS2TTS (#42) 노드는 Fish Audio S2 TTS를 사용하여 직접 텍스트-음성을 수행합니다. 노드의 텍스트 상자에 스크립트를 입력하고 [excited], [pause], [whisper]와 같은 스타일 태그를 추가하여 감정과 속도를 조정하세요. 언어 감지는 자동으로 이루어지므로 대상 언어로 작성하면 모델이 적응합니다. 예를 들어 fp8과 같은 가벼운 로드를 위해 GPU 메모리에 맞는 S2‑Pro 변형을 선택하세요. 출력은 즉시 청취를 위한 PreviewAudio로 라우팅됩니다.
음성 클론 그룹#
LoadAudio를 사용하여 대상 음성의 짧고 깨끗한 참조 클립을 제공한 다음 FishS2VoiceCloneTTS (#14)로 라우팅하세요. 원하는 말투와 일치하는 전사를 제공하세요. 정확한 텍스트는 모델이 리듬과 억양을 유지하는 데 도움이 됩니다. 참조 텍스트는 STT 그룹에서 가져오거나 직접 입력할 수 있으며, 스타일 태그를 추가하여 감정과 전달을 세밀하게 조정할 수 있습니다. 정밀도 및 주의 백엔드 선택은 긴 줄에 대한 속도, 메모리 및 안정성을 균형 있게 합니다. 합성된 클론은 빠르게 반복할 수 있도록 PreviewAudio로 전송됩니다.
다중 화자 클론 그룹#
LoadAudio 노드를 사용하여 각 화자에 대한 참조 클립을 로드한 다음 FishS2MultiSpeakerTTS (#41)에 연결하세요. 각 턴을 [speaker_1], [speaker_2] 등으로 레이블링한 대화 스크립트를 제공하세요. 이 템플릿은 기본적으로 두 명의 화자를 포함하며, 노드 구성에 따라 최대 여덟 개의 개별 음성을 지원합니다. 내러티브 산문, 태그 및 대화를 혼합하여 각 캐릭터의 흐름과 감정을 제어할 수 있습니다. 최종 믹스가 미리 보기가 가능하므로 타이밍과 명료성을 확인할 수 있습니다.
음성 클로닝용 Whisper STT (선택 사항)#
Load Whisper (mtb) (#6)와 large‑v3는 Audio To Text (mtb) (#7)를 통해 참조 클립을 자동으로 전사합니다. 인식된 텍스트는 ShowText|pysssss (#8)에 표시됩니다. ComfySwitchNode (#34)와 부울 제어로 구축된 작은 토글은 STT 출력(true) 또는 Text Box line spot (#31)에서 입력한 텍스트(false)를 선택할 수 있게 해줍니다. 이는 빠른 기본 전사나 클로닝을 위한 정확한 프롬프트를 제작할 때 유용합니다.
Comfyui Fish Audio S2 TTS 워크플로우의 주요 노드#
FishS2TTS (#42)#
선택적 스타일 태그와 자동 언어 감지를 통해 텍스트에서 단일 화자 음성을 생성합니다. 하드웨어에 맞게 모델 변형을 조정하세요. 예를 들어 VRAM이 부족할 때는 fp8을 선택하세요. 반복 가능한 테이크를 위해 시드 컨트롤을 사용하고 대체 전달을 탐색할 때 작은 변화를 도입하세요. 긴 스크립트의 경우 안정성을 최적화한 주의 백엔드를 선택하세요.
FishS2VoiceCloneTTS (#14)#
reference_audio와 reference_text를 조건으로 음성을 클로닝합니다. 일관된 톤과 의도된 리듬을 반영하는 전사를 통해 더 나은 결과를 얻을 수 있습니다. 스타일 태그는 최종 텍스트에 혼합하여 분위기를 조정할 수 있지만 정체성을 손상시키지 않습니다. 정밀도와 주의 설정은 긴 줄에 대한 품질과 메모리를 균형 있게 합니다.
FishS2MultiSpeakerTTS (#41)#
각 화자의 참조 오디오와 대화를 [speaker_n] 레이블로 표시하여 다중 화자 대화를 합성합니다. 필요에 따라 화자 수를 늘리고 강한 분리를 위해 개별 클립을 할당하세요. 혼합을 결정론적으로 만들기 위해 시드를 사용하여 멀티 테이크 장면을 렌더링하세요.
선택적 추가 기능#
- 스타일 태그를 신중하게 사용하세요. [excited], [whisper], [emphasis], [pause]와 같은 몇 가지 태그로 시작하고 명확성을 위해 필요에 따라 추가하세요.
- 음성 클로닝의 경우 참조의 시작과 끝에서 침묵을 잘라내고 배경 소음을 피하여 음색을 보존하세요.
- GPU 메모리가 제한된 경우, S2‑Pro fp8 또는 런타임 양자화 옵션을 선호하세요. 최대 충실도를 위해서는 더 높은 정밀도를 사용하세요.
- 구두점이 중요합니다. 쉼표와 마침표는 구문을 개선하며, 절 경계에 태그를 배치하면 보다 자연스럽게 들립니다.
- 다중 화자 스크립트의 경우, 각 발화를 한 줄에 유지하고 항상 올바른 [speaker_n] 레이블로 접두사를 붙여 분리를 유지하세요.
리소스:
- Fish Audio S2‑Pro 모델 카드: Hugging Face
- S2‑Pro fp8 변형: Hugging Face
- Fish‑Speech 프로젝트: GitHub
- ComfyUI Fish Audio S2 노드: GitHub
- Whisper large‑v3: GitHub
감사의 말#
이 워크플로우는 다음 작품과 리소스를 구현하고 기반으로 합니다. ComfyUI-FishAudioS2 Custom Nodes를 위한 Saganaki22와 S2-Pro Model을 위한 Fish Audio의 기여와 유지보수에 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 리포지토리를 참조하세요.
리소스#
- Saganaki22/ComfyUI-FishAudioS2 Custom Nodes
- GitHub: Saganaki22/ComfyUI-FishAudioS2
- Fish Audio/S2-Pro Model
- Hugging Face: fishaudio/s2-pro
참고: 참조된 모델, 데이터세트 및 코드의 사용은 해당 작성자 및 유지보수자가 제공한 라이선스 및 조건에 따릅니다.

