
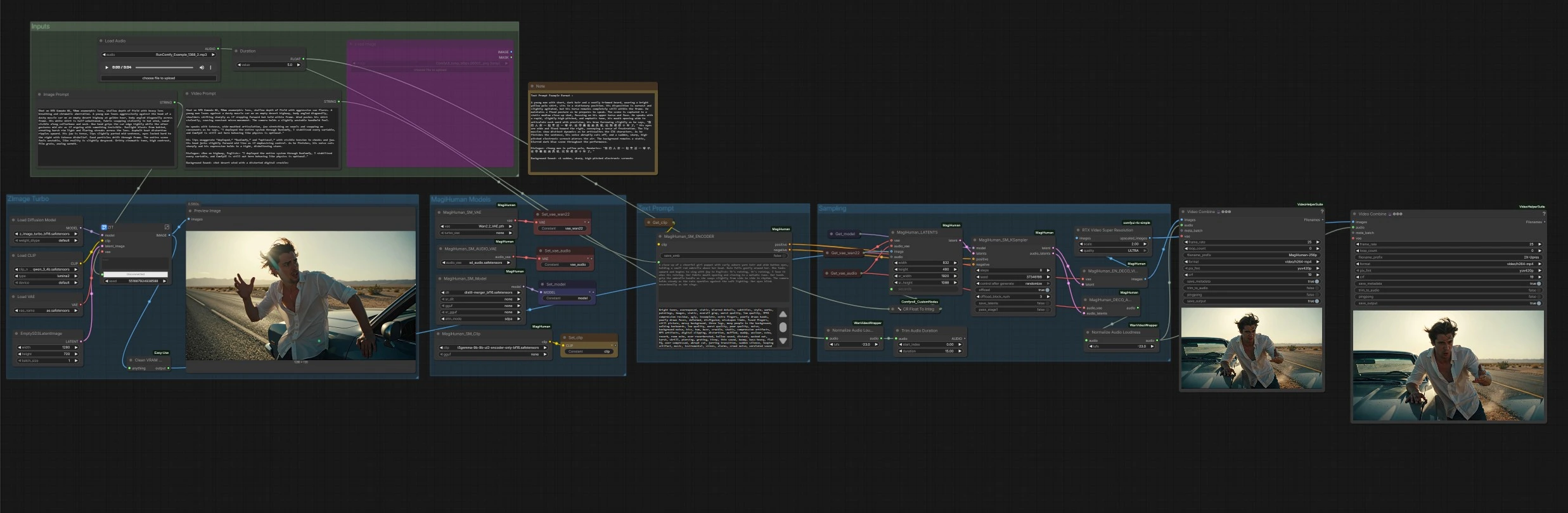
daVinci-MagiHuman ComfyUI를 위한 디지털 인간 워크플로우#
이 ComfyUI 워크플로우는 daVinci-MagiHuman을 중심으로 전체 텍스트-비디오 파이프라인을 구축하여 동기화된 음성, 입 움직임, 표현 및 신체 미세 운동을 통해 현실적인 말하는 디지털 인간을 생성합니다. 설명 프롬프트에서 깨끗한 오디오와 함께 MP4까지 빠르고 클릭 한 번에 경로를 원하는 제작자를 위해 설계되었습니다. 그래프는 새로 생성된 초상화나 제공된 참조 이미지를 애니메이션화한 다음, 비디오와 음성을 함께 렌더링하고 선택적으로 업스케일링 및 자동 오디오 음량 정규화를 마무리합니다.
daVinci-MagiHuman 코어는 단일 스트림 Transformer를 사용하여 하나의 프롬프트에서 비디오와 오디오를 공동 생성하며, 이는 짧은 클립에서도 타이밍과 립싱크 충실도를 유지하는 데 도움이 됩니다. 이 ComfyUI 구현은 컨트롤을 간단하게 유지합니다: 이미지를 정의하는 이미지 프롬프트, 성능과 대화를 정의하는 비디오 프롬프트를 작성하고 클립 지속 시간을 설정한 후 실행합니다.
ComfyUI daVinci-MagiHuman 워크플로우의 주요 모델#
- daVinci-MagiHuman (15B 단일 스트림 오디오-비디오 생성기). 역할: 텍스트에서 비디오 프레임과 음성을 공동으로 생성하면서 시간적 일관성과 립싱크를 유지합니다. 참조: GitHub, arXiv, Hugging Face.
- T5Gemma 9B 인코더 (UL2-적응됨). 역할: 비디오 프롬프트를 daVinci-MagiHuman의 움직임, 전달 및 스타일을 조정하는 풍부한 조건으로 인코딩합니다. 참조: Hugging Face.
- Z-Image Turbo 확산 모델. 역할: 애니메이션의 정체성/참조로 사용할 고품질 정지 초상화를 이미지 프롬프트에서 빠르게 생성합니다. 참조: Hugging Face (z_image_turbo), Hugging Face (z_image).
- Qwen 3 4B 텍스트 인코더 for Z-Image Turbo. 역할: 초상화 생성을 안내하기 위해 이미지 프롬프트를 구문 분석합니다. 참조: Hugging Face file.
- Wan 2.2 VAE. 역할: MagiHuman 비디오 잠재 변수를 강한 시간 일관성을 가진 RGB 프레임으로 디코딩합니다. 참조: GitHub, Hugging Face 예제 모델.
- Audio VAE (sd_audio). 역할: MagiHuman 오디오 잠재 변수를 파형으로 디코딩하여 최종 비디오와 함께 혼합합니다. 참조: MagiHuman을 위한 맞춤형 노드 번들 GitHub.
- RTX Video Super Resolution (선택 사항). 역할: 최종 인코딩 전에 디코딩된 프레임을 업스케일하여 인식된 선명도를 높이고 압축 아티팩트를 줄입니다. 참조: ComfyUI 래퍼 GitHub.
ComfyUI daVinci-MagiHuman 워크플로우 사용 방법#
전체 흐름: Z-Image Turbo 그룹은 이미지 프롬프트에서 정체성 초상화를 생성합니다. MagiHuman Models 그룹은 daVinci-MagiHuman 체크포인트, 비디오 VAE 및 오디오 VAE를 로드하고 텍스트 인코더를 준비합니다. 텍스트 프롬프트 그룹은 비디오 프롬프트를 조건으로 변환합니다. 샘플링 그룹은 참조 이미지와 프롬프트를 결합하여 공동 비디오 및 오디오 잠재 변수를 생성한 다음, 둘 다 디코딩합니다. 마지막으로, 출력 단계는 프레임을 오디오와 혼합하여 MP4로 저장하며, 선택적으로 업스케일된 버전도 제공합니다.
입력#
이미지 프롬프트 및 비디오 프롬프트 텍스트 상자를 사용하여 외관과 성능을 설명하세요. 지속 시간 컨트롤은 클립 길이를 초 단위로 설정합니다. 오디오 구동 변형을 실험할 계획이라면 편의를 위해 오디오 로더가 있지만, 이 템플릿은 기본적으로 텍스트 구동 모드로 실행됩니다.
ZImage Turbo#
이 단계에서는 Z-Image Turbo UNet과 Qwen 3 4B 텍스트 인코더와 번들로 제공되는 VAE를 사용하여 이미지 프롬프트에서 단일 참조 초상화를 렌더링합니다. 빠르고 깨끗한 정체성 생성과 시네마틱 외관을 위해 최적화되었습니다. 결과는 미리보기로 표시된 후 애니메이션을 위한 참조 이미지로 전달됩니다. 이미 헤드샷이 있는 경우, 애니메이션 단계에 이미지를 직접 연결하여 이 단계를 생략할 수 있습니다.
MagiHuman Models#
여기서 그래프는 daVinci-MagiHuman 기본 또는 증류 체크포인트와 Wan 2.2 비디오 VAE, 오디오 VAE 및 T5Gemma 인코더를 로드합니다. 이는 텍스트 인코딩, 비디오 잠재 변수 및 오디오 잠재 변수를 단일 스트림 샘플링을 위해 정렬합니다. 환경에서 사용할 수 있는 대체 가중치가 있는 경우 교체할 수 있습니다.
Text Prompt#
귀하의 비디오 프롬프트는 긍정적 및 부정적인 조건으로 인코딩됩니다. 긍정적인 텍스트는 카메라 거리, 포즈, 언어, 전달 스타일 및 정확한 대화 내용을 설명해야 합니다. 부정적인 텍스트는 피해야 할 시각적 또는 오디오 결함을 나열할 수 있습니다. 인코더는 모션, 입 동적 및 음색을 형성하기 위해 샘플러에 두 가지 조건 세트를 공급합니다.
Sampling#
샘플러는 참조 이미지와 요청된 지속 시간에서 초기 잠재 시퀀스를 구축한 다음, daVinci-MagiHuman을 사용하여 동기화된 비디오 및 오디오 잠재 변수를 생성합니다. 유틸리티는 지속 시간을 안정적인 스케줄링을 위해 전체 초로 변환합니다. 샘플링이 완료되면 비디오 잠재 변수는 비디오 디코더로, 오디오 잠재 변수는 오디오 디코더로 이동합니다.
디코딩, 음량 및 내보내기#
비디오 잠재 변수는 Wan 2.2 VAE로 이미지 프레임으로 디코딩됩니다. 오디오 잠재 변수는 음성으로 디코딩된 후 방송 친화적인 음량으로 정규화되어 최종 MP4가 장치 간에 일관되게 재생됩니다. 두 가지 내보내기가 생성됩니다: 기본 렌더링과 RTX Video Super Resolution을 사용한 선택적 업스케일드 렌더링. 둘 다 오디오와 함께 MP4로 혼합되어 명확한 파일명 접두사와 함께 저장됩니다.
ComfyUI daVinci-MagiHuman 워크플로우의 주요 노드#
MagiHuman_LATENTS(#13)
비디오 및 선택적 오디오를 위한 공동 잠재 캔버스를 구축하며, 참조 이미지와 클립 길이를 가져옵니다. seconds를 조정하여 지속 시간을 설정하고 참조 이미지가 설명한 움직임에 잘 맞도록 잘 프레임되어 있는지 확인하세요. 기본 해상도가 높을수록 얼굴 충실도가 향상되지만 VRAM과 디코딩 시간이 증가합니다.
MagiHuman_SM_ENCODER(#95)
비디오 프롬프트를 샘플러를 위한 긍정적 및 부정적 조건으로 인코딩합니다. 정확한 음성을 따옴표로 묶어 입력하고 언어를 지정하여 입을 닫는 시간과 타이밍을 개선하세요. 부정적 필드에는 "자막", "정적", "방 에코"와 같은 아티팩트를 억제하기 위해 사용하세요.
MagiHuman_SM_KSampler(#9)
daVinci-MagiHuman 디노이징을 실행하여 비디오 및 음성 잠재 변수를 공동 생성합니다. seed는 재현성을 제어하며, steps와 내부 스케줄은 속도와 디테일 및 모션 안정성을 교환합니다. 정체성을 잃지 않고 변화를 원할 경우, seed를 변경하거나 프롬프트의 성능 부분을 약간 재구성하세요.
MagiHuman_EN_DECO_VIDEO(#5)
Wan 2.2 VAE로 비디오 잠재 변수를 RGB 프레임으로 디코딩하여 내보내기 또는 업스케일링을 위한 경로를 제공합니다. 가장 빠른 엔드 투 엔드 렌더링을 위해 이 경로를 사용하세요; 긴 클립이나 높은 해상도는 디코딩 시간을 선형적으로 증가시킵니다.
MagiHuman_DECO_AUDIO(#6)
오디오 잠재 변수를 파형으로 디코딩하고, 일관된 재생을 위해 음량 정규화를 거칩니다. 나중에 오디오 구동 생성으로 전환하려면 외부 오디오를 잠재 빌더에 연결하고 이 디코드 경로를 최종 혼합을 위해 유지하세요.
RTXVideoSuperResolution(#93)
가장자리 선명도를 높이고 울림을 줄이는 선택적 포스트 업스케일러입니다. 중간 강도로 사용하여 명확성을 개선하면서 시간적 깜박임을 도입하지 않도록 하세요.
선택적 추가 기능#
- 신뢰할 수 있는 립싱크를 위한 프롬프트 패턴: 화자 태그와 언어 및 인용된 대사를 포함하세요, 예를 들어 대화: <발표자, 영어>: "프로그램에 오신 것을 환영합니다." 전달, 샷 크기 및 카메라 안정성에 대한 간단한 설명을 추가하세요.
- 참조 초상화는 중간 근접 촬영으로 머리가 프레임 내부에 완전히 들어가도록 유지하세요. 타이트한 크롭은 턱과 뺨의 역동성을 위한 공간이 거의 남지 않습니다.
- 더 엄격한 타이밍이 필요한 경우, 선택한 지속 시간에 맞춰 스크립트를 다듬거나 확장하세요. 매우 짧은 클립에서 매우 긴 문장은 부자연스러운 발음을 강요할 수 있습니다.
- 이 템플릿은 프롬프트 전용 모드에서 실행됩니다. 오디오 구동 테스트를 위해서는 외부 오디오 파일을
MagiHuman_LATENTS(#13) 오디오 입력에 연결하고, 비디오 프롬프트를 표현보다는 말하는 내용으로 설명하도록 조정하세요.
감사의 말#
이 워크플로우는 다음 작업 및 리소스를 구현하고 기반으로 합니다. 우리는 daVinci-MagiHuman의 daVinci-MagiHuman 워크플로우 소스에 그들의 기여와 유지보수에 대해 감사드립니다. 권위 있는 세부 사항을 위해, 아래 링크된 원본 문서 및 저장소를 참조하십시오.
리소스#
- daVinci-MagiHuman/워크플로우 소스
- 문서 / 릴리스 노트: daVinci-MagiHuman 워크플로우 소스
참고: 참조된 모델, 데이터 세트 및 코드의 사용은 해당 작성자 및 유지보수자가 제공한 라이선스 및 조건에 따릅니다.
