
AI 비디오의 제어 가능한 애니메이션: WanVideo + TTM 모션 제어 워크플로우 for ComfyUI#
mickmumpitz의 이 워크플로우는 ComfyUI에서 교육이 필요 없는 모션 가이드 접근법을 사용하여 AI 비디오의 제어 가능한 애니메이션을 제공합니다. WanVideo의 이미지-비디오 확산과 Time-to-Move (TTM) 잠재적 가이드 및 영역 인식 마스크를 결합하여 피사체의 움직임을 지시하면서 정체성, 텍스처 및 장면 연속성을 유지할 수 있습니다.
비디오 플레이트 또는 두 개의 키프레임에서 시작하여 원하는 곳에 모션을 집중시키는 영역 마스크를 추가하고, 미세 조정 없이 궤적을 구동할 수 있습니다. 그 결과는 지시된 샷, 객체 모션 시퀀싱 및 맞춤형 창의적 편집에 적합한 정밀하고 반복 가능한 AI 비디오의 제어 가능한 애니메이션입니다.
Comfyui AI 비디오 워크플로우의 제어 가능한 애니메이션의 주요 모델#
- Wan2.2 I2V A14B (HIGH/LOW). 프롬프트와 시각적 참조에서 모션과 시간적 일관성을 합성하는 핵심 이미지-비디오 확산 모델입니다. 두 가지 변형은 서로 다른 모션 강도에 대한 충실도 (HIGH)와 민첩성 (LOW)을 균형 있게 조절합니다. 모델 파일은 Hugging Face의 커뮤니티 WanVideo 컬렉션에 호스팅됩니다. 예: Kijai의 WanVideo 분배. 링크: Kijai/WanVideo_comfy_fp8_scaled, Kijai/WanVideo_comfy
- Lightx2v I2V LoRA. Wan2.2와 함께 AI 비디오의 제어 가능한 애니메이션을 구성할 때 구조와 모션 일관성을 강화하는 경량 어댑터입니다. 강력한 모션 큐 하에서도 피사체의 기하학적 형태를 유지하는 데 도움을 줍니다. 링크: Kijai/WanVideo_comfy – Lightx2v LoRA
- Wan2.1 VAE. 프레임을 잠재적 요소로 인코딩하고 샘플러의 출력을 이미지로 디코딩하여 세부 사항을 희생하지 않습니다. 링크: Kijai/WanVideo_comfy – Wan2_1_VAE_bf16.safetensors
- UMT5-XXL 텍스트 인코더. 모션 큐와 함께 프롬프트 기반 제어를 위한 풍부한 텍스트 임베딩을 제공합니다. 링크: google/umt5-xxl, Kijai/WanVideo_comfy – encoder weights
- 비디오 마스크용 Segment Anything 모델. SAM3 및 SAM2는 프레임 전반에 영역 마스크를 생성하고 전파하여 중요한 곳에서 AI 비디오의 제어 가능한 애니메이션을 강화하는 영역 의존적 가이드를 가능하게 합니다. 링크: facebook/sam3, facebook/sam2
- Qwen-Image-Edit 2509 (선택사항). 애니메이션 전에 빠른 시작/종료 프레임 정리 또는 객체 제거를 위한 이미지 편집 기반과 라이트닝 LoRA. 링크: QuantStack/Qwen-Image-Edit-2509-GGUF, lightx2v/Qwen-Image-Lightning, Comfy-Org/Qwen-Image_ComfyUI
- Time-to-Move (TTM) 가이드. 이 워크플로우는 TTM 잠재적 요소를 통합하여 AI 비디오의 제어 가능한 애니메이션을 위한 궤적 제어를 교육 없이 주입합니다. 링크: time-to-move/TTM
Comfyui AI 비디오 워크플로우의 제어 가능한 애니메이션 사용법#
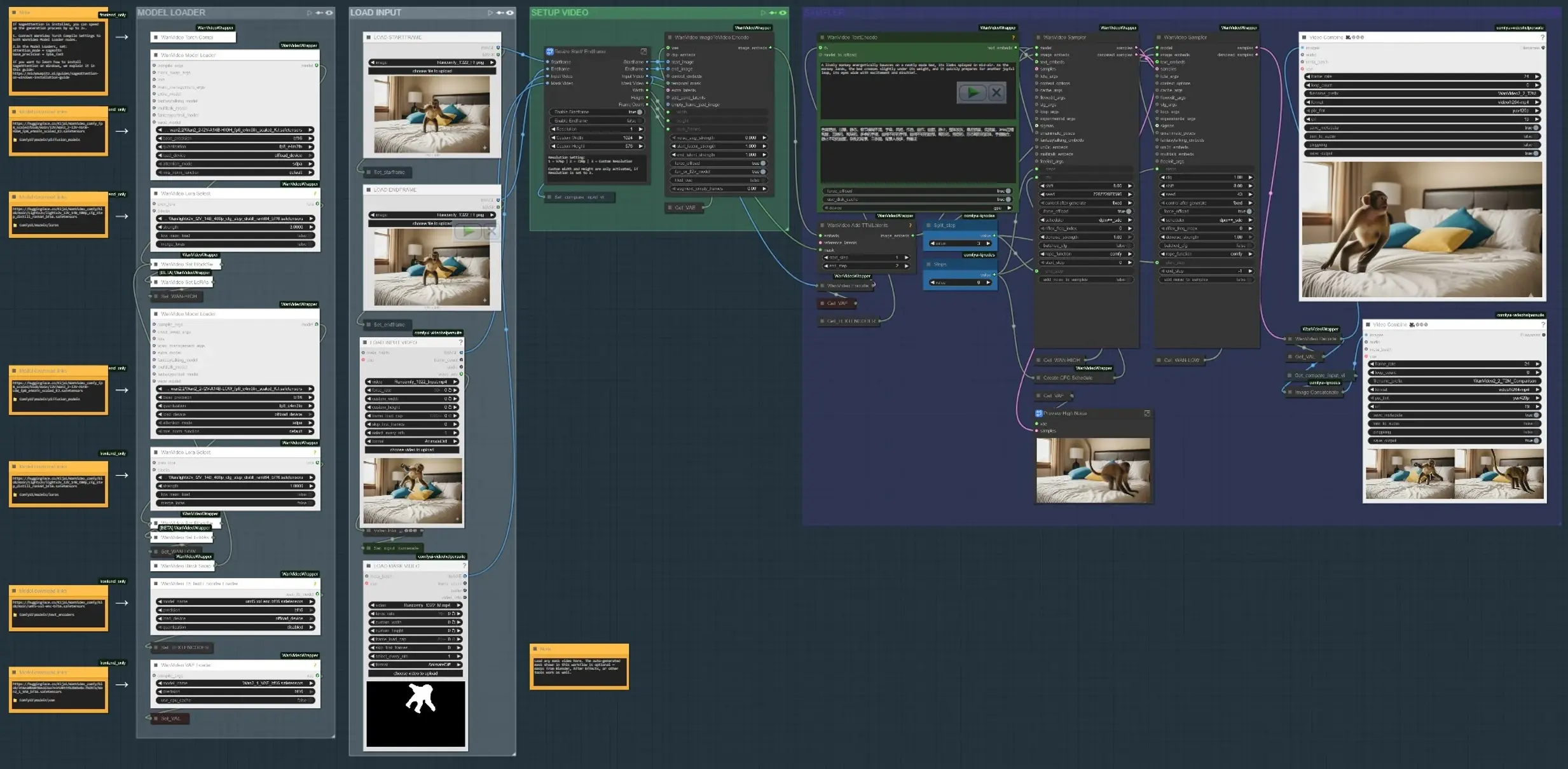
워크플로우는 네 가지 주요 단계로 진행됩니다: 입력 로드, 모션 발생 위치 정의, 텍스트 및 모션 큐 인코딩, 결과 합성 및 미리 보기. 아래 각 그룹은 그래프의 레이블이 붙은 섹션에 매핑됩니다.
- 입력 로드 “LOAD INPUT VIDEO” 그룹을 사용하여 플레이트나 참조 클립을 가져오거나 두 상태 사이에 모션을 구축하는 경우 시작 및 종료 키프레임을 로드하세요. “Resize Start/Endframe” 서브그래프는 차원을 표준화하고 시작 프레임 및 종료 프레임 게이팅을 선택적으로 활성화합니다. 나란히 비교기는 입력과 결과를 빠르게 검토할 수 있도록 보여주는 출력을 만듭니다 (
VHS_VideoCombine(#613)). - 모델 로더 “MODEL LOADER” 그룹은 Wan2.2 I2V (HIGH/LOW)를 설정하고 Lightx2v LoRA를 적용합니다. 블록 교환 경로는 샘플링 전에 좋은 충실도-모션 균형을 위해 변형을 혼합합니다. Wan VAE는 한 번 로드되고 인코딩/디코딩 전반에 걸쳐 공유됩니다. 텍스트 인코딩은 AI 비디오의 제어 가능한 애니메이션에서 강력한 프롬프트 조건화를 위해 UMT5-XXL을 사용합니다.
- SAM3/SAM2 마스크 대상 “SAM3 MASK SUBJECT” 또는 “SAM2 MASK SUBJECT”에서 참조 프레임을 클릭하고, 긍정적 및 부정적 포인트를 추가하며, 클립 전반에 마스크를 전파합니다. 이는 모션 편집을 선택한 대상 또는 영역으로 제한하는 시간적으로 일관된 마스크를 생성하여 영역 의존적 가이드를 가능하게 합니다. 또한 바이패스하여 자체 마스크 비디오를 로드할 수 있습니다; Blender/After Effects에서의 마스크는 아티스트가 그린 제어를 원할 때 잘 작동합니다.
- 시작 프레임/종료 프레임 준비 (선택 사항) “STARTFRAME – QWEN REMOVE” 및 “ENDFRAME – QWEN REMOVE” 그룹은 Qwen-Image-Edit를 사용하여 특정 프레임에 대한 선택적 정리 패스를 제공합니다. 리깅, 스틱 또는 플레이트 아티팩트를 제거하여 모션 큐를 오염시키지 않도록 사용하세요. 인페인팅은 편집을 전체 프레임으로 자르고 꿰매어 깨끗한 기반을 제공합니다.
- 텍스트 + 모션 인코딩 프롬프트는
WanVideoTextEncode(#605)에서 UMT5-XXL로 인코딩됩니다. 시작 프레임/종료 프레임 이미지는WanVideoImageToVideoEncode(#89)에서 비디오 잠재적 요소로 변환됩니다. TTM 모션 잠재적 요소와 선택적 시간적 마스크는WanVideoAddTTMLatents(#104)를 통해 병합되어 샘플러가 의미적 (텍스트) 및 궤적 큐를 모두 수신하도록 합니다. 이는 AI 비디오의 제어 가능한 애니메이션에 중심적입니다. - 샘플러 및 미리보기 Wan 샘플러 (
WanVideoSampler(#27) 및WanVideoSampler(#90))는 이중 시계 설정을 사용하여 잠재적 요소를 디노이즈합니다: 한 경로는 전역 역학을, 다른 경로는 지역 외관을 유지합니다. 단계 및 구성 가능한 CFG 일정은 모션 강도와 충실도 간의 균형을 형성합니다. 결과는 프레임으로 디코딩되고 비디오로 저장됩니다; 비교 출력은 AI 비디오의 제어 가능한 애니메이션이 브리프와 일치하는지 판단하는 데 도움이 됩니다.
Comfyui AI 비디오 워크플로우의 제어 가능한 애니메이션의 주요 노드#
WanVideoImageToVideoEncode(#89) 시작 프레임/종료 프레임 이미지를 모션 합성을 위한 비디오 잠재적 요소로 인코딩합니다. 기본 해상도 또는 프레임 수를 변경할 때만 조정하십시오; 입력과 일치하도록 맞춰야 스트레칭을 피할 수 있습니다. 마스크 비디오를 사용하는 경우, 그 치수가 인코딩된 잠재적 크기와 일치하도록 하십시오.WanVideoAddTTMLatents(#104) TTM 모션 잠재적 요소와 시간적 마스크를 제어 스트림에 융합합니다. 마스크 입력을 전환하여 모션을 대상에 제한하십시오; 비워 두면 모션이 전역적으로 적용됩니다. 배경에 영향을 미치지 않고 궤적 특정 AI 비디오의 제어 가능한 애니메이션을 원할 때 사용하세요.SAM3VideoSegmentation(#687) 몇 개의 긍정적 및 부정적 포인트를 수집하고 트랙 프레임을 선택한 후 클립 전반에 전파하세요. 샘플링 전에 마스크 드리프트를 검증하기 위해 시각화 출력을 사용하세요. 프라이버시 민감하거나 오프라인 워크플로우의 경우, 모델 게이팅이 필요하지 않은 SAM2 그룹으로 전환하세요.WanVideoSampler(#27) 모션과 정체성을 균형 있게 하는 디노이저입니다. “Steps”와 CFG 일정 목록을 결합하여 모션 강도를 밀거나 완화하세요; 과도한 강도는 외관을 압도할 수 있으며, 너무 적으면 모션이 부족합니다. 마스크가 활성화되면 샘플러는 업데이트를 영역 내에 집중하여 AI 비디오의 제어 가능한 애니메이션의 안정성을 향상시킵니다.
선택적 추가 기능#
- 빠른 반복을 위해 LOW Wan2.2 모델로 시작하고 TTM을 사용하여 모션을 조정한 후 텍스처를 회복하기 위해 최종 패스에 HIGH로 전환하세요.
- 복잡한 실루엣을 위해 아티스트가 그린 마스크 비디오를 사용하세요; 로더는 외부 마스크를 수락하고 그에 맞게 크기를 조정합니다.
- “startframe/endframe” 스위치는 첫 번째 또는 마지막 프레임을 시각적으로 잠글 수 있게 하여 긴 편집에서 원활한 핸드오프에 유용합니다.
- 환경에서 사용 가능한 경우, 최적화된 어텐션 (예: SageAttention)을 활성화하면 샘플링 속도가 크게 향상될 수 있습니다.
- 결합 노드에서 출력 프레임 속도를 소스에 맞추어 AI 비디오의 제어 가능한 애니메이션에서 인식되는 타이밍 차이를 피하세요.
이 워크플로우는 텍스트 프롬프트, TTM 잠재적 요소 및 견고한 세분화를 결합하여 교육이 필요 없는 영역 인식 모션 제어를 제공합니다. 몇 가지 목표 입력만으로도 모델에 맞게 피사체를 유지하고 장면을 일관성 있게 유지하면서 세밀하고 제작 준비가 된 AI 비디오의 제어 가능한 애니메이션을 지시할 수 있습니다.
감사#
이 워크플로우는 다음 작업 및 리소스를 구현하고 발전시킵니다. 우리는 AI 비디오의 제어 가능한 애니메이션의 튜토리얼/게시물의 창작자인 Mickmumpitz와 그들의 기여 및 유지보수에 대해 TTM의 time-to-move 팀에 감사드립니다. 권위 있는 세부 사항에 대해서는 아래에 링크된 원본 문서 및 저장소를 참조하십시오.
리소스#
- Patreon/AI 비디오의 제어 가능한 애니메이션
- 문서 / 릴리스 노트: Mickmumpitz Patreon post
- time-to-move/TTM
- GitHub: time-to-move/TTM
참고: 참조된 모델, 데이터셋 및 코드의 사용은 해당 저자 및 유지 관리자가 제공한 라이센스 및 조건에 따릅니다.
