
InfiniteTalk: ComfyUI에서 단일 이미지로 립싱크된 초상화 비디오#
이 ComfyUI InfiniteTalk 워크플로우는 단일 참조 이미지와 오디오 클립에서 자연스럽고 말하기 동기화된 초상화 비디오를 생성합니다. WanVideo 2.1 이미지-비디오 생성과 MultiTalk 말하는-헤드 모델을 결합하여 표현력 있는 입술 동작과 안정적인 정체성을 제공합니다. 짧은 소셜 클립, 비디오 더빙, 또는 아바타 업데이트가 필요하다면, InfiniteTalk은 정지 사진을 몇 분 만에 유동적인 말하기 비디오로 변환합니다.
InfiniteTalk은 MeiGen-AI의 뛰어난 MultiTalk 연구를 기반으로 합니다. 배경 및 출처에 대해서는 오픈 소스 프로젝트를 참조하세요: MeiGen-AI/MultiTalk.
Comfyui InfiniteTalk 워크플로우의 주요 모델#
- MultiTalk (GGUF, InfiniteTalk 변형): 오디오로부터 음소 인식 안면 동작을 구동하여 입과 턱의 움직임이 자연스럽게 말을 추적하도록 합니다. 참조: Kijai/WanVideo_comfy_GGUF › InfiniteTalk 및 업스트림 아이디어: MeiGen-AI/MultiTalk.
- WanVideo 2.1 I2V 14B (GGUF): 프레임을 애니메이션화하면서 정체성, 조명 및 자세를 보존하는 주요 이미지-비디오 생성기입니다. 추천 가중치: city96/Wan2.1-I2V-14B-480P-gguf.
- Wan 2.1 VAE (bf16): 최소한의 색상 변화를 가지고 잠재 프레임을 RGB로 디코딩합니다; 위의 WanVideo 팩에 제공됩니다.
- UMT5-XXL 텍스트 인코더: 스타일, 장면 및 동작 컨텍스트를 조정하기 위해 긍정적 및 부정적 프롬프트를 해석합니다. 모델 가족: google/umt5-xxl.
- CLIP Vision: 참조 이미지에서 시각적 임베딩을 추출하여 정체성과 전체 외형을 잠급니다.
- Wav2Vec2 (Tencent GameMate): MultiTalk 임베딩을 위한 강력한 오디오 특성으로 원시 음성을 변환하여 동기화와 억양을 개선합니다: TencentGameMate/chinese-wav2vec2-base.
팁: 이 InfiniteTalk 그래프는 GGUF에 맞춰져 있습니다. InfiniteTalk MultiTalk 가중치와 WanVideo 백본을 GGUF에 유지하여 비호환성을 피하십시오. 선택적 fp8/fp16 빌드도 사용 가능합니다: Kijai/WanVideo_comfy_fp8_scaled 및 Kijai/WanVideo_comfy.
Comfyui InfiniteTalk 워크플로우 사용 방법#
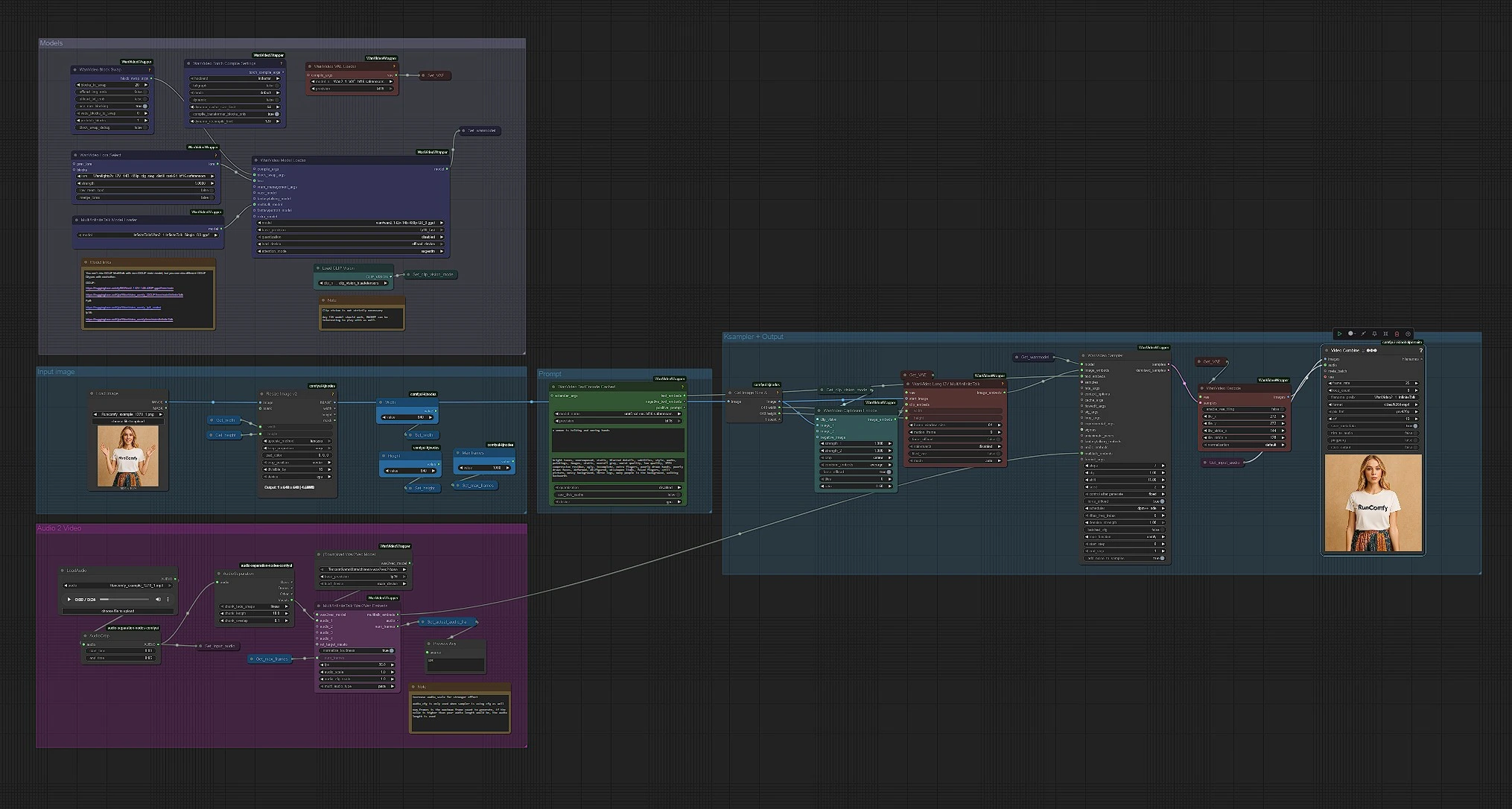
워크플로우는 왼쪽에서 오른쪽으로 실행됩니다. 세 가지를 제공하세요: 깨끗한 초상화 이미지, 음성 오디오 파일, 스타일을 조정하는 짧은 프롬프트. 그래프는 텍스트, 이미지 및 오디오 단서를 추출하여 모션 인식 비디오 잠재량으로 결합하고 동기화된 MP4를 렌더링합니다.
모델#
이 그룹은 WanVideo, VAE, MultiTalk, CLIP Vision 및 텍스트 인코더를 로드합니다. WanVideoModelLoader (#122)는 Wan 2.1 I2V 14B GGUF 백본을 선택하고, WanVideoVAELoader (#129)는 일치하는 VAE를 준비합니다. MultiTalkModelLoader (#120)는 음성 구동 동작을 지원하는 InfiniteTalk 변형을 로드합니다. WanVideoLoraSelect (#13)에 Wan LoRA를 선택적으로 연결하여 외형과 동작을 편향시킬 수 있습니다. 빠른 첫 실행을 위해 이들을 변경하지 마십시오; 대부분의 GPU에 친화적인 480p 파이프라인으로 사전 연결되어 있습니다.
프롬프트#
WanVideoTextEncodeCached (#241)는 긍정적 및 부정적 프롬프트를 UMT5로 인코딩합니다. 긍정적 프롬프트를 사용하여 주제와 장면 톤을 설명하고, 정체성은 참조 사진에서 가져옵니다. 부정적 프롬프트는 피하고 싶은 아티팩트 (흐림, 추가 팔다리, 회색 배경)에 집중하세요. InfiniteTalk의 프롬프트는 주로 조명과 움직임 에너지를 형성하며 얼굴은 일관성을 유지합니다.
입력 이미지#
CLIPVisionLoader (#238) 및 WanVideoClipVisionEncode (#237)는 초상화를 임베딩합니다. 선명하고 정면을 향한 머리와 어깨의 사진을 사용하세요. 필요하다면 얼굴이 움직일 공간이 있도록 부드럽게 자르세요; 심한 자르기는 동작을 불안정하게 할 수 있습니다. 이미지 임베딩은 비디오가 애니메이션화되면서 정체성과 의류 세부 정보를 보존하도록 전달됩니다.
오디오에서 MultiTalk로#
LoadAudio (#125)에 음성을 로드하고, AudioCrop (#159)으로 빠른 미리보기를 위해 자릅니다. DownloadAndLoadWav2VecModel (#137)는 Wav2Vec2를 가져오고, MultiTalkWav2VecEmbeds (#194)는 클립을 음소 인식 동작 특성으로 변환합니다. 4-8초의 짧은 컷은 반복에 좋습니다; 외형이 마음에 들면 더 긴 테이크를 실행할 수 있습니다. 깨끗하고 건조한 음성 트랙이 가장 잘 작동하며, 강한 배경 음악은 입술 타이밍을 혼란스럽게 할 수 있습니다.
이미지-비디오, 샘플링 및 출력#
WanVideoImageToVideoMultiTalk (#192)는 이미지, CLIP Vision 임베딩 및 MultiTalk를 프레임 단위의 이미지 임베딩으로 결합하여 Width 및 Height 상수에 의해 크기 조정합니다. WanVideoSampler (#128)는 Get_wanmodel에서 WanVideo 모델과 텍스트 임베딩을 사용하여 잠재 프레임을 생성합니다. WanVideoDecode (#130)는 잠재를 RGB 프레임으로 변환합니다. 마지막으로, VHS_VideoCombine (#131)는 프레임과 오디오를 25 fps로 MP4에 믹싱하여 최종 InfiniteTalk 클립을 생성합니다.
Comfyui InfiniteTalk 워크플로우의 주요 노드#
WanVideoImageToVideoMultiTalk (#192)#
이 노드는 InfiniteTalk의 핵심입니다: 시작 이미지를, CLIP Vision 특성과 MultiTalk 가이던스를 목표 해상도에서 병합하여 말하는 헤드 애니메이션을 조건화합니다. width와 height를 조정하여 비율을 설정하세요; 832×480은 속도와 안정성을 위한 좋은 기본값입니다. 샘플링 전에 정체성과 동작을 정렬하는 주요 장소로 사용하세요.
MultiTalkWav2VecEmbeds (#194)#
Wav2Vec2 특성을 MultiTalk 동작 임베딩으로 변환합니다. 입술 동작이 너무 미묘하다면 이 단계에서 영향력(오디오 스케일링)을 높이세요; 과장되었다면 영향력을 낮추세요. 신뢰할 수 있는 음소 타이밍을 위해 오디오가 음성 중심인지 확인하세요.
WanVideoSampler (#128)#
이미지, 텍스트 및 MultiTalk 임베딩을 제공하여 비디오 잠재를 생성합니다. 첫 실행에서는 기본 스케줄러와 단계를 유지하세요. 깜박임이 보이면 총 단계를 늘리거나 CFG를 활성화하면 도움이 될 수 있습니다; 동작이 너무 경직된 것 같으면 CFG나 샘플러 강도를 줄이세요.
WanVideoTextEncodeCached (#241)#
UMT5-XXL로 긍정적 및 부정적 프롬프트를 인코딩합니다. "스튜디오 조명, 부드러운 피부, 자연스러운 색상"과 같은 간결하고 구체적인 언어를 사용하고 부정적 프롬프트는 집중하세요. 프롬프트는 프레이밍과 스타일을 정제하며, 입술 동기화는 MultiTalk에서 나옵니다.
선택적 추가 기능#
- MultiTalk와 WanVideo를 동일한 배포 가족(모두 GGUF 또는 모두 비-GGUF)으로 유지하여 비호환성을 피하세요.
- 5-8초의 오디오 크롭과 기본 480p 크기로 반복하고, 필요하면 나중에 업스케일하세요.
- 정체성이 흔들리면 더 깨끗한 소스 사진이나 더 부드러운 LoRA를 시도하세요. 강한 LoRA는 유사성을 덮어쓸 수 있습니다.
- 조용한 방에서 음성을 녹음하고 레벨을 정규화하세요; InfiniteTalk은 명확하고 건조한 음성으로 음소를 가장 잘 추적합니다.
감사의 말#
InfiniteTalk 워크플로우는 ComfyUI의 유연한 노드 시스템과 MultiTalk AI 모델을 결합하여 AI 구동 비디오 생성에서 큰 도약을 나타냅니다. 이 구현은 InfiniteTalk의 자연스러운 말하기 동기화를 가능하게 하는 MultiTalk 프로젝트의 원래 연구 및 릴리스 덕분에 가능했습니다. 또한 소스 참조를 제공한 InfiniteTalk 프로젝트 팀과 원활한 워크플로우 통합을 가능하게 한 ComfyUI 개발자 커뮤니티에 특별한 감사를 드립니다.
추가적으로, Kijai에게도 감사드립니다. 그는 InfiniteTalk을 Wan Video Sampler 노드에 구현하여, 창작자들이 ComfyUI 내부에서 높은 품질의 말하고 노래하는 초상화를 쉽게 생성할 수 있도록 했습니다. InfiniteTalk의 원본 리소스 링크는 여기에서 확인할 수 있습니다: InfiniteTalk Example Workflow.
이러한 기여 덕분에 창작자들은 간단한 초상화를 생생한, 연속적인 말하는 아바타로 변환하여, AI 구동 스토리텔링, 더빙 및 공연 콘텐츠의 새로운 기회를 열 수 있게 되었습니다.