
ACE-Step 1.5XL Base text to music: Prompt‑to‑song workflow for ComfyUI#
이 워크플로우는 ACE-Step 1.5XL Base 확산 계열을 사용하여 자연 언어 설명을 완성된 오디오로 변환합니다. 기본 모델을 ACE Step VAE 및 이중 Qwen 텍스트 인코더와 결합하여 결과를 TTS나 음성이 아닌 음악에 확고히 유지합니다. 예측 가능한 구조, 템포 및 악기 배치가 있는 프롬프트 기반 AI 음악이 필요하다면, 이 ACE-Step 1.5XL Base text to music 파이프라인은 아이디어에서 MP3로 빠르게 전환할 수 있는 집중적이고 최소한의 설정입니다.
프로듀서, 사운드 디자이너, 창작자를 위해 설계된 이 그래프는 명확성을 강조합니다: 모델을 선택하고, 지속 시간을 설정하고, 음악 프롬프트를 작성한 다음 생성 및 저장합니다. ACE-Step 1.5XL Base text to music 워크플로우는 빠른 반복을 위해 충분히 컴팩트하면서도 상세한 배열, 키, 템포에 대해 표현력이 뛰어납니다.
Comfyui ACE-Step 1.5XL Base text to music workflow의 주요 모델#
- ACE-Step 1.5 XL Base (bf16) 확산 모델. 오디오 잠재를 일관된 음악 구문 및 텍스처로 디노이즈하는 생성 백본입니다. 모델 파일
- ACE Step 1.5 VAE. 잠재 공간과 파형 도메인 간의 인코딩/디코딩을 수행하여 음색 및 믹스 균형을 보존하는 짝을 이루는 변분 오토인코더입니다. 모델 파일
- Qwen 4B ACE15 텍스트 인코더. 프롬프트에서 풍부한 음악적 의미, 구조 및 배열 단서를 포착하기 위해 ACE에 적응된 대형 텍스트 인코더입니다. 모델 파일
- Qwen 0.6B ACE15 텍스트 인코더. 속도와 자원 효율성을 우선시하면서 강력한 프롬프트 이해를 유지하는 경량 ACE 적응 인코더입니다. 모델 파일
Comfyui ACE-Step 1.5XL Base text to music workflow 사용 방법#
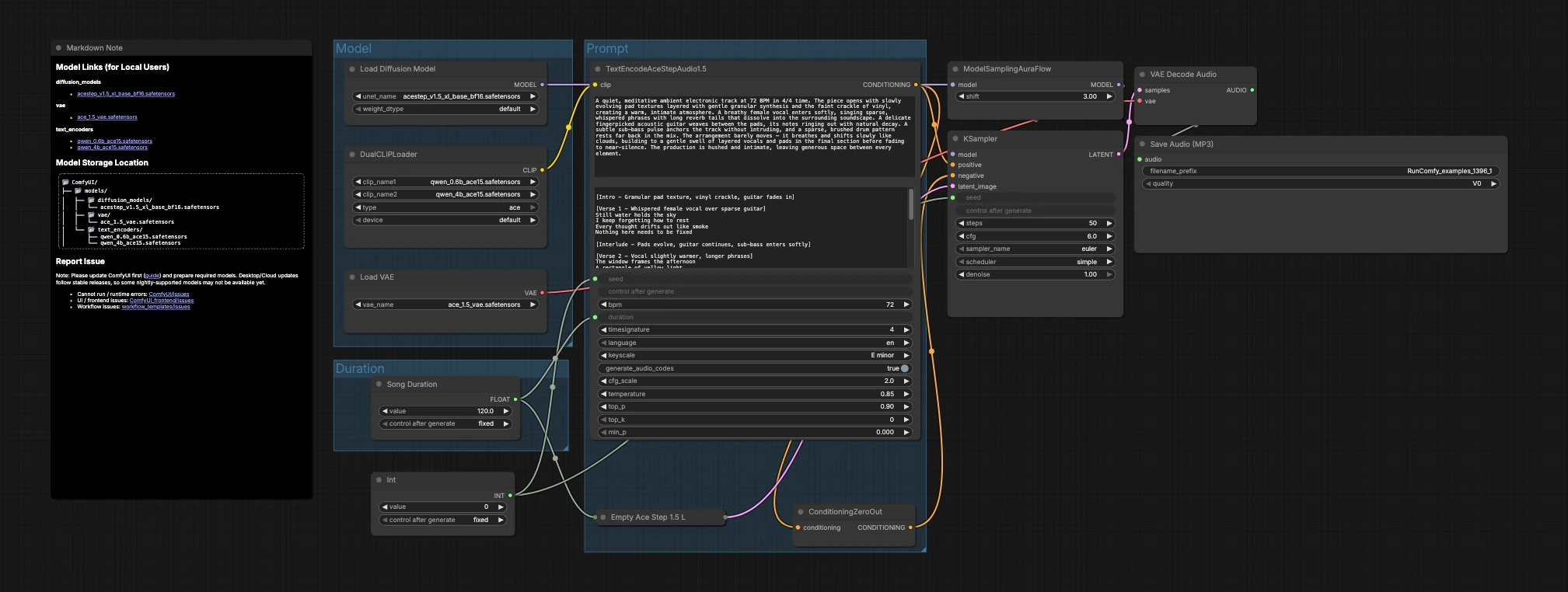
그래프는 모델, 지속 시간, 프롬프트의 세 그룹으로 구성되어 생성 및 내보내기로 흐릅니다: 모델을 로드하고, 목표 길이를 선택하고, 음악을 설명하면 샘플러가 VAE가 오디오로 디코딩하는 잠재를 생성합니다.
모델#
이 그룹은 핵심 자산을 로드합니다. UNETLoader (#104)는 ACE-Step 1.5 XL Base 확산 체크포인트를 선택하고, VAELoader (#106)는 매칭되는 ACE Step 1.5 VAE를 로드하여 디코딩 품질이 훈련과 일치하도록 합니다. DualCLIPLoader (#105)는 두 Qwen ACE15 인코더를 가져옵니다; 워크플로우는 이를 공동으로 사용하여 풍부한 텍스트 프롬프트가 강력한 음악적 조건으로 변환되도록 합니다.
지속 시간#
여기에서 곡의 길이를 결정합니다. Song Duration (#99)은 목표 길이를 초 단위로 설정하고 앞으로 전달하여 잠재 캔버스와 텍스트 조건이 일치하도록 합니다. PrimitiveInt (#109)는 시드를 제공하여 정확한 결과를 재현 가능하게 잠글 수 있거나, 다양한 해석을 탐색하기 위해 변경할 수 있습니다.
프롬프트#
이곳이 언어가 음악으로 변하는 곳입니다. TextEncodeAceStepAudio1.5 (#94)에 템포(BPM), 박자, 키, 악기 배치, 배열, 보컬 존재 및 믹스 메모와 같은 유용한 음악적 메타데이터를 포함하여 설명을 작성하세요. 노드는 긍정적 조건을 방출합니다; ConditioningZeroOut (#47)는 중립적인 부정 경로를 제공하여 생성이 설명에 집중하도록 합니다. EmptyAceStep1.5LatentAudio (#98)는 선택한 지속 시간을 위해 잠재 오디오 타임라인을 초기화합니다. ModelSamplingAuraFlow (#78)는 ACE-Step 오디오에 적합한 스케줄러에 기반 모델을 적응시킵니다. KSampler (#3)는 모델, 조건, 잠재 및 시드를 결합하여 음악 잠재를 생성합니다. VAEDecodeAudio (#18)는 잠재를 파형으로 변환하고, SaveAudioMP3 (#107)는 결과를 공유 준비가 된 MP3 파일로 저장합니다.
Comfyui ACE-Step 1.5XL Base text to music workflow의 주요 노드#
TextEncodeAceStepAudio1.5 (#94)#
프롬프트를 확산 모델이 따를 수 있는 조건으로 변환합니다. 템포, 박자표, 키, 배열 메모, 악기 구성, 언어, 선택적 보컬 의도와 같은 음악적 세부 정보를 수용합니다. 최상의 결과를 위해 장르, 느낌, 믹스 배치에 대해 구체적으로 설명하고, 모델이 요청된 지속 시간 동안 일관성을 유지할 수 있도록 구조적 단서를 간결하게 유지하세요.
EmptyAceStep1.5LatentAudio (#98)#
작품을 위한 잠재 오디오 "캔버스"를 생성합니다. Song Duration (#99)에서 설정한 초가 텍스트 인코더에 참조된 것과 일치하도록 하여 예기치 않은 잘림이나 패딩을 피하세요. 더 긴 캔버스는 점진적 발전을 초대하고, 더 짧은 캔버스는 루프, 큐, 스팅어에 적합합니다.
ModelSamplingAuraFlow (#78)#
ACE-Step 오디오에 맞춘 샘플링 전략을 구성합니다. 안정적인 결과를 위해 제공된 대로 사용하세요; KSampler (#3)에서 스텝 수와 가이드와 상호 작용하기 때문에 특정 스케줄러 선호도가 있는 경우에만 조정하세요.
KSampler (#3)#
조건을 오디오 잠재로 변환하는 디노이징을 수행합니다. 여기서 주요 레버는 샘플러 유형, 스텝 수, 시드입니다. 시간을 희생하고 디테일을 정제하기 위해 스텝을 늘리고, 프롬프트를 비교할 때 시드를 고정하여 변화가 텍스트에 기인할 수 있도록 하세요.
DualCLIPLoader (#105)#
두 Qwen ACE15 텍스트 인코더를 로드합니다. 두 가지에 접근할 수 있다면 4B 인코더를 활성화하여 더 풍부한 언어 이해를 시작하세요; 더 빠른 반복이나 낮은 메모리 사용이 필요할 때는 0.6B 변형으로 전환하세요. 미묘한 프롬프트 편집을 평가할 때 테이크 간에 인코더 선택을 일관되게 유지하세요.
ConditioningZeroOut (#47)#
중립적인 부정 경로를 제공합니다. 특정 아티팩트를 억제하거나 음성 콘텐츠에서 멀어지려면 실제 부정 프롬프트 노드로 대체할 수 있습니다; 그렇지 않으면 0으로 된 부정은 ACE-Step 1.5XL Base text to music 생성을 긍정적 설명에 집중하게 유지합니다.
선택적 추가 사항#
- 간결한 레시피로 프롬프트를 시작하세요: 장르 + 분위기 + 템포 + 박자 + 키 + 악기 구성 + 배열 + 믹스 메모.
- 명확한 음악적 동사와 역할(리드, 패드, 베이스, 타악기)을 사용하여 모델이 믹스에 공간을 할당하고 음성 같은 콘텐츠를 피하도록 하세요.
- 프롬프트를 A/B 테스트할 때 시드를 고정하고, 우승 아이디어의 대체 공연을 탐색하기 위해 시드를 변경하세요.
Song Duration(#99),TextEncodeAceStepAudio1.5(#94),EmptyAceStep1.5LatentAudio(#98) 간의 지속 시간을 일치시켜 예측 가능한 구문을 유지하세요.- Qwen 4B를 선택하여 더 풍부한 프롬프트 이해를 하거나 0.6B를 선택하여 속도를 높이세요; 비교를 공정하게 하기 위해 반복하는 동안 선택을 일정하게 유지하세요.
감사의 말씀#
이 워크플로우는 다음의 작업과 리소스를 구현 및 구축합니다. 우리는 Comfy.org의 audio_ace_step1_5_xl_base 워크플로우, Comfy-Org의 ACE Step 1.5 XL Base 확산 모델 및 ACE Step 1.5 VAE, Qwen 팀의 0.6B 및 4B ACE15 텍스트 인코더에 대한 기여 및 유지 보수에 대해 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하십시오.
리소스#
- Comfy.org/Workflow 소스 페이지
- 문서 / 릴리스 노트: audio_ace_step1_5_xl_base workflow page
- Comfy-Org/ACE Step 1.5 XL Base 확산 모델
- Hugging Face: acestep_v1.5_xl_base_bf16.safetensors
- Comfy-Org/ACE Step 1.5 VAE
- Hugging Face: ace_1.5_vae.safetensors
- Comfy-Org/Qwen 0.6B ACE15 텍스트 인코더
- Hugging Face: qwen_0.6b_ace15.safetensors
- Comfy-Org/Qwen 4B ACE15 텍스트 인코더
- Hugging Face: qwen_4b_ace15.safetensors
참고: 참조된 모델, 데이터세트 및 코드의 사용은 해당 저자 및 유지 보수자가 제공한 라이센스 및 조건에 따릅니다.
