
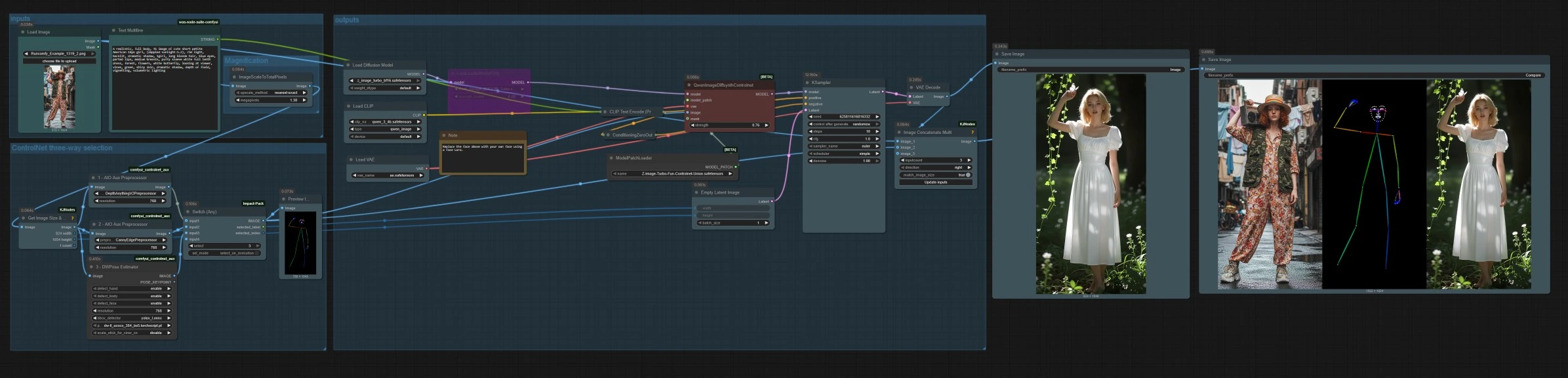








ComfyUIでの構造ガイド付き画像生成のためのZ Image ControlNetワークフロー#
このワークフローは、Z Image ControlNetをComfyUIに導入し、リファレンス画像からの正確な構造でZ-Image Turboを操作できるようにします。1つのグラフ内で3つのガイダンスモード(深度、キャニーエッジ、人間のポーズ)をバンドルし、それらの間をタスクに合わせて切り替えることができます。その結果、レイアウト、ポーズ、構成が制御されたまま、迅速で高品質なテキストまたは画像から画像への生成が可能になります。
アーティスト、コンセプトデザイナー、レイアウトプランナー向けに設計されており、グラフはバイリンガルプロンプトとオプションのLoRAスタイリングをサポートします。選択した制御信号のクリーンなプレビューと、深度、キャニー、またはポーズを最終出力と比較するための自動比較ストリップを取得できます。
Comfyui Z Image ControlNetワークフローの主要モデル#
- Z-Image Turboディフュージョンモデル6Bパラメータ。プロンプトと制御信号からフォトリアルな画像を迅速に生成する主要ジェネレーター。alibaba-pai/Z-Image-Turbo
- Z Image ControlNet Unionパッチ。Z-Image Turboにマルチコンディション制御を追加し、1つのモデルパッチで深度、エッジ、ポーズガイダンスを可能にします。alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
- Depth Anything v2。深度モードでの構造ガイダンスに使用される高密度深度マップを生成します。LiheYoung/Depth-Anything-V2 on GitHub
- DWPose。ポーズガイド生成のために人間のキーポイントと体のポーズを推定します。IDEA-Research/DWPose
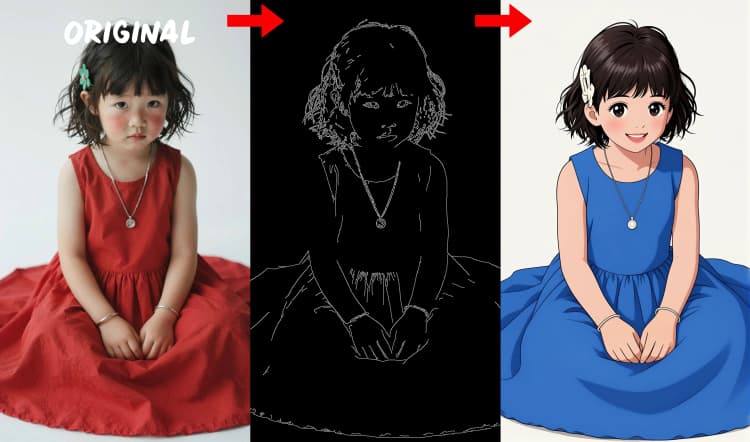
- キャニーエッジ検出器。レイアウト駆動の制御のためにクリーンな線画と境界を抽出します。
- ComfyUI用のControlNet Auxプリプロセッサ。深度、エッジ、およびこのグラフで使用されるポーズのための統一ラッパーを提供します。comfyui_controlnet_aux
Comfyui Z Image ControlNetワークフローの使用方法#
高レベルでは、リファレンス画像をロードまたはアップロードし、深度、キャニー、またはポーズのいずれかの制御モードを選択し、テキストプロンプトで生成します。グラフはリファレンスの効率的なサンプリングのためにスケールし、対応するアスペクト比で潜在を構築し、最終画像と並べて比較ストリップの両方を保存します。
入力#
LoadImage (#14)を使用してリファレンス画像を選択します。Text Multiline (#17)でテキストプロンプトを入力します。Z-Imageスタックはバイリンガルプロンプトをサポートしています。プロンプトはCLIPLoader (#2)とCLIPTextEncode (#4)によってエンコードされます。純粋に構造駆動の画像から画像への生成を好む場合は、プロンプトを最小限に抑え、選択した制御信号に依存できます。
ControlNet三方向選択#
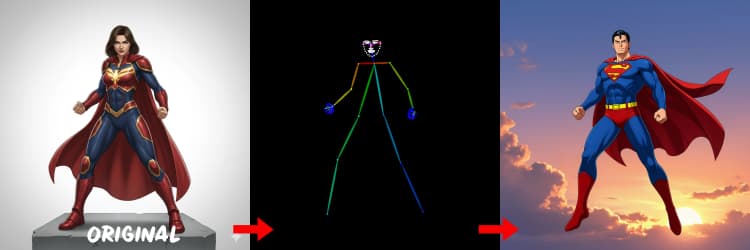
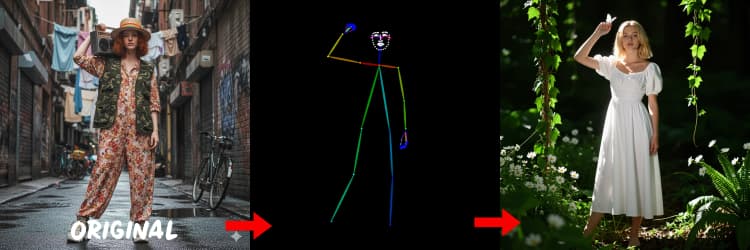
3つのプリプロセッサがリファレンスを制御信号に変換します。AIO_Preprocessor (#45)はDepth Anything v2で深度を生成し、AIO_Preprocessor (#46)はキャニーエッジを抽出し、DWPreprocessor (#56)は全身ポーズを推定します。ImpactSwitch (#58)を使用して、どの信号がZ Image ControlNetを駆動するかを選択し、PreviewImage (#43)で選択した制御マップを確認します。シーンのジオメトリが必要な場合は深度を、鮮明なレイアウトや製品ショットにはキャニーを、キャラクター作業にはポーズを選択します。
OpenPoseのヒント: 1. 全身に最適: OpenPoseはプロンプトに"full body"を含めるときに最も効果的です(約70-90%の精度)。 2. クローズアップには避ける: 顔の精度は大幅に低下します。クローズアップにはDepthまたはCanny(低/中強度)を使用してください。 3. プロンプトが重要: プロンプトはControlNetに大きく影響します。曖昧なプロンプトは避けてください。
拡大#
ImageScaleToTotalPixels (#34)は、品質と速度のバランスを取るためにリファレンスを実用的な作業解像度にリサイズします。GetImageSizeAndCount (#35)はスケールされたサイズを読み取り、幅と高さを前方に渡します。EmptyLatentImage (#6)は、リサイズされた入力のアスペクトに一致する潜在キャンバスを作成し、構成の一貫性を保ちます。
出力#
QwenImageDiffsynthControlnet (#39)は、ベースモデルとZ Image ControlNetユニオンパッチおよび選択した制御画像を融合し、KSampler (#7)は、正と負のコンディショニングによって導かれた結果を生成します。VAEDecode (#8)は、潜在を画像に変換します。ワークフローは2つの出力を保存します。SaveImage (#31)は最終画像を書き込み、SaveImage (#42)はImageConcatMulti (#38)を介してソース、制御マップ、および結果を含む比較ストリップを書き込みます。
Comfyui Z Image ControlNetワークフローの主要ノード#
ImpactSwitch (#58)#
生成を駆動する制御画像(深度、キャニー、またはポーズ)を選択します。各制約が構成と詳細をどのように形作るかを比較するためにモードを切り替えます。レイアウトを繰り返す際に、どのガイダンスが目標に最適かを迅速にテストするために使用してください。
QwenImageDiffsynthControlnet (#39)#
ベースモデル、Z Image ControlNetユニオンパッチ、VAE、および選択された制御信号をブリッジします。strengthパラメータは、モデルが制御入力に対してプロンプトをどの程度厳密に従うかを決定します。レイアウトの厳密な一致には強度を上げ、より創造的なバリエーションには減らします。
AIO_Preprocessor (#45)#
Depth Anything v2パイプラインを実行して、高密度の深度マップを作成します。詳細な構造には解像度を上げ、迅速なプレビューには下げます。建築シーン、製品ショット、ジオメトリが重要な風景に適しています。
DWPreprocessor (#56)#
人やキャラクターに適したポーズマップを生成します。手足が見えており、あまり覆われていないときに最も効果的です。手や足が欠けている場合は、より明確なリファレンスまたはより完全な体の可視性を持つ別のフレームを試してください。
LoraLoaderModelOnly (#54)#
スタイルまたはアイデンティティの手がかりのためにベースモデルにオプションのLoRAを適用します。strength_modelを調整して、LoRAを穏やかにまたは強くブレンドします。顔のLoRAを差し替えて被写体をパーソナライズしたり、スタイルのLoRAを使用して特定の外観を固定したりできます。
KSampler (#7)#
プロンプトと制御を使用してディフュージョンサンプリングを実行します。再現性のためにseedを調整し、洗練予算のためにstepsを、プロンプトの従順性のためにcfgを、初期潜在からどの程度出力を逸脱させるかのためにdenoiseを調整します。画像から画像への編集には構造を保持するためにdenoiseを下げ、より大きな変化を許可するには高くします。
オプションの追加機能#
- 構成を引き締めるために、クリーンで均一に照らされたリファレンスを使用して深度モードを使用します。キャニーは強いコントラストを好み、ポーズは全身ショットを好みます。
- ソース画像からの微妙な編集には、denoiseを控えめにし、忠実な構造のためにControlNetの強度を上げます。
- より多くの詳細が必要な場合は、拡大グループでターゲットピクセルを増やし、迅速なドラフトには再び減らします。
- 比較出力を使用して、深度対キャニー対ポーズを迅速にA/Bテストし、被写体に最も信頼性のある制御を選択します。
- 例のLoRAを自分の顔またはスタイルLoRAに置き換えて、再トレーニングなしでアイデンティティまたはアートディレクションを組み込みます。
謝辞#
このワークフローは、以下の作品およびリソースを実装および構築しています。Z Image ControlNetを提供し、メンテナンスしているAlibaba PAIに感謝いたします。権威ある詳細については、以下にリンクされた元のドキュメントおよびリポジトリを参照してください。
リソース#
- Alibaba PAI/Z Image ControlNet
- Hugging Face: alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者およびメンテナによって提供されるライセンスおよび条件に従います。


