
Wan2.2 S2V: ComfyUIでのシングルイメージからのサウンドトゥビデオ#
Wan2.2 S2Vは、1つの参照画像と音声クリップを同期したビデオに変換するサウンドトゥビデオワークフローです。Wan 2.2モデルファミリーを基に構築され、音声やスピーチに従った表現豊かな動き、リップシンク、シーンダイナミクスを求めるクリエイター向けに設計されています。手動アニメーションなしでトーキングアバター、音楽駆動ループ、クイックストーリービートを作成するためにWan2.2 S2Vを使用してください。
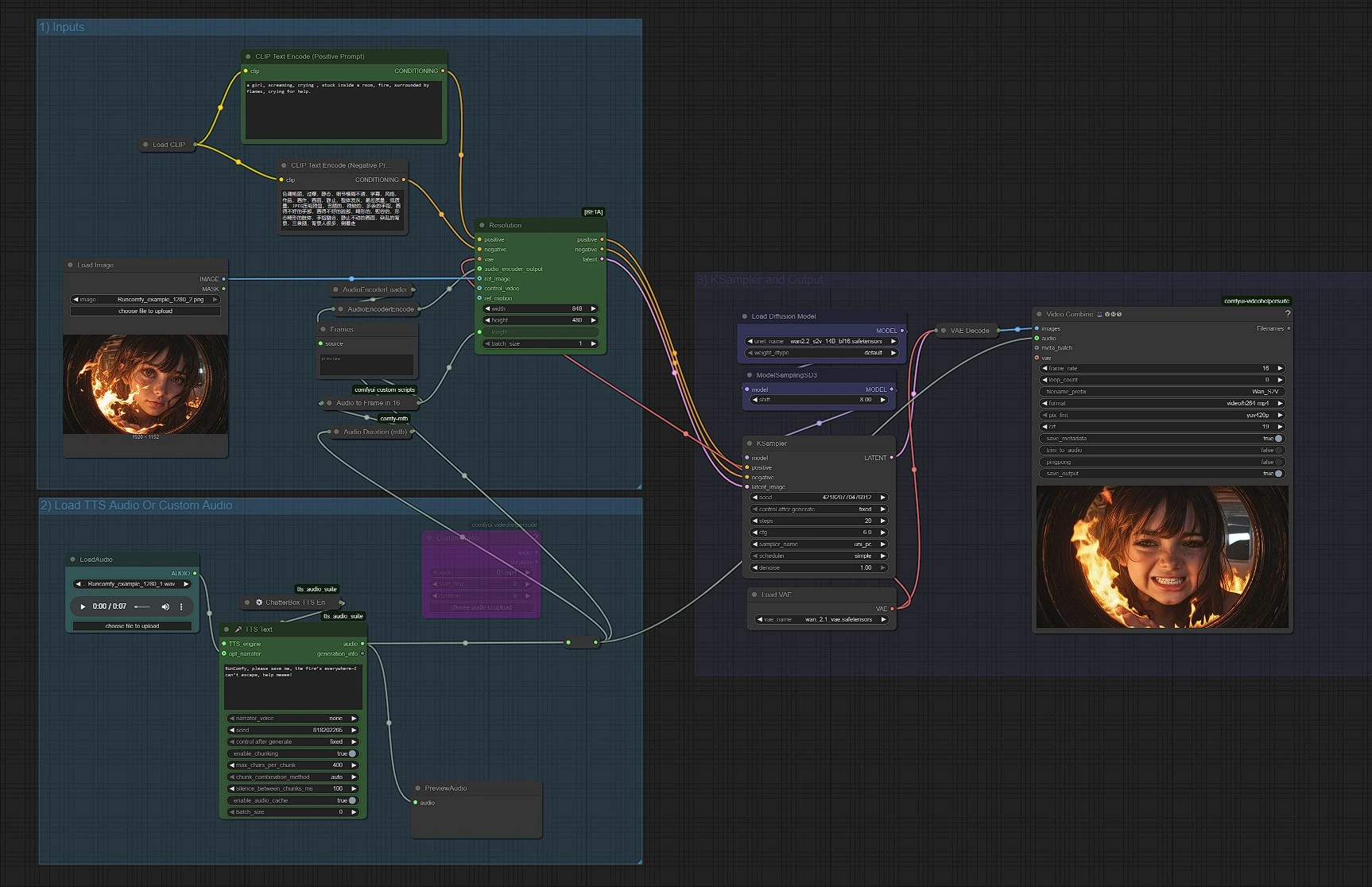
このComfyUIグラフは、音声機能をテキストプロンプトと静止画像と結合して短いクリップを生成し、その後、元の音声とフレームを混合します。結果は、参照画像の外観を保持しながら音声がタイミングと表情を駆動するコンパクトで信頼性のあるパイプラインです。
Comfyui Wan2.2 S2Vワークフローの主要モデル#
- Wan 2.2 S2V UNet (14B, bf16)。音声機能、テキスト条件付け、参照画像を融合してビデオ潜在を生成するコアジェネレーター。
- Wan VAE (wan_2.1_vae)。潜在空間とピクセル空間間でエンコード/デコードし、Wan2.2 S2Vレンダリングの詳細と色の忠実性を保持。
- UMT5-XXLテキストエンコーダー。スタイルとコンテンツのプロンプト条件付けを提供します。ベースモデルカードについては、google/umt5-xxlをご覧ください。
- Wav2Vec2 Largeオーディオエンコーダー。サウンド条件付けされた生成のための頑強なスピーチとリズム機能を抽出します。典型的なカードについては、facebook/wav2vec2-large-960hをご覧ください。
Comfyui Wan2.2 S2Vワークフローの使用方法#
ワークフローは3つのグループに編成されています。エンドツーエンドで実行するか、必要に応じて各ステージを調整できます。
1) 入力#
このグループは、Wanのテキスト、画像、VAEコンポーネントをロードし、プロンプトを準備します。スタイルと品質を導くために、CLIPLoader (#38)とCLIPTextEncode (#6)を使用してポジティブプロンプトを、CLIPTextEncode (#7)を使用してネガティブプロンプトを設定します。LoadImage (#52)で参照画像をロードし、Wan2.2 S2Vのアイデンティティ、フレーミング、パレットをアンカーします。ポジティブプロンプトは簡潔に記述し、音声がモーションを制御できるようにします。VAE (VAELoader (#39))およびモデルローダー (UNETLoader (#37))は事前に配線され、通常そのままにしておきます。
2) TTSオーディオまたはカスタムオーディオのロード#
音声の提供方法を選択します。クイックテストには、UnifiedTTSTextNode (#71)でスピーチを生成し、PreviewAudio (#65)でプレビューします。自分の音楽や対話を使用する場合は、LoadAudio (#78)でローカルファイルを、またはVHS_LoadAudioUpload (#87)でアップロードを選択します。どちらもReroute (#88)を通じてダウンストリームノードに単一のオーディオソースを表示します。Audio Duration (mtb) (#68)で持続時間を測定し、MathExpression|pysssss (#67)により「16 FPSでのオーディオからフレーム」に変換されます。音声機能はAudioEncoderLoader (#57)とAudioEncoderEncode (#56)で生成され、これらがWan2.2 S2VノードにAUDIO_ENCODER_OUTPUTを供給します。
3) KSamplerと出力#
WanSoundImageToVideo (#55)はWan2.2 S2Vの中心です。プロンプト、VAE、音声機能、参照画像、およびlength整数(フレーム)を消費し、条件付けされた潜在シーケンスを発信します。その潜在はKSampler (#3)に送られ、サンプラー設定が全体の一貫性と詳細を管理しつつ音声駆動のタイミングを順守します。サンプルされた潜在はVAEDecode (#8)でフレームにデコードされ、VHS_VideoCombine (#66)がビデオを組み立て、元の音声を混合してMP4を生成します。ModelSamplingSD3 (#54)はWanバックボーンに適したサンプラーファミリーを設定するために使用されます。
Comfyui Wan2.2 S2Vワークフローの主要ノード#
WanSoundImageToVideo (#55)#
1枚の画像からオーディオ同期モーションを駆動します。アニメーション化したいポートレートまたはシーンにref_imageを設定し、エンコーダーからaudio_encoder_outputを接続し、フレーム数でlengthを提供します。より長いクリップにはlengthを増やし、よりスナッピーなプレビューには減らします。別の場所でFPSを変更した場合、タイミングが同期するようにフレーム値を更新してください。
AudioEncoderLoader (#57)とAudioEncoderEncode (#56)#
スピーチまたは音楽をWanが追従できる機能に変えるWav2Vec2ベースのエンコーダーをロードして実行します。リップシンクにはクリーンなスピーチを使用し、リズムモーションにはパーカッシブ/ビート重視のオーディオを使用してください。入力言語またはドメインが異なる場合は、整列を改善するために互換性のあるWav2Vec2チェックポイントを交換してください。
CLIPTextEncode (#6)とCLIPTextEncode (#7)#
UMT5/CLIP条件付けのためのポジティブおよびネガティブプロンプトエンコーダーです。ポジティブプロンプトは簡潔にし、対象、スタイル、ショット用語に焦点を当てます。ネガティブプロンプトを使用して不要なアーティファクトを回避します。あまりに強制的なプロンプトは音声と競合する可能性があるため、軽いガイダンスを好み、Wan2.2 S2Vにモーションを任せてください。
KSampler (#3)#
Wan2.2 S2Vノードによって生成された潜在シーケンスをサンプリングします。スピードと忠実性をトレードするためにサンプラータイプとステップを調整します。同じ音声で再現可能なタイミングを望む場合は、固定シードを保持します。モーションがあまりにも硬直しているかノイズが多い場合は、ここでの小さな変更が時間的安定性を著しく向上させることがあります。
VHS_VideoCombine (#66)#
最終ビデオを作成し、音声を添付します。frame_rateを意図したFPSに合わせて設定し、クリップの長さがlengthフレームに一致することを確認します。コンテナ、ピクセルフォーマット、および品質コントロールはクイックエクスポート用に公開されています。エディタで後処理を計画している場合は、高品質を使用してください。
オプションの追加機能#
- アイデンティティのドリフトとクロップを最小限に抑えるために、ターゲットアスペクト比で照明の良い正面の参照画像から始めてください。
- リップシンクには口を遮らないようにし、クリーンなナレーションを使用してください。ビート駆動のモーションには強いトランジェントを持つ音楽がよく適しています。
- デフォルトのFPS変換は16 fpsを前提としており、FPSを変更した場合は「Audio to Frame in 16 FPS」の数式を更新して、フレームがオーディオの持続時間と一致するようにしてください。
- オーディオプレビューとVHSライブプレビューを使用して迅速に繰り返し、タイミングが気に入ったら品質を上げます。
- 長いクリップは計算とVRAMをスケールします。長いスクリプトを分割して短いシーンにするか、マルチショットビデオを生成する際に沈黙をトリムしてください。
謝辞#
このワークフローは以下の作品とリソースを実装し、構築しています。我々はWan-Videoに対し、Wan2.2 (S2V推論コードを含む)、Wan-AIに対し、Wan2.2-S2V-14B、およびGao et al. (2025)に対し、Wan-S2V: Audio-Driven Cinematic Video Generationの貢献とメンテナンスに感謝します。権威ある詳細については、以下にリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- Wan-Video/Wan2.2 S2V Demo
- GitHub: Wan-Video/Wan2.2
- Hugging Face: Wan-AI/Wan2.2-S2V-14B
- arXiv: Wan-S2V: Audio-Driven Cinematic Video Generation
- Docs / Release Notes: Wan2.2 S2V Demo
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者およびメンテナによって提供されるライセンスおよび条件に従います。