
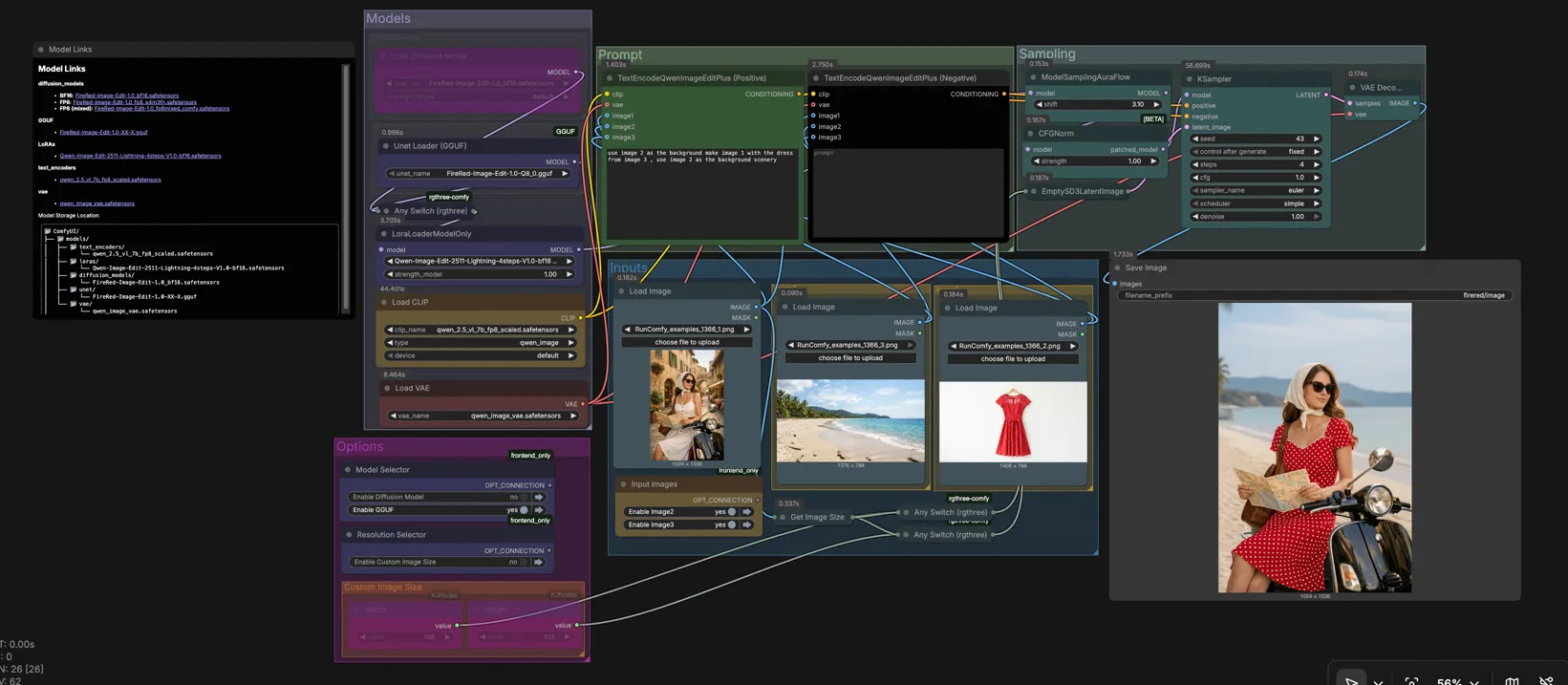





FireRed画像編集1.0 ComfyUIワークフロー#
FireRed画像編集1.0は、ComfyUIのための一般的な指示に従う画像編集ワークフローで、高忠実度の結果と強い視覚的一貫性を提供します。オブジェクトの交換、背景の置換、スタイルを維持した改良、テキストスタイルの保存、フォト復元、バーチャル試着など、シングルおよびマルチイメージ編集をサポートします。このグラフは、RunComfyや類似のホストされたセットアップでの迅速な反復のために設計されており、モデル選択、解像度、サンプリングのための明確なコントロールを備えています。
自然言語の指示から正確な編集を必要とするクリエイター、デザイナー、研究者であれば、このFireRed画像編集ワークフローを使用して、複雑な変換を指導するためにプレーンテキストのガイダンスを1から3の参照画像と組み合わせることができます。
ComfyUI FireRed画像編集ワークフローの主要モデル#
- FireRed-Image-Edit-1.0。強い視覚的一貫性を持つ指示に従う編集を行うベースディフュージョンモデル。高精度のBF16および制約のあるハードウェアに適した量子化バリアントで利用可能。Model card
- FireRed-Image-Edit-1.0 GGUF。CPUまたは低VRAM推論用に最適化された量子化UNetバージョンで、メモリフットプリントを削減しながらベースFireRed画像編集の動作を保持します。Weights
- Qwen2.5-VL 7Bテキストエンコーダー(FP8, Comfy-packaged)。指示をFireRed画像編集が従うコンディショニングに変換するマルチモーダルテキストイメージ埋め込みを提供します。Files
- Qwen Image VAE。FireRed画像編集パイプラインと互換性のある潜在変数をエンコードおよびデコードし、再構築中の詳細を保持します。Files
- Qwen-Image-Edit-2511-Lightning LoRA。ベースモデルを迅速でステップ効率の高い推論に適応させながら、編集意図を明確に保つオプションのLoRA。迅速なプレビューやよりスナッピーなFireRed画像編集反復ループを望む場合に使用します。Model
ComfyUI FireRed画像編集ワークフローの使用方法#
高レベルでは、モデルバリアントを選択し、1から3の参照画像をロードし、それらの画像を名指しする指示を書き、ターゲット解像度を設定してサンプルを保存します。キャンバス内のグループがこのフローを反映しているため、ノードを探すことなく上から下へ作業できます。
モデル#
このグループでは、ハードウェアとスピードのニーズに合ったFireRed画像編集バックボーンを選択できます。グラフには高品質のBF16 UNetとGGUF量子化UNetが含まれており、Any Switch (rgthree) (#91)にワイヤリングされているため、これらを切り替えることができます。LoraLoaderModelOnly (#74)は、Qwen-Image-Edit-2511-Lightning LoRAを適用してプレビューを加速するオプションです。その後、モデルはサンプリングとガイダンスの正規化で準備され、安定した指示に従います。
プロンプト#
指示は正のガイダンスと負のガイダンスのために2つのTextEncodeQwenImageEditPlusノードでエンコードされます。ロードされた画像を「image 1」、「image 2」、「image 3」として明示的に参照し、FireRed画像編集が各参照をどのように使用するかを制御します。たとえば、画像1を主題として保持し、画像2の背景に配置し、画像3から衣服やスタイルを転送するように要求できます。不要なオブジェクト、色の変化、テキストの変更などを避けるために負のプロンプトを使用します。
入力#
入力エリアにソースをロードします:画像1は通常メインの主題、画像2は代替背景またはコンテキスト、画像3はスタイルまたは衣服の参照です。シングルイメージでも、2つまたは3つを組み合わせてマルチイメージ編集を行うことができます。グラフはGetImageSizeを使用して画像1の寸法を読み取り、必要に応じて解像度を自動一致させることができます。画像は正と負のエンコーダーの両方に渡され、指示が一貫してそれらを活用できるようにします。
Image2#
異なる背景、照明、レイアウトが必要な場合にこのスロットを使用します。正の指示で配置を説明し、画像2のどの部分を使用するかを指定します。全体的なシーンの置換を防ぎたい場合、ネガティブガイダンスを使用して部分的な合成を防ぐことができます。FireRed画像編集は、主題の境界を整列させながら、主題の外観を維持します。
Image3#
スタイルやオブジェクトの転送、例えばバーチャル試着やアクセサリーの交換にこのスロットを使用します。「画像3から赤いジャケット」や「画像3の筆致スタイル」のように、転送する正確な属性を名指しします。これにより、FireRed画像編集のコンディショニングが集中し、1つの要素のみを変更したい場合にグローバルな再スタイリングを防ぎます。
ディフュージョンモデル#
このビューは、BF16 FireRed画像編集UNetを公開します。最高のディテール忠実度と複雑な指示の最も安定した実行のために選択します。大きな解像度でメモリ制限に遭遇した場合、GGUFパスを検討してください。
GGUF#
このビューは、CPUまたは低VRAMデバイス用に最適化されたGGUF量子化FireRed画像編集UNetを公開します。ほとんどの編集に対して品質は強く、メモリ使用量が著しく減少します。控えめなハードウェアでバッチ可能で再現可能なレンダーを実行する際に理想的です。
サンプリング#
サンプリングブロックは、正と負のコンディショニングを潜在キャンバスと組み合わせ、最終的な編集を生成します。EmptySD3LatentImage (#116)はターゲット解像度とバッチサイズを設定し、KSampler (#65)は選択したスケジューラとシードを使用してステップを実行します。VAEDecodeは潜在変数を画像に変換してプレビューし、SaveImageはファイルをComfyUIの出力ディレクトリに書き込みます。シードを固定して再現性を確保するか、指示を尊重する代替案を探索するために変化させます。
オプション#
モデルセレクターエリアを使用して、再配線せずにBF16とGGUFバリアントを切り替えます。解像度セレクターは画像1に自動一致させるか、カスタムイメージサイズグループを使用できます。これらのコントロールは、FireRed画像編集フローを迅速に保ち、ジョブごとにコスト、速度、品質を調整できるように設計されています。
カスタムイメージサイズ#
明示的な制御が必要な場合、幅と高さを設定する2つの整数ウィジェットがあります。このパスは潜在ジェネレーターにフィードされ、実行全体が選択したサイズを尊重します。FireRed画像編集で最高のディテールを得るには、メインの主題または背景画像のアスペクトに近い解像度を優先し、リサンプリングによるアーティファクトを減らしてください。
ComfyUI FireRed画像編集ワークフローの主要ノード#
Any Switch (rgthree) (#91)#
BF16 FireRed画像編集UNetまたはGGUFバリアントを通じてグラフをルーティングし、ダウンストリームの配線を変更せずに使用します。品質と速度のA/Bテストや、同じグラフを通じてCPUおよびGPUワーカーをルーティングするために使用します。プロジェクトリンク:rgthree/rgthree-comfy
LoraLoaderModelOnly (#74)#
選択されたFireRed画像編集モデルにQwen-Image-Edit-2511-Lightning LoRAを適用します。低ステップでよりスナッピーなプレビューを望む場合に強度を増加させ、過度に断定的な変更が見られる場合は減少させます。アイデア出しのために有効にしておき、最終的な最高忠実度のレンダリングのために無効にするか柔らかくしてください。モデルリンク:lightx2v/Qwen-Image-Edit-2511-Lightning
TextEncodeQwenImageEditPlus (Positive) (#68)#
指示をコンディショニングに変換し、最大3つの参照画像を取り込みます。直接的で曖昧でない指示を書き、合成、属性転送、レイアウト制約のために画像番号を明示的に参照します。名詞と動詞を具体的にするほど、FireRed画像編集はそれに従います。
TextEncodeQwenImageEditPlus (Negative) (#69)#
アーティファクト、オフスタイル、望まない変更を禁止することができます。タイポグラフィ、ブランドカラー、アイデンティティを保持するために使用し、主要な指示が強い変換を押し進めるときでも使用します。明確なポジティブと組み合わせて、創造性と保存をバランスさせます。
EmptySD3LatentImage (#116)#
選択した解像度で潜在キャンバスを作成します。忠実な合成のために画像1のサイズに一致させるか、印刷または特定のアスペクト比に向けた出力のためにカスタム解像度を設定します。編集後に控えめなアップスケールを検討し、非常に高い解像度で編集するのではなく行うことをお勧めします。
KSampler (#65)#
指示を実現するためのノイズ除去プロセスを駆動します。ステップ、スケジューラ、シードを調整して速度と忠実度をバランスさせます。Lightning LoRAが有効な場合、強力なプレビューには少ないステップで十分です。一方、BF16パスはより保守的な設定で最終版に理想的です。コアノード参照:ComfyUI
オプションの追加#
- 迅速な反復のために、最初にGGUFパスとLightning LoRAで開始し、最終版にはBF16に切り替えます。
- ソースを名指しするプロンプトを書きます。例:「画像1の主題を画像2の背景に配置し、画像3からジャケットを転送し、照明を一貫させる。」
- FireRed画像編集で製品ショットを編集する際、ブランドカラー、ロゴ、テキストを保護するためにネガティブプロンプトを使用します。
- 合成のために画像1に解像度を自動一致させるか、背景全体を置き換える場合はカスタムサイズを設定します。
- BF16とGGUFの出力を比較する際、シードを固定して違いがモデル選択によるものであることを確認します。
謝辞#
このワークフローは、以下の作品とリソースを実装し、それに基づいて構築されています。FireRed-Image-Edit-1.0およびEyeForAILabsのYouTubeチュートリアルに対する貢献とメンテナンスに対して、@eyeforailabsとFireRedTeamに心から感謝します。権威ある詳細については、以下にリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- FireRedTeam/FireRed-Image-Edit-1.0
- GitHub: FireRedTeam/FireRed-Image-Edit
- Hugging Face: FireRedTeam/FireRed-Image-Edit-1.0
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: @eyeforailabs YouTube Tutorial
注意:参照されたモデル、データセット、コードの使用は、それぞれの著者およびメンテナの提供するライセンスおよび条件に従うものとします。