
Wan2.1 Stand In: generazione di video coerenti con il personaggio da singola immagine per ComfyUI#
Questo flusso di lavoro trasforma un'immagine di riferimento in un breve video in cui lo stesso volto e stile persistono nei fotogrammi. Alimentato dalla famiglia Wan 2.1 e da uno Stand In LoRA costruito a scopo, è progettato per narratori, animatori e creatori di avatar che necessitano di un'identità stabile con una configurazione minima. La pipeline Wan2.1 Stand In gestisce la pulizia dello sfondo, il ritaglio, la mascheratura e l'incorporamento così puoi concentrarti sul tuo prompt e sul movimento.
Usa il flusso di lavoro Wan2.1 Stand In quando desideri una continuità affidabile dell'identità da una singola foto, iterazioni rapide e MP4 pronti per l'esportazione più un output di confronto facoltativo affiancato.
Modelli chiave nel flusso di lavoro Comfyui Wan2.1 Stand In#
- Wan 2.1 Text‑to‑Video 14B. Il generatore principale responsabile della coerenza temporale e del movimento. Supporta la generazione a 480p e 720p e si integra con LoRAs per comportamenti e stili mirati. Model card
- Wan‑VAE per Wan 2.1. Un VAE spaziotemporale ad alta efficienza che codifica e decodifica latenti video preservando gli indizi di movimento. Sostiene le fasi di codifica/decodifica delle immagini in questo flusso di lavoro. Vedi le risorse del modello Wan 2.1 e le note di integrazione Diffusers per l'uso del VAE. Model hub • Diffusers docs
- Stand In LoRA per Wan 2.1. Un adattatore di coerenza del personaggio addestrato per bloccare l'identità da un'unica immagine; in questo grafico viene applicato al caricamento del modello per garantire che il segnale dell'identità sia fuso alla base. Files
- LightX2V Step‑Distill LoRA (opzionale). Un adattatore leggero che può migliorare il comportamento guida e l'efficienza con Wan 2.1 14B. Model card
- Modulo VACE per Wan 2.1 (opzionale). Consente il controllo del movimento e dell'editing tramite condizionamento consapevole del video. Il flusso di lavoro include un percorso di incorporamento che puoi abilitare per il controllo VACE. Model hub
- Codificatore di testo UMT5‑XXL. Fornisce una robusta codifica di prompt multilingue per Wan 2.1 text‑to‑video. Model card
Come usare il flusso di lavoro Comfyui Wan2.1 Stand In#
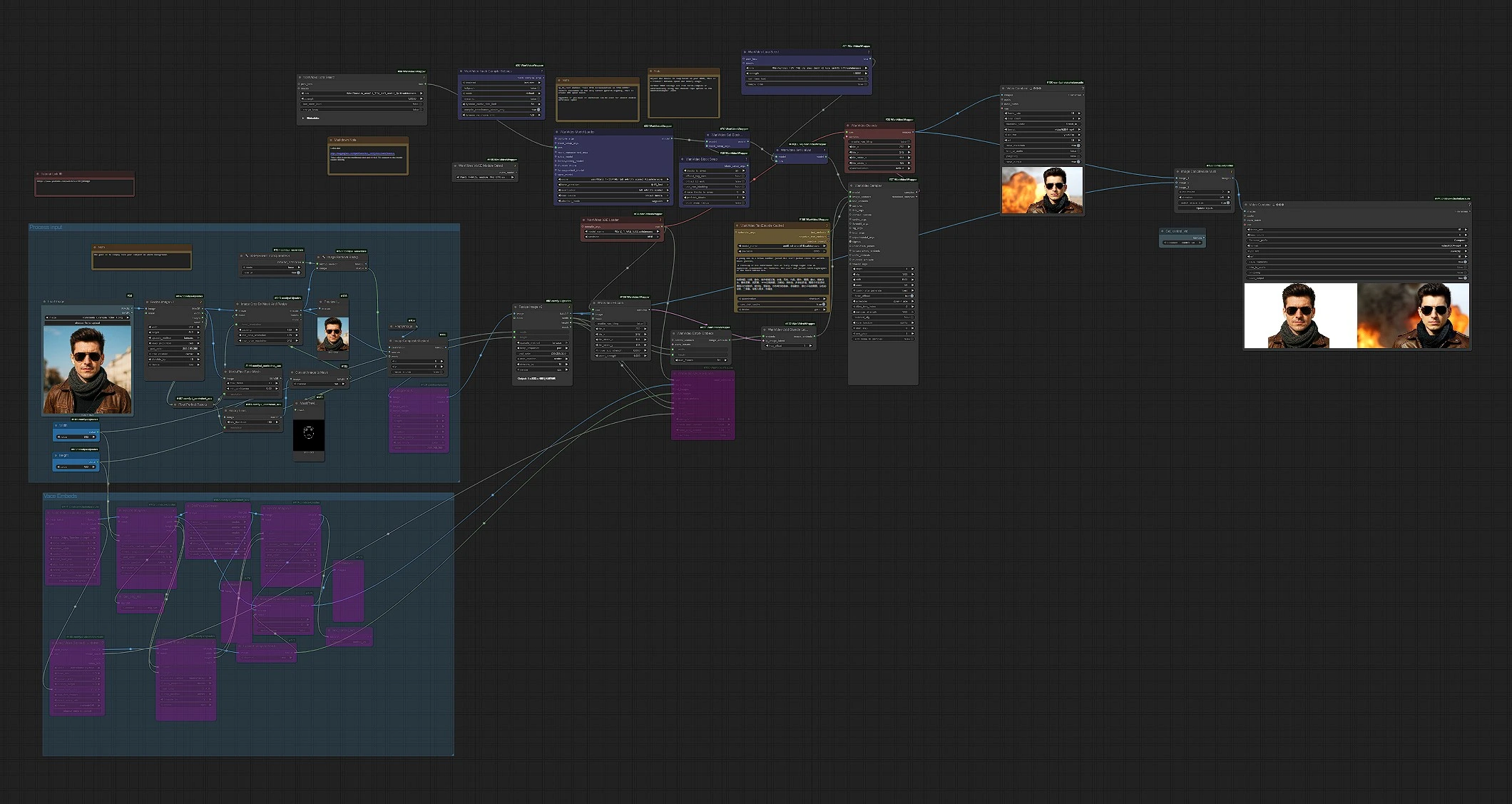
A colpo d'occhio: carica un'immagine di riferimento pulita e frontale, il flusso di lavoro prepara una maschera focalizzata sul volto e composita, la codifica in un latente, fonde quell'identità nelle incorporazioni delle immagini Wan 2.1, quindi campiona i fotogrammi video ed esporta MP4. Vengono salvati due output: il rendering principale e un confronto affiancato.
Processo input (gruppo)#
Inizia con un'immagine ben illuminata e frontale su uno sfondo semplice. La pipeline carica la tua immagine in LoadImage (#58), standardizza la dimensione con ImageResizeKJv2 (#142) e crea una maschera centrata sul volto usando MediaPipe-FaceMeshPreprocessor (#144) e BinaryPreprocessor (#151). Lo sfondo viene rimosso in TransparentBGSession+ (#127) e ImageRemoveBackground+ (#128), quindi il soggetto viene composto su una tela pulita con ImageCompositeMasked (#108) per minimizzare il sanguinamento dei colori. Infine, ImagePadKJ (#129) e ImageResizeKJv2 (#68) allineano l'aspetto per la generazione; il fotogramma preparato viene codificato in un latente tramite WanVideoEncode (#104).
VACE Embeds (gruppo opzionale)#
Se desideri il controllo del movimento da una clip esistente, caricala con VHS_LoadVideo (#161) e opzionalmente una guida secondaria o un video alfa con VHS_LoadVideo (#168). I fotogrammi passano attraverso DWPreprocessor (#163) per indizi di posa e ImageResizeKJv2 (#169) per il matching delle forme; ImageToMask (#171) e ImageCompositeMasked (#174) ti consentono di fondere immagini di controllo con precisione. WanVideoVACEEncode (#160) trasforma questi in incorporamenti VACE. Questo percorso è opzionale; lascialo intatto quando vuoi movimento guidato solo dal testo da Wan 2.1.
Modello, LoRAs e testo#
WanVideoModelLoader (#22) carica la base Wan 2.1 14B più lo Stand In LoRA in modo che l'identità sia integrata dall'inizio. Le funzionalità di velocità amichevoli per VRAM sono disponibili tramite WanVideoBlockSwap (#39) e applicate con WanVideoSetBlockSwap (#70). Puoi collegare un adattatore extra come LightX2V tramite WanVideoSetLoRAs (#79). I prompt sono codificati con WanVideoTextEncodeCached (#159), utilizzando UMT5‑XXL sotto il cofano per il controllo multilingue. Mantieni i prompt concisi e descrittivi; enfatizza l'abbigliamento, l'angolazione e l'illuminazione del soggetto per completare l'identità Stand In.
Incorporamento dell'identità e campionamento#
WanVideoEmptyEmbeds (#177) stabilisce la forma target per le incorporazioni delle immagini, e WanVideoAddStandInLatent (#102) inietta il tuo latente di riferimento codificato per trasportare l'identità nel tempo. Le incorporazioni combinate di immagini e testo vengono alimentate in WanVideoSampler (#27), che genera una sequenza video latente utilizzando il programmatore e i passaggi configurati. Dopo il campionamento, i fotogrammi vengono decodificati con WanVideoDecode (#28) e scritti in un MP4 in VHS_VideoCombine (#180).
Vista di confronto ed esportazione#
Per QA istantaneo, ImageConcatMulti (#122) impila i fotogrammi generati accanto al riferimento ridimensionato in modo da poter giudicare la somiglianza fotogramma per fotogramma. VHS_VideoCombine (#74) salva questo come un MP4 "Confronto" separato. Il flusso di lavoro Wan2.1 Stand In produce quindi un video finale pulito più un controllo affiancato senza sforzo extra.
Nodi chiave nel flusso di lavoro Comfyui Wan2.1 Stand In#
WanVideoModelLoader(#22). Carica Wan 2.1 14B e applica lo Stand In LoRA all'inizializzazione del modello. Mantieni l'adattatore Stand In collegato qui piuttosto che più avanti nel grafico in modo che l'identità sia applicata in tutto il percorso di denoising. Abbinalo aWanVideoVAELoader(#38) per il Wan‑VAE corrispondente.WanVideoAddStandInLatent(#102). Fondi il tuo latente di riferimento codificato nelle incorporazioni delle immagini. Se l'identità si sposta, aumenta la sua influenza; se il movimento sembra eccessivamente vincolato, riducilo leggermente.WanVideoSampler(#27). Il generatore principale. La messa a punto dei passaggi, la scelta del programmatore e la strategia di guida qui hanno il maggiore impatto sui dettagli, la ricchezza del movimento e la stabilità temporale. Quando spingi la risoluzione o la lunghezza, considera di regolare le impostazioni del campionatore prima di cambiare qualsiasi altra cosa a monte.WanVideoSetBlockSwap(#70) conWanVideoBlockSwap(#39). Scambia la memoria GPU per la velocità scambiando blocchi di attenzione tra i dispositivi. Se vedi errori di memoria esaurita, aumenta il trasferimento; se hai margine, riduci il trasferimento per iterazioni più rapide.ImageRemoveBackground+(#128) eImageCompositeMasked(#108). Questi garantiscono che il soggetto sia isolato in modo pulito e posizionato su una tela neutra, il che riduce la contaminazione del colore e migliora il blocco dell'identità Stand In nei fotogrammi.VHS_VideoCombine(#180). Controlla la codifica, il frame rate e la denominazione del file per l'output principale MP4. Usalo per impostare il tuo FPS e target di qualità preferiti per la consegna.
Extra opzionali#
- Usa un riferimento frontale e uniformemente illuminato su uno sfondo semplice per i migliori risultati. Piccole rotazioni o occlusioni pesanti possono indebolire il trasferimento dell'identità.
- Mantieni i prompt concisi; descrivi l'abbigliamento, l'umore e l'illuminazione che corrispondono al tuo riferimento. Evita descrittori facciali in conflitto che contrastano il segnale Wan2.1 Stand In.
- Se la VRAM è stretta, aumenta lo swapping dei blocchi o abbassa prima la risoluzione. Se hai margine, prova ad abilitare le ottimizzazioni di compilazione nella pila di caricamento prima di aumentare i passaggi.
- Lo Stand In LoRA è non standard e deve essere collegato al caricamento del modello; segui il modello in questo grafico per mantenere stabile l'identità. File LoRA: Stand‑In
- Per un controllo avanzato, abilita il percorso VACE per guidare il movimento con una clip guida. Inizia senza di esso se vuoi movimento guidato esclusivamente dal testo da Wan 2.1.
Risorse
- Wan 2.1 14B T2V: Hugging Face
- Wan 2.1 VACE: Hugging Face
- Stand In LoRA: Hugging Face
- LightX2V Step‑Distill LoRA: Hugging Face
- Codificatore UMT5‑XXL: Hugging Face
- Nodi wrapper WanVideo: GitHub
- Utilità KJNodes utilizzate per ridimensionare, imbottire e mascherare: GitHub
- Preprocessori ControlNet Aux (MediaPipe Face Mesh, DWPose): GitHub
Riconoscimenti#
Questo flusso di lavoro implementa e si basa sui lavori e risorse di ArtOfficial Labs. Ringraziamo sentitamente ArtOfficial Labs e gli autori di Wan 2.1 per Wan2.1 Demo per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione e ai repository originali collegati di seguito.
Risorse#
- Wan 2.1/Wan2.1 Demo
- Documenti / Note di rilascio: Wan2.1 Demo
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.

