

Stable Diffusion 3.5 VS FLUX.1#
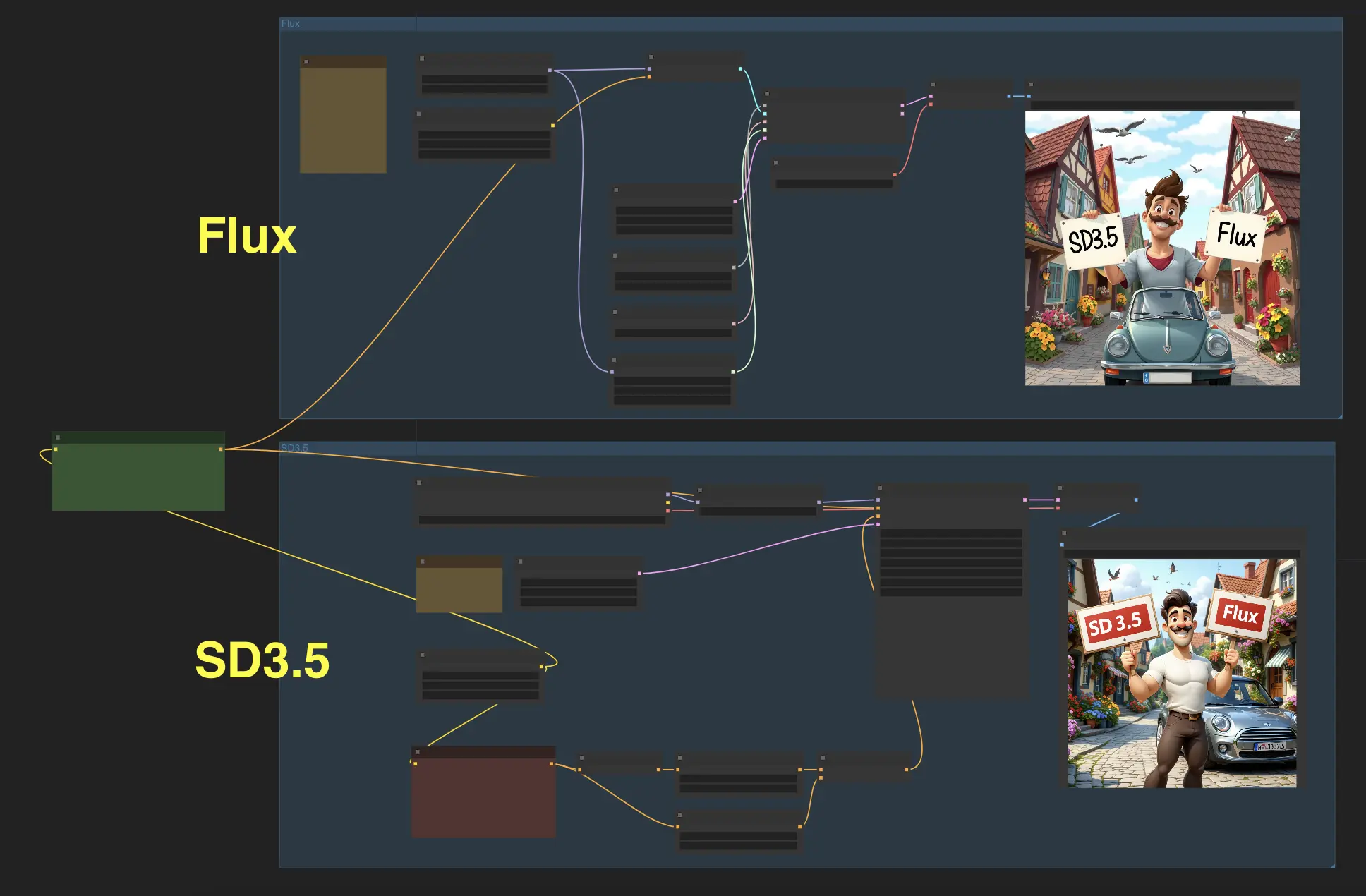
Preparati a testimoniare le capacità straordinarie di due modelli all'avanguardia: Stable Diffusion 3.5 (SD3.5) e FLUX.1. Con questo flusso di lavoro ComfyUI, ora puoi inserire un suggerimento di testo e generare immagini con questi due modelli simultaneamente, permettendoti di confrontare i risultati e scegliere quello che preferisci.
Abbiamo testato alcuni casi utilizzando SD3.5-large e Flux.1-schnell, e i risultati rivelano che Stable Diffusion 3.5 (SD3.5) e FLUX.1 eccellono ciascuno in diverse aree. Mentre FLUX.1 ha un vantaggio nella produzione di immagini fotorealistiche, SD3.5 dimostra maggiore abilità nel generare opere d'arte in stile anime senza richiedere ulteriori ritocchi o modifiche.
Non prendere solo la nostra parola per buona – sperimenta la magia tu stesso!





