
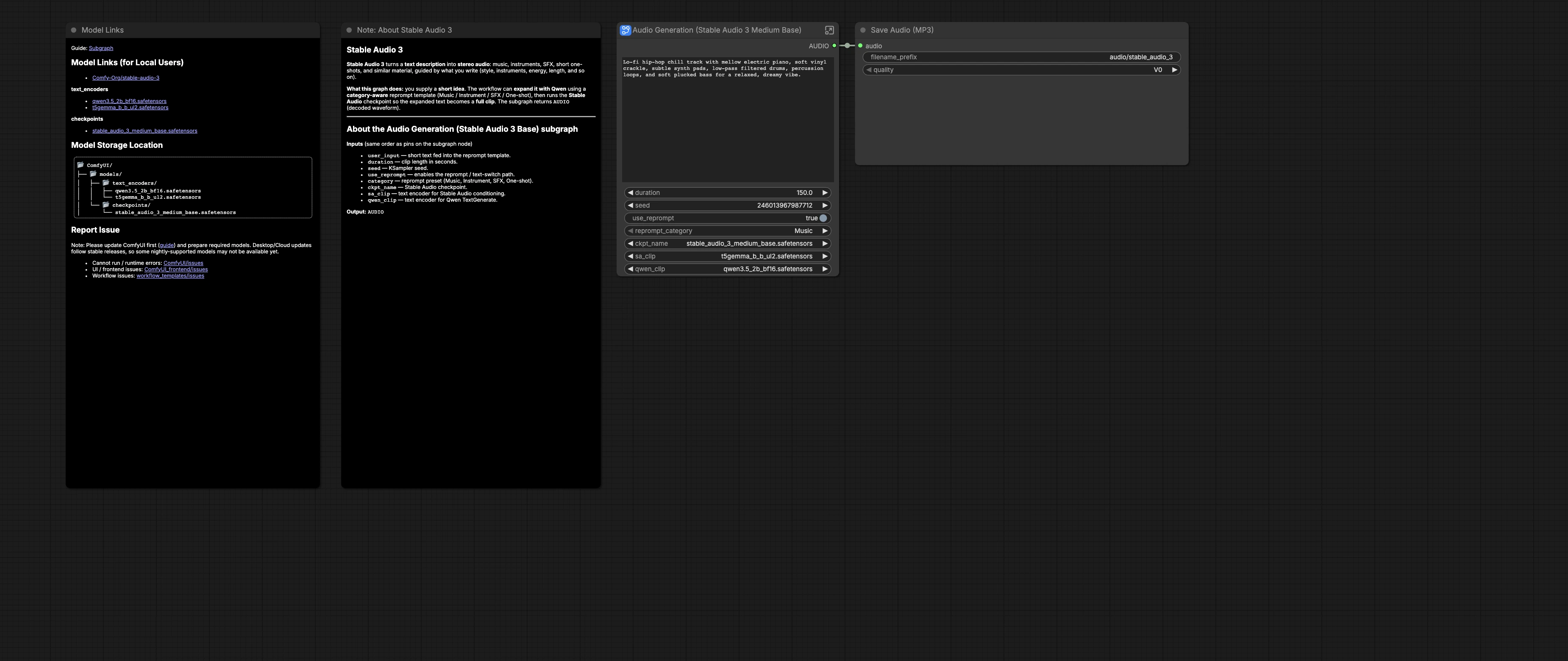
Workflow Stable Audio 3.0 Medium Base per testo-audio di lunga durata in ComfyUI#
Questo workflow Stable Audio 3.0 Medium Base trasforma brevi idee testuali in audio stereo più lungo e musicale. È costruito attorno al checkpoint stable_audio_3_medium_base con i codificatori di testo T5-Gemma e Qwen3.5 per fornire schizzi musicali guidati da prompt, letti ambientali, SFX e one-shot con impostazioni riproducibili in ComfyUI.
Il grafico include un sistema di riprompt opzionale consapevole della categoria che può espandere la tua breve idea in un prompt denso e pronto per la produzione prima della sintesi. Scegli la categoria, la durata e il seed, quindi la pipeline condiziona Stable Audio 3 e genera audio che viene salvato come MP3. Il workflow segue il modello ufficiale e le risorse fornite da Comfy-Org per Stable Audio 3.0 Medium Base. Vedi il modello di riferimento e i modelli su Comfy-Org/workflow_templates e Comfy-Org/stable-audio-3.
Modelli chiave nel workflow Comfyui Stable Audio 3.0 Medium Base#
- Checkpoint Stable Audio 3 Medium Base. Il modello generativo principale che sintetizza audio stereo a partire da condizionamenti testuali e latenti. Fonte: Comfy-Org/stable-audio-3.
- Codificatore di testo T5-Gemma Base UL2. Produce le embedding testuali utilizzate per condizionare Stable Audio 3 per prompt positivi e negativi. Il file del codificatore di testo confezionato è incluso nella cartella text_encoders del repository Stable Audio 3: Comfy-Org/stable-audio-3.
- Modello di testo Qwen3.5 2B. Alimenta il riprompt opzionale consapevole della categoria che espande una breve idea in una descrizione dettagliata di musica, strumenti, SFX o one-shot. Fonte: Comfy-Org/Qwen3.5.
Come usare il workflow Comfyui Stable Audio 3.0 Medium Base#
A un livello alto, fornisci una breve idea e una durata obiettivo. Il grafico può mantenere le tue parole così come sono o utilizzare Qwen3.5 per riscriverle tramite un modello di categoria. Il risultato viene codificato per il condizionamento, campionato da Stable Audio 3, decodificato in audio e salvato.
Input dell'utente: prompt e durata#
Il sottografo Audio Generation (Stable Audio 3 Medium Base) (#52) espone user_input, duration, seed, use_reprompt e category. Scrivi una breve idea in linguaggio semplice, come uno stile, un elenco di strumenti, un mood e un BPM opzionale. Scegli una lunghezza del clip in secondi e imposta un seed per la riproducibilità o la variazione. Attiva use_reprompt quando vuoi la riscrittura guidata dal modello, quindi seleziona una category come Musica, Strumento, SFX o One-shot.
Caricatori: checkpoint e codificatori di testo#
CheckpointLoaderSimple (#25) carica stable_audio_3_medium_base.safetensors, fornendo il MODEL e il VAE usati in seguito per il campionamento e la decodifica. CLIPLoader (#26) carica il codificatore T5-Gemma usato per il condizionamento. Un secondo CLIPLoader (#29) carica il modello Qwen3.5 che guida la fase di riprompt.
Riprompt: modelli JSON e categoria#
Un selettore di categoria CustomCombo (#43) alimenta un grande JSON di prompt di sistema in JsonExtractString (#49). Il modello selezionato viene inserito in un meta-prompt da Text Replace (PROMPT TEMPLATE) (#38). Il tuo user_input viene iniettato da Text Replace (USER INPUT) (#39), e la lunghezza obiettivo viene inserita usando Text Replace (AUDIO LENGTH) (#40), mantenendo la riscrittura allineata con la durata scelta.
Riprompt: Qwen TextGenerate#
TextGenerate (#28) utilizza Qwen3.5 per trasformare il modello assemblato più la tua idea in un prompt conciso e dettagliato che segue regole specifiche della categoria. Questa fase è particolarmente utile per strutture musicali più lunghe e per SFX dove il linguaggio tecnico concreto è importante. La riscrittura del prompt è visualizzabile in anteprima, quindi puoi iterare rapidamente sulla scelta della categoria e della formulazione.
Passaggio tra testo originale e riscritto#
ComfySwitchNode (#34) seleziona il tuo testo originale o la riscrittura generata da Qwen in base a use_reprompt. Lascialo attivo per ottenere prompt strutturati e consapevoli della lunghezza, o disattivalo quando vuoi un controllo letterale sulla formulazione. Questo semplice interruttore rende il test A/B semplice.
Codifica CLIP: condizionamento#
CLIPTextEncode (#6) converte il prompt selezionato nel condizionamento positivo che guida il modello. Un secondo CLIPTextEncode (#7) fornisce un condizionamento negativo neutro di default. Questo accoppiamento fornisce a Stable Audio 3 una guida chiara evitando artefatti indesiderati.
Generazione audio: Stable Audio#
EmptyLatentAudio (#11) crea un audio latente la cui lunghezza corrisponde a duration. KSampler (#3) esegue il processo di denoising utilizzando il MODEL Stable Audio 3 Medium Base dal checkpoint. VAEDecodeAudio (#12) trasforma il latente finale in una forma d'onda stereo udibile. Poiché la stessa duration informa anche il riprompt, la lunghezza del clip reso e il testo riscritto rimangono sincronizzati.
Salva ed esporta#
Fuori dal sottografo, SaveAudioMP3 (#19) scrive il risultato in un file MP3 con un prefisso utile per l'organizzazione. Usa questo quando generi batch con diversi valori di seed o categorie, quindi ascolta e conserva i tuoi preferiti.
Nodi chiave nel workflow Comfyui Stable Audio 3.0 Medium Base#
ComfySwitchNode(#34). Alterna tra il tuouser_inputoriginale e il testo generato da Qwen. Attivalo per riscritture strutturate e corrispondenti alla lunghezza o disattivalo per un controllo diretto.TextGenerate(#28). Esegue Qwen3.5 con un prompt di sistema specifico per categoria per espandere le idee. Per personalizzare lo stile di riscrittura, modifica i modelli di categoria inJsonExtractString(#49) e i prompt di connessione nei nodiText Replaceadiacenti.EmptyLatentAudio(#11). Imposta la lunghezza del clip. Mantieni questo allineato con il tokenAUDIO_LENGTHinserito in modo che il tempo di sintesi corrisponda all'intento testuale.KSampler(#3). Governa la traiettoria di denoising per Stable Audio 3. Regola ilseedper variazioni mantenendo stabili le altre impostazioni per confrontare equamente i risultati.SaveAudioMP3(#19). Controlla il prefisso del nome file di output e il formato per una rapida costruzione della libreria da più esecuzioni.
Extra opzionali#
- Inizia con un'idea di una o due frasi che nomina il genere o la fonte, gli strumenti chiave o le texture e il mood. Il riprompt può riempire dettagli come BPM e arrangiamento.
- Scegli la categoria che corrisponde al tuo obiettivo: Musica per tracce complete, Strumento per loop o stem, SFX per ambienti e azioni, One-shot per colpi isolati.
- Mantieni la durata realistica per il tuo contenuto target. Clip molto lunghi sono più pesanti da calcolare e potrebbero beneficiare di un
seedstabile mentre iteri. - Quando i risultati sembrano affollati, disattiva il riprompt e prova una frase più semplice, quindi riattivalo una volta che ti piace la direzione.
- Per take alternativi veloci, mantieni tutto costante e cambia solo il
seed.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo Comfy-Org per l'articolo di supporto ComfyUI Stable Audio 3 Day-0, Comfy-Org per il modello ufficiale di workflow Stable Audio 3.0 Medium Base, Comfy-Org per i file del modello Stable Audio 3 e Comfy-Org per i file del modello di codificatore Qwen3.5 per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Comfy-Org/ComfyUI Stable Audio 3 Day-0 Support Article
- Documenti / Note di rilascio: Stable Audio 3 Day-0 Support
- Comfy-Org/Official Stable Audio 3.0 Medium Base Workflow Template
- GitHub: Comfy-Org/workflow_templates
- Comfy-Org/Stable Audio 3 Model Files
- Hugging Face: Comfy-Org/stable-audio-3
- Comfy-Org/Qwen3.5 Encoder Model Files
- Hugging Face: Comfy-Org/Qwen3.5
Nota: L'uso dei modelli, dei dataset e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.
