
⚠️ Nota importante: Questa implementazione ComfyUI di MultiTalk attualmente supporta SOLO la generazione di una SINGOLA PERSONA. Le funzionalità di conversazione multi-persona saranno disponibili a breve.
1. Cos'è MultiTalk?#
MultiTalk è un framework rivoluzionario per la generazione di video conversazionali multi-persona basati sull'audio, sviluppato da MeiGen-AI. A differenza dei metodi tradizionali di generazione di teste parlanti che animano solo i movimenti facciali, la tecnologia MultiTalk può generare video realistici di persone che parlano, cantano e interagiscono mantenendo una sincronizzazione labiale perfetta con l'input audio. MultiTalk trasforma foto statiche in video parlanti dinamici facendo parlare o cantare la persona esattamente come desideri.
2. Come funziona MultiTalk#
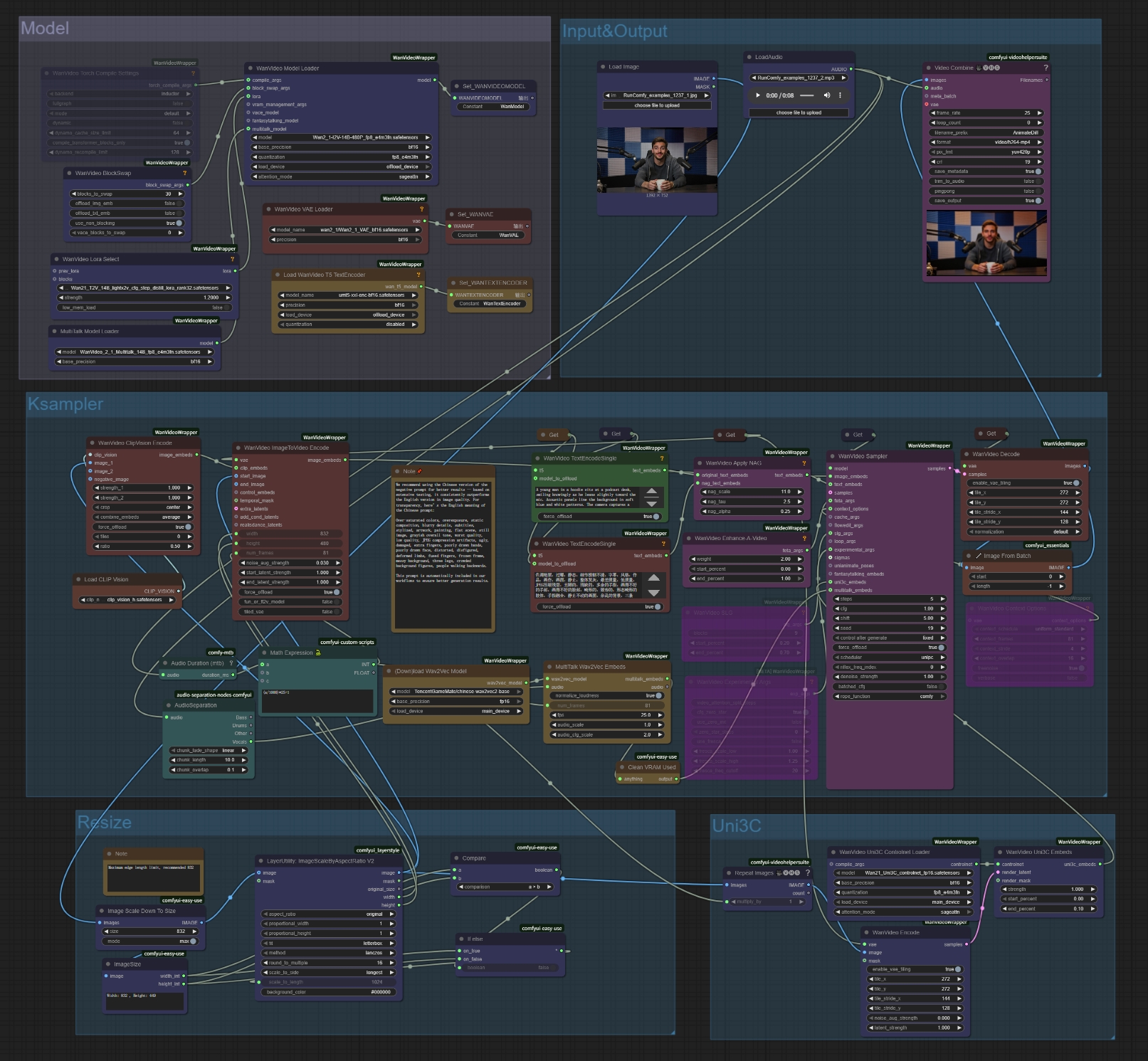
MultiTalk sfrutta tecnologia AI avanzata per comprendere sia i segnali audio che le informazioni visive. L'implementazione ComfyUI di MultiTalk combina MultiTalk + Wan2.1 + Uni3C per risultati ottimali:
Analisi audio: MultiTalk utilizza un potente encoder audio (Wav2Vec) per comprendere le sfumature del parlato, inclusi ritmo, tono e modelli di pronuncia.
Comprensione visiva: Costruito sul robusto modello di diffusione video Wan2.1, MultiTalk comprende l'anatomia umana, le espressioni facciali e i movimenti corporei (puoi visitare il nostro workflow Wan2.1 per la generazione t2v/i2v).
Controllo fotocamera: MultiTalk con Uni3C controlnet consente movimenti sottili della fotocamera e controllo della scena, rendendo il video più dinamico e professionale. Scopri il nostro workflow Uni3C per creare bellissimi trasferimenti di movimento della fotocamera.
Sincronizzazione perfetta: Attraverso sofisticati meccanismi di attenzione, MultiTalk impara ad allineare perfettamente i movimenti labiali con l'audio mantenendo espressioni facciali e linguaggio corporeo naturali.
Seguire le istruzioni: A differenza dei metodi più semplici, MultiTalk può seguire prompt testuali per controllare la scena, la posa e il comportamento generale mantenendo la sincronizzazione audio.
3. Vantaggi di ComfyUI MultiTalk#
- Sincronizzazione labiale di alta qualità: MultiTalk raggiunge una precisione al millisecondo nella sincronizzazione labiale, particolarmente impressionante per gli scenari di canto
- Creazione di contenuti versatile: MultiTalk supporta sia la generazione di parlato che di canto con vari tipi di personaggi, inclusi personaggi cartoon
- Risoluzione flessibile: MultiTalk genera video in 480P o 720P con rapporti d'aspetto arbitrari
- Supporto video lunghi: MultiTalk crea video fino a 15 secondi di lunghezza
- Seguire le istruzioni: MultiTalk controlla le azioni dei personaggi e le impostazioni della scena tramite prompt testuali
4. Come usare il workflow ComfyUI MultiTalk#
Guida passo-passo all'uso di MultiTalk#
Passo 1: Preparare gli input di MultiTalk
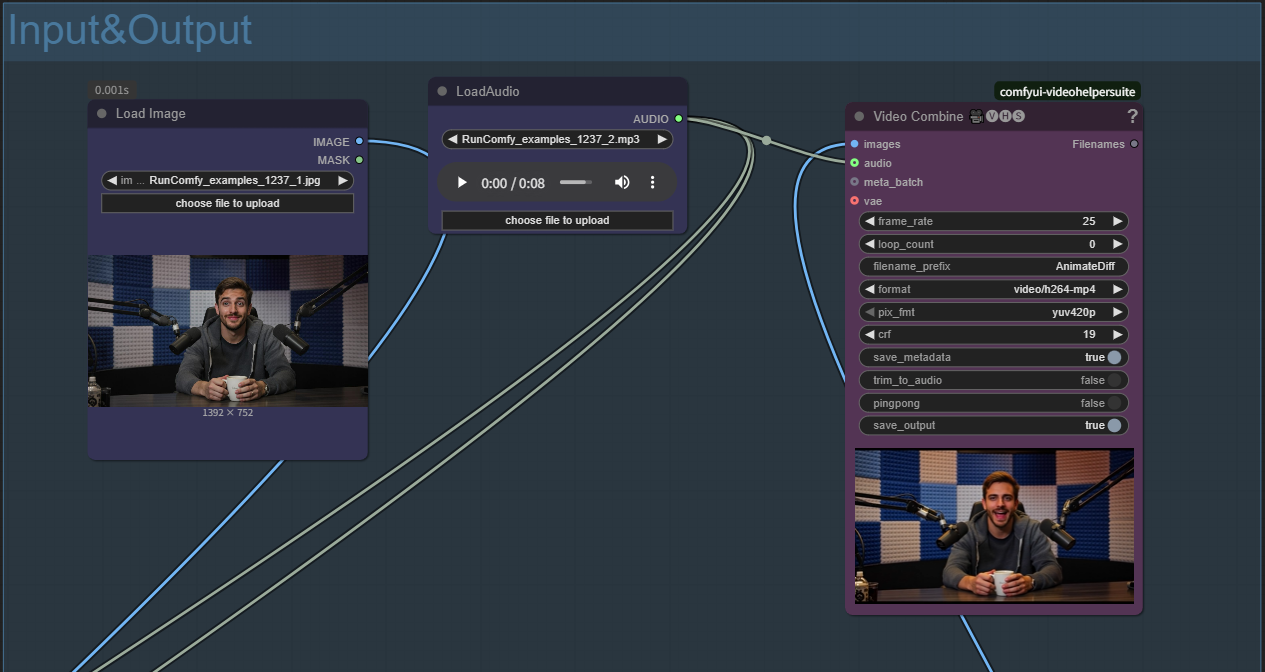
- Carica immagine di riferimento: Clicca "choose file to upload" nel nodo Load Image
- Usa foto chiare e frontali per i migliori risultati MultiTalk
- L'immagine verrà automaticamente ridimensionata alle dimensioni ottimali (832px consigliato)
- Carica file audio: Clicca "choose file to upload" nel nodo LoadAudio
- MultiTalk supporta vari formati audio (WAV, MP3, ecc.)
- Parlato/canto chiaro funziona meglio con MultiTalk
- Per creare canzoni personalizzate, considera l'uso del nostro workflow di generazione musicale Ace-Step, che produce musica di alta qualità con testi sincronizzati.
- Scrivi prompt testuale: Descrivi la scena desiderata nei nodi di codifica testo per la generazione MultiTalk
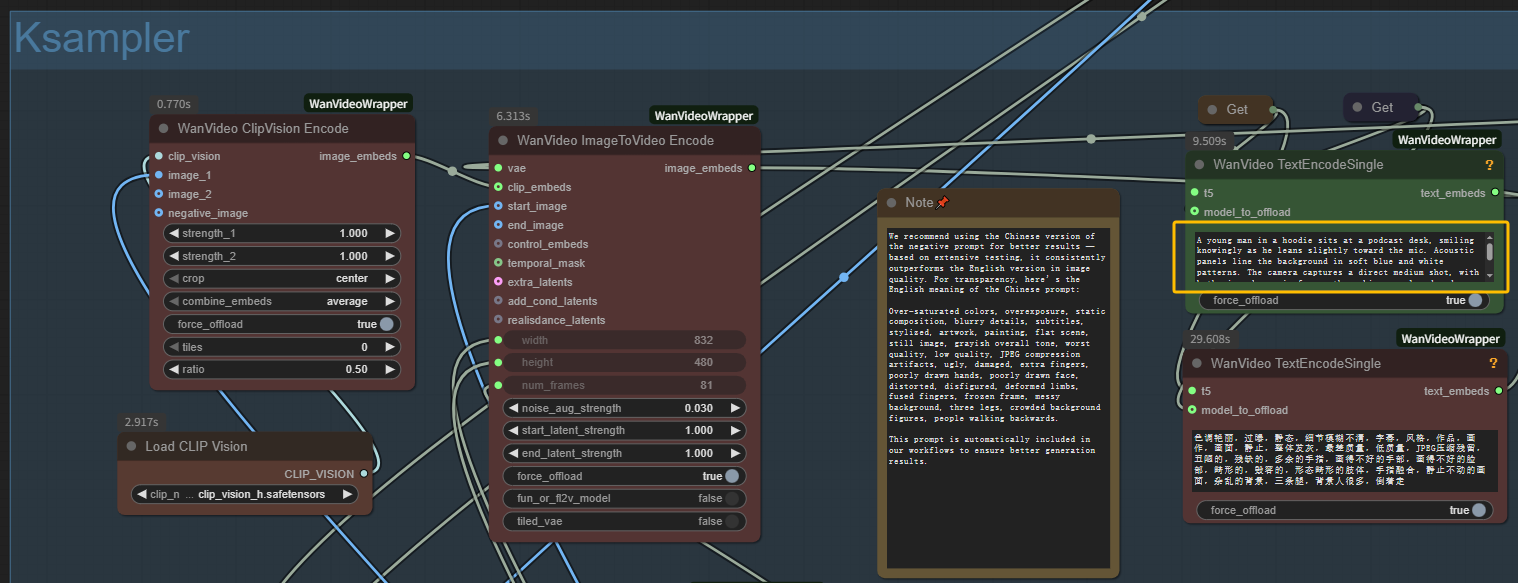
Passo 2: Configura le impostazioni di generazione MultiTalk
- Passi di campionamento: 20-40 passi (più alto = migliore qualità MultiTalk, generazione più lenta)
- Audio Scale: Mantieni a 1.0 per una sincronizzazione labiale MultiTalk ottimale
- Embed Cond Scale: 2.0 per un condizionamento audio MultiTalk bilanciato
- Controllo fotocamera: Abilita Uni3C per movimenti sottili, o disabilita per riprese MultiTalk statiche
Passo 3: Miglioramenti opzionali di MultiTalk
- Accelerazione LoRA: Abilita per una generazione MultiTalk più veloce con perdita di qualità minima
- Miglioramento video: Usa nodi di miglioramento per il post-processing MultiTalk
- Prompt negativi: Aggiungi elementi indesiderati da evitare nell'output MultiTalk (sfocato, distorto, ecc.)
Passo 4: Genera con MultiTalk
- Metti in coda il prompt e attendi la generazione MultiTalk
- Monitora l'utilizzo della VRAM (48GB consigliati per MultiTalk)
- Tempo di generazione MultiTalk: 7-15 minuti a seconda delle impostazioni e dell'hardware
5. Ringraziamenti#
Ricerca originale: MultiTalk è sviluppato da MeiGen-AI con la collaborazione di ricercatori leader nel campo. Il paper originale "Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation" presenta la ricerca rivoluzionaria dietro questa tecnologia.
Integrazione ComfyUI: L'implementazione ComfyUI è fornita da Kijai tramite il repository ComfyUI-WanVideoWrapper, rendendo questa tecnologia avanzata accessibile alla più ampia comunità creativa.
Tecnologia di base: Costruito sul modello di diffusione video Wan2.1 e incorpora tecniche di elaborazione audio da Wav2Vec, rappresentando una sintesi della ricerca AI all'avanguardia.
6. Link e risorse#
- Ricerca originale: MeiGen-AI MultiTalk Repository
- Pagina del progetto: https://meigen-ai.github.io/multi-talk/
- Integrazione ComfyUI: ComfyUI-WanVideoWrapper


