
LTX-2 First Last Frame: generazione video controllata da inizio a fine, sincronizzata con l'audio in ComfyUI#
LTX-2 First Last Frame è un workflow di ComfyUI per creatori che desiderano un movimento cinematografico preciso tra un fotogramma iniziale definito e un fotogramma finale mentre generano audio e visuali sincronizzati in un unico passaggio. Condizionando su entrambe le immagini (e opzionalmente un fotogramma centrale guida), la pipeline preserva identità, inquadratura e illuminazione lungo lo scatto, quindi guida il movimento per atterrare esattamente sul fotogramma finale. È progettato per battute narrative, transizioni di titolo o scena, movimenti di camera e qualsiasi momento in cui continuità temporale e allineamento audio contano.
Alimentato dal modello in tempo reale LTX-2, il workflow mantiene veloce l'iterazione offrendo un controllo fine su prompt, comportamento della camera tramite LoRAs e forza del primo/ultimo fotogramma. Il risultato è una sequenza fluida e coerente il cui tempismo, aspetto e suono seguono le tue indicazioni dal primo fotogramma all'ultimo.
Nota: Per i tipi di macchina inferiori a 2x Large, si prega di utilizzare il modello "ltx-2-19b-dev-fp8.safetensors" !
Modelli chiave nel workflow Comfyui LTX-2 First Last Frame#
- LTX-2 19B (dev). Il modello principale di generazione video che produce latenti audio-video congiunti da testo e controlli dei fotogrammi; supporta iterazione in tempo reale e LoRAs consapevoli della camera. Vedi il repository ufficiale e i pesi: Lightricks/LTX-2 su GitHub e Lightricks/LTX-2 su Hugging Face.
- Gemma 3 12B Instruct text encoder per LTX-2. Fornisce una robusta comprensione del linguaggio sintonizzata per istruzioni per il prompting visivo e audio in questa pipeline; confezionata per ComfyUI come encoder di testo compatibile con LTX. Riferimento ai pesi: Comfy-Org/ltx-2 split text encoders.
- LTXV Audio VAE (vocoder a 24 kHz). Codifica e decodifica latenti audio in modo che la colonna sonora sia generata insieme al video e rimanga sincronizzata con l'azione su schermo. Vedi il contesto della famiglia di modelli in Lightricks/LTX-2.
- LTX-2 Spatial Upscaler x2. Uno scaler latente per risultati ad alta risoluzione più puliti dopo il passaggio base, utilizzato durante la fase di campionamento di ingrandimento. I pesi sono disponibili sotto Lightricks/LTX-2.
- Pacchetto LTX-2 LoRA per controllo della camera e dettaglio. LoRAs opzionali come Dolly In/Out/Left/Right, Jib Up/Down, Static, e un Image-Conditioning Detailer modellano il movimento della camera e il dettaglio fine. Sfoglia la collezione ufficiale: Lightricks LTX-2 LoRAs.
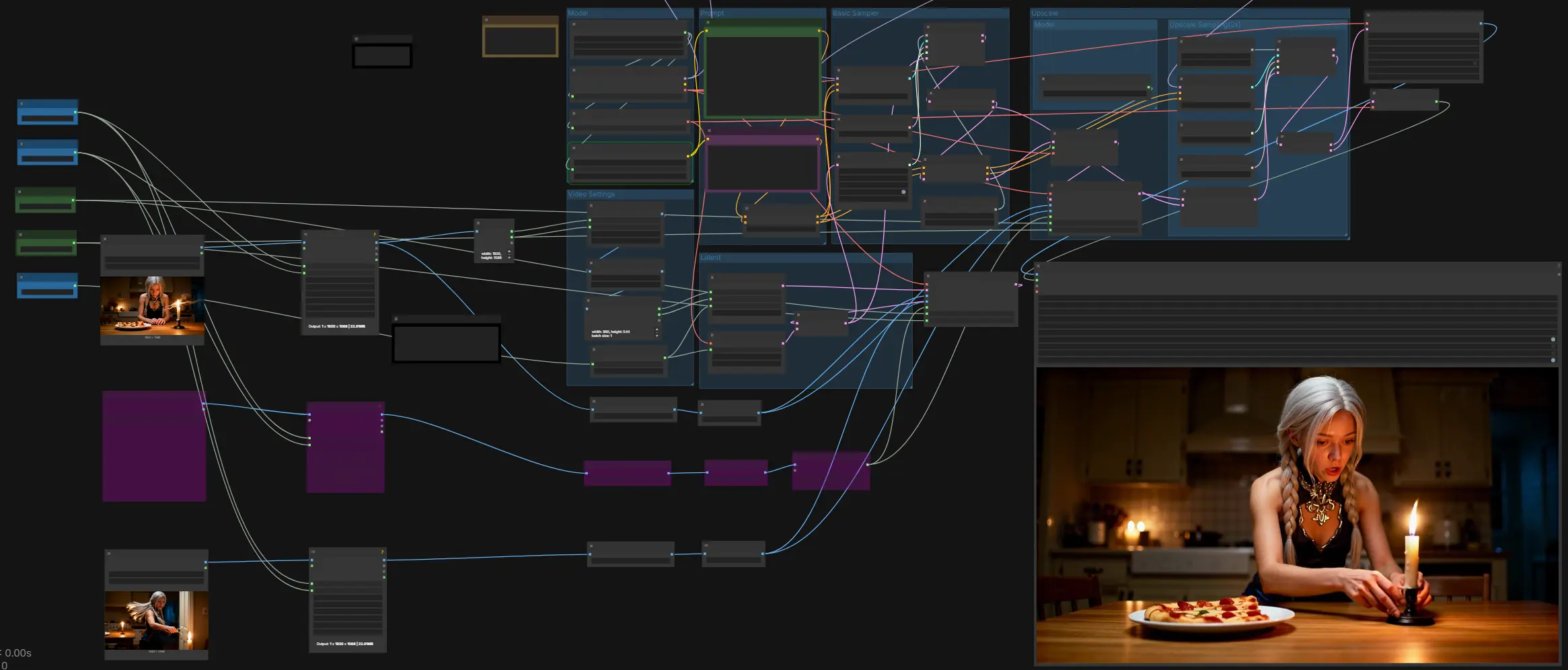
Come utilizzare il workflow Comfyui LTX-2 First Last Frame#
Questo workflow si muove da input e prompt a un campione base audio-video, quindi esegue un passaggio di ingrandimento guidato 2x prima di decodificare e muxare in MP4 con audio. Si basa su controlli del primo/ultimo fotogramma sia nelle fasi base che di ingrandimento, con un fotogramma centrale opzionale per stabilizzare la traiettoria.
Modello#
Il gruppo Modello carica il checkpoint LTX-2, l'encoder di testo Gemma 3 12B Instruct, e l'LTXV Audio VAE. Usa il pannello ckpt_name per selezionare tra le varianti standard e FP8 in base alla tua GPU. L'encoder di testo è fornito da LTXAVTextEncoderLoader e alimenta sia i prompt positivi che negativi. L'audio VAE abilita la generazione audio-video congiunta in modo che dialoghi, effetti o ambienti descritti nel prompt emergano con i visuali.
Prompt#
Scrivi la scena nel prompt positivo e elenca tratti indesiderabili nel prompt negativo. Descrivi azioni nel tempo, specifiche visive chiave ed eventi sonori nell'ordine in cui dovrebbero verificarsi. Il blocco LTXVConditioning applica il tuo prompt insieme al frame rate scelto in modo che tempistica e movimento siano interpretati in modo coerente. Considera l'audio parte del prompt quando hai bisogno di discorsi, effetti o ambienti.
Impostazioni Video#
Imposta Width, Height, e il totale dei Video Frames, quindi scegli Length per la spaziatura del controllo primo/ultimo se necessario. Il workflow garantisce che le dimensioni corrispondano ai requisiti del modello e scala gli input in modo appropriato. Se le tue immagini di input sono più grandi, il grafico legge la loro dimensione per inizializzare la tela latente e ridimensiona i fotogrammi forniti per adattarsi. Scegli un frame rate che corrisponda alla tua consegna prevista.
Latente#
Questo gruppo costruisce un video latente vuoto e un audio latente corrispondente, poi li concatena in modo che il modello campioni audio e video insieme. È qui che la guida del primo/ultimo fotogramma è prima iniettata nel passaggio base. Fornire un fotogramma centrale è opzionale ma utile per stabilizzare l'identità o la posa chiave a metà scatto. Il risultato è un singolo AV latente pronto per il campionamento base.
Campionatore Base#
Il passaggio base utilizza rumore casuale, uno scheduler, e il guider configurato per risolvere il tuo prompt in un latente AV coerente. Il guider riceve condizionamento positivo e negativo più qualsiasi modello modificato da LoRA. Dopo il campionamento, il latente è diviso in video e audio in modo che il video possa essere ingrandito mentre l'audio rimane allineato. Questa fase imposta il movimento globale, il ritmo, e il ritmo audio che il passaggio di ingrandimento affinerà.
Ingrandimento#
L'ingranditore solleva il latente a una risoluzione spaziale più alta prima di un secondo passaggio di campionamento. Il controllo del primo/ultimo fotogramma è riapplicato a questa risoluzione più alta per bloccare i fotogrammi di apertura e chiusura con precisione. Puoi anche fornire un fotogramma centrale qui per mantenere stabili le caratteristiche attraverso l'ingrandimento. Il risultato è un AV latente più nitido che preserva il movimento pianificato.
Modello#
Questo gruppo Modello carica l'ingranditore latente LTX-2 utilizzato dal gruppo di Ingrandimento. Prepara il modello spaziale x2 specifico e lo espone al nodo upsampler latente. Cambia modelli qui se mantieni più ingranditori. Lascia questo gruppo intatto se sei soddisfatto del comportamento predefinito x2.
Campionamento di Ingrandimento (2x)#
Il secondo passaggio esegue il campionamento guidato sul latente ingrandito utilizzando un campionatore separato e un programma sigma. Una guida consapevole del ritaglio allinea il condizionamento alla nuova risoluzione in modo che i dettagli rimangano coerenti. L'output è diviso di nuovo in video e audio per la decodifica. Questo passaggio affina principalmente i bordi, migliora piccoli testi o texture, e mantiene la corrispondenza del primo/ultimo fotogramma.
LTX-2-19b-IC-LoRA-Detailer#
Questo gruppo applica un LoRA orientato al dettaglio sintonizzato per il percorso di condizionamento delle immagini di LTX-2. Abilitalo quando desideri più micro-dettagli o texture più strette dopo il condizionamento su immagini reali. Mantieni la forza moderata per evitare di sopraffare il tuo prompt o i vincoli dei fotogrammi. Se i tuoi input sono già nitidi e ben illuminati, puoi bypassare questo LoRA.
Controllo-Camera-Dolly-In#
Usa questo LoRA quando la camera dovrebbe spingere verso il soggetto nel tempo. Tende il modello verso il movimento in avanti rispettando i target primo/ultimo. Abbinalo a suggerimenti testuali che descrivono il movimento per l'effetto più forte. Riduci la forza se il movimento supera il tuo inquadramento previsto.
Controllo-Camera-Dolly-Out#
Seleziona questo quando la ripresa dovrebbe allontanarsi dal soggetto. Aiuta a creare parallasse negativa e contesto in ampliamento man mano che la sequenza progredisce. Mantieni l'ultimo fotogramma allineato con la tua composizione di uscita per atterrare il movimento in modo pulito. Combina con prompt audio atmosferici per rivelazioni cinematografiche.
Controllo-Camera-Dolly-Left#
Applica un movimento laterale a sinistra che si legge come un dolly o un truck. Buono per battute conversazionali o rivelazioni attraverso un set. Se gli oggetti si sbavano o si spostano, aumenta leggermente la forza del primo/ultimo o aggiungi un fotogramma centrale. Bilancia con piccoli suggerimenti testuali come "movimento lento a sinistra" per completare il LoRA.
Controllo-Camera-Dolly-Right#
Lo specchio di Dolly-Left, questo tende il movimento verso il lato destro. Funziona bene per seguire un personaggio o panoramizzare su un nuovo soggetto. Mantieni la forza del LoRA modesta se richiedi anche un push-in per evitare segnali contrastanti. Assicurati che la composizione dell'ultimo fotogramma corrisponda al tuo punto finale desiderato.
Controllo-Camera-Jib-Up#
Crea una salita verticale, utile per rivelazioni di sollevamento o scatti di stabilimento. Combina con prompt superficiali sul cambiamento di prospettiva e cambiamento dell'orizzonte per chiarezza. Quando il movimento è forte, osserva i soffitti o l'esposizione del cielo; modifica il prompt negativo per evitare punti salienti bruciati. Se necessario, aggiungi un fotogramma centrale che mostri l'inquadratura a metà salita.
Controllo-Camera-Jib-Down#
Produce una discesa controllata, spesso usata per stabilirsi su un dettaglio o un personaggio. Può essere abbinata a un letto audio più tranquillo per enfasi. Assicurati che l'ultimo fotogramma contenga l'oggetto o il volto target in modo che il movimento si risolva in modo decisivo. Regola la forza del LoRA se la discesa sembra troppo veloce.
Controllo-Camera-Static#
Blocca la camera virtuale in posizione quando desideri azione senza movimento della camera. Questo è utile per dialoghi o riprese di prodotto dove solo il soggetto si muove. Combina con il controllo del primo/ultimo fotogramma per mantenere la composizione perfettamente stabile. Aggiungi movimento sottile tramite il prompt di testo piuttosto che un LoRA della camera.
Nodi chiave nel workflow Comfyui LTX-2 First Last Frame#
LTXVFirstLastFrameControl_TTP (#227)#
Inietta vincoli di immagine primo e ultimo nel latente AV base. Regola first_strength per controllare quanto strettamente il primo fotogramma è abbinato e last_strength per determinare quanto duramente la sequenza atterra sul fotogramma finale. Se la metà del clip deriva, fornisci un fotogramma centrale tramite LTXVMiddleFrame_TTP e mantieni le forze moderate per evitare di sovra-vincolare il movimento.
LTXVMiddleFrame_TTP (#181)#
Inserisce opzionalmente un fotogramma guida a una posizione scelta tra inizio e fine per stabilizzare identità o posa. Aumenta strength quando il soggetto cambia troppo a metà scatto. Usa con parsimonia; i migliori risultati provengono da un singolo, ben scelto riferimento centrale piuttosto che da molti vincoli concorrenti.
LTXVLatentUpsampler (#217)#
Esegue l'ingrandimento spaziale x2 nello spazio latente utilizzando l'ingranditore spaziale LTX-2. Usalo prima del passaggio di campionamento 2x in modo che i dettagli ad alta risoluzione siano affinati dal modello piuttosto che allungati. Se la memoria è stretta, mantieni l'uso del LoRA minimo durante questa fase.
LTXVFirstLastFrameControl_TTP (#223)#
Riapplica la guida di inizio/fine (e opzionale centrale) dopo l'ingrandimento x2. Questo assicura che i fotogrammi decodificati finali corrispondano esattamente alle tue referenze di primo e ultimo a risoluzione di consegna. Se l'ingrandimento introduce micro spostamenti, aumenta leggermente last_strength qui piuttosto che nella fase base.
LTXVSpatioTemporalTiledVAEDecode (#230)#
Decodifica il video latente ad alta risoluzione in fotogrammi utilizzando il tiling spatio-temporale. Regola le impostazioni di tile e overlap solo quando vedi cuciture o sfarfallio temporale; un overlap maggiore costa più VRAM ma migliora la coerenza. Mantieni last_frame_fix per casi limite in cui il fotogramma finale mostra un leggero deriva.
VHS_VideoCombine (#254)#
Muxa i fotogrammi decodificati e l'audio generato in un unico MP4. Imposta format, pix_fmt, e crf per il tuo target di consegna, e scegli un frame_rate coerente con il condizionamento. Abilita il salvataggio dei metadati per mantenere i record di riproducibilità con ogni rendering.
Extra opzionali#
- Usa pesi FP8 di LTX-2 se la tua GPU è limitata; torna alla piena precisione per la massima fedeltà quando la VRAM lo consente. I pesi sono in Lightricks/LTX-2.
- Le dimensioni funzionano meglio quando larghezza e altezza sono della forma 32n + 1; i fotogrammi totali funzionano meglio come 8n + 1. Il workflow corregge automaticamente ai valori validi più vicini se necessario.
- Descrivi i cue audio direttamente nel tuo prompt positivo (dialoghi, effetti, ambienti). Il latente AV congiunto del modello mantiene labbra, azioni e suoni allineati.
- Inizia con forze moderate del primo/ultimo; aumenta la forza dell'ultimo per inchiodare la posa finale, o aggiungi un fotogramma centrale per stabilizzare l'identità.
- Applica solo un LoRA della camera alla volta per un'intenzione chiara. Sfoglia le opzioni ufficiali nella collezione Lightricks LTX-2 LoRA.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo @AIKSK per il riferimento al workflow LTX-2 First Last Frame per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- RunningHub/LTX-2 First Last Frame Workflow Reference
- Documenti / Note di Rilascio: LTX-2 First Last Frame Workflow Reference from AIKSK
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.
