
LTX-2 ControlNet: generazione video guidata dalla struttura e sincronizzata con l'audio in ComfyUI#
LTX-2 ControlNet è un workflow ComfyUI basato sul controllo per l'estensione ComfyUI-LTXVideo che ti permette di guidare la generazione di video LTX-2 con guida di profondità, bordi canny e pose mantenendo audio e video in sincronia. Funziona in uno spazio latente audio-visivo unificato, quindi discorsi, effetti sonori e movimenti sono generati insieme e rimangono allineati dal primo all'ultimo frame.
Progettato per testo a video, immagine a video e video a video, il workflow aggiunge il condizionamento ControlNet basato su IC LoRA per un controllo preciso del layout e del movimento, l'inizializzazione del primo frame per la continuità della scena e una pipeline a due stadi con ingrandimento latente per risultati nitidi senza sovraccaricare il VRAM. LTX-2 ControlNet è completamente aperto, veloce da iterare e orientato alla produzione per i creatori che necessitano di output ripetibili e di alta qualità.
Modelli chiave nel workflow Comfyui LTX-2 ControlNet#
- LTX-2 19B (dev FP8 e distillato). Modello generativo audio-visivo principale utilizzato per campionare video e audio in un unico spazio latente. Model family
- Gemma 3 12B IT text encoder. Fornisce una robusta comprensione del linguaggio per prompt e negativi tramite l'encoder confezionato utilizzato da LTX-2. Encoder file
- LTX-2 Spatial Upscaler x2. Modello di ingrandimento latente utilizzato nella seconda fase per affinare i dettagli spaziali. Upscaler
- LTX-2 Audio VAE. Decodificatore-encoder audio specializzato che mantiene il suono generato allineato con i frame. Incluso con i checkpoint LTX-2. Checkpoints
- IC LoRA control family for LTX-2. Aggiunge condizionamento in stile ControlNet:
- Depth control LoRA: ltx-2-19b-IC-LoRA-Depth-Control
- Canny control LoRA: ltx-2-19b-IC-LoRA-Canny-Control
- Pose control LoRA: ltx-2-19b-IC-LoRA-Pose-Control
- Distilled LoRA per compromessi qualità/efficienza: ltx-2-19b-distilled-lora-384
- Lotus Depth D v1.1. Stimatore di profondità utilizzato nel percorso di controllo della profondità. Model
- SD VAE FT MSE (Stability AI). VAE immagine utilizzato per precomputare la profondità e decodificare a mosaico. VAE
- ComfyUI-LTXVideo extension. Fornisce i campionatori LTX-2, latenti AV, VAE audio e nodi guida utilizzati in tutto il processo. Repository
Come utilizzare il workflow Comfyui LTX-2 ControlNet#
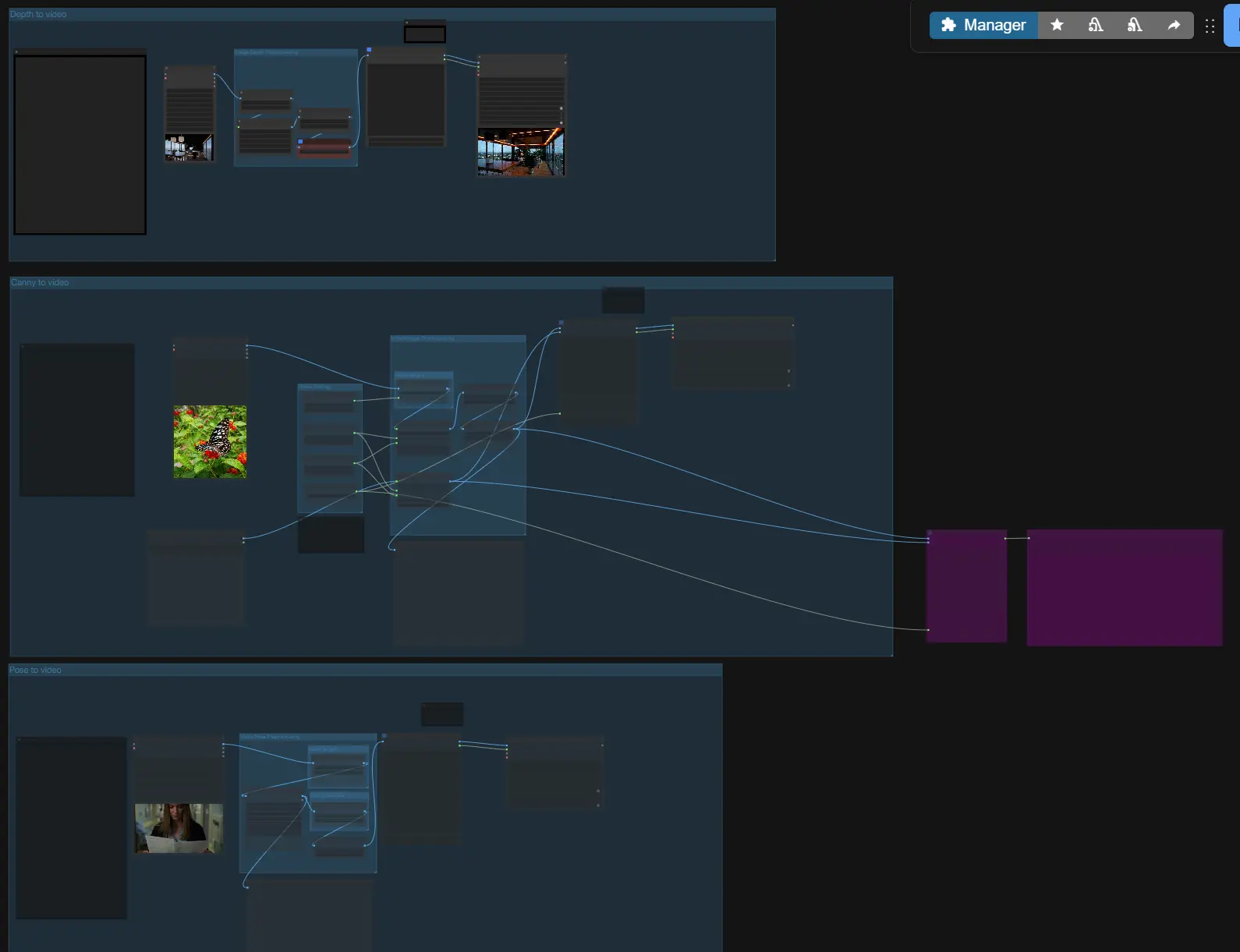
A un livello alto, LTX-2 ControlNet prende il tuo prompt e riferimenti opzionali, costruisce un latente audio-visivo con guida in stile ControlNet, campiona un primo passaggio, quindi ingrandisce il latente per video nitido e audio sincronizzato. Scegli uno dei tre percorsi guidati (Profondità, Canny, Pose) o usali indipendentemente, quindi imposta lunghezza e dimensioni prima di esportare.
- Pre-elaborazione Immagine/Video
- Se stai facendo immagine a video o video a video, usa i loader per portare i tuoi media di riferimento.
VHS_LoadVideo(#196, #197, #198) divide i frame per l'analisi, mentreLoadImage(#189) gestisce le immagini fisse. Il gruppo fornisce un ridimensionamento conveniente in modo che le guide a valle vedano dimensioni dei frame coerenti. - Un'immagine del "primo frame" può essere inoltrata per l'inizializzazione della scena; la abiliterai più tardi nel gruppo di generazione.
- Se stai facendo immagine a video o video a video, usa i loader per portare i tuoi media di riferimento.
- Pre-elaborazione Profondità Immagine
- Per la guida di profondità, il sottografo "Image to Depth Map (Lotus)" converte il tuo input in una mappa di profondità normalizzata utilizzando Lotus Depth. Questo prepara una rappresentazione di profondità a singolo frame o multi-frame che LTX-2 può seguire.
- Il percorso include ridimensionamento opzionale e controlli di intensità in modo che la guida codifichi una struttura ampia senza adattarsi eccessivamente a piccoli artefatti.
- Pre-elaborazione Pose Video
- Per la guida delle pose,
DWPreprocessor(#158) rileva i punti chiave del corpo intero dal video di input e li scala per un condizionamento stabile. Questo produce una sequenza di immagini di pose pulite che enfatizza l'orientamento dello scheletro e degli arti. - I nodi di anteprima ti aiutano a verificare rapidamente che le rilevazioni e i rapporti d'aspetto siano corretti prima della generazione.
- Per la guida delle pose,
- Da Canny a video
- Questo percorso di controllo estrae i bordi con
Canny(#169), quindi costruisce un latente AV con la sequenza di immagini di controllo. Usalo quando vuoi preservare silhouette, contorni principali o bordi di tipografia da un riferimento. - È disponibile un input di immagine del primo frame per un'inizializzazione coerente; abilitalo solo quando vuoi che il frame di apertura corrisponda a un'immagine fissa specifica.
- Questo percorso di controllo estrae i bordi con
- Da Profondità a video
- Questo percorso alimenta le mappe di profondità Lotus come immagini di controllo. Il controllo della profondità è ideale per imporre geometria della telecamera, layout su larga scala e distanza del soggetto lasciando al generatore la scelta di texture e illuminazione.
- Puoi fornire un primo frame per bloccare la composizione iniziale e poi lasciare che il movimento evolva guidato da indizi di profondità.
- Da Pose a video
- Il percorso della pose utilizza il rendering dei punti chiave dal preprocessore, guidando l'orientamento del corpo e la tempistica del movimento. È particolarmente efficace per il blocco dei personaggi, la tempistica del sollevamento delle mani e i cicli di camminata.
- Come con altre modalità, puoi combinare la tempistica del prompt con il condizionamento opzionale del primo frame per la continuità.
- Impostazioni video e lunghezza
- Imposta la larghezza, altezza e il numero di frame nel gruppo "Video Settings" e "video length". Il workflow regola automaticamente i valori non validi alle dimensioni compatibili più vicine per la griglia latente e la cadenza di LTX-2 in modo da poter iterare in sicurezza.
- Mantieni il tuo frame rate di destinazione coerente tra i nodi; i nodi di condizionamento e il mux finale lo rispettano per una sincronizzazione audio-visiva fluida.
- Generazione, ingrandimento ed esportazione
- Durante il campionamento,
LTXVAddGuideintegra il tuo condizionamento positivo/negativo con le immagini di controllo scelte, quindiSamplerCustomAdvancedesegue il programma daLTXVSchedulersia per i latenti video che audio. Il primo frame opzionale è iniettato conLTXVImgToVideoInplacedove abilitato. - La seconda fase esegue
LTXVLatentUpsamplerper affinare i dettagli con l'ingranditore latente x2. La decodifica finale avviene conVAEDecodeTileda mosaico per i frame eLTXVAudioVAEDecodeper l'audio, quindi il video è scritto conVHS_VideoCombineoCreateVideoa seconda del ramo selezionato.
- Durante il campionamento,
Nodi chiave nel workflow Comfyui LTX-2 ControlNet#
LTXVAddGuide(#132)- Unisce il condizionamento del testo e i controlli IC LoRA nel latente AV, agendo come il cuore della guida LTX-2 ControlNet. Regola solo i pochi controlli che contano: scegli il controllo LoRA che corrisponde al tuo percorso (profondità, canny o pose) e, quando disponibile, la
image_strengthche regola quanto strettamente il modello segue le guide. Implementazione di riferimento e comportamento del nodo sono forniti dall'estensione LTXVideo. Docs/Code
- Unisce il condizionamento del testo e i controlli IC LoRA nel latente AV, agendo come il cuore della guida LTX-2 ControlNet. Regola solo i pochi controlli che contano: scegli il controllo LoRA che corrisponde al tuo percorso (profondità, canny o pose) e, quando disponibile, la
LTXVImgToVideoInplace(#149, #155)- Inietta un'immagine del primo frame nel latente AV per un'inizializzazione coerente della scena. Usa
strengthper bilanciare la fedeltà al primo frame rispetto alla libertà di evolversi; mantienilo più basso per più movimento e più alto per ancore più strette. Bypassalo quando vuoi aperture guidate solo da testo o controllo. Docs/Code
- Inietta un'immagine del primo frame nel latente AV per un'inizializzazione coerente della scena. Usa
LTXVScheduler(#95)- Guida la traiettoria di denoising per il latente unificato in modo che sia audio che video convergano insieme. Aumenta i passaggi per scene complesse e dettagli fini; accorciali per bozze e iterazioni rapide. Le impostazioni del programma interagiscono con la forza della guida, quindi evita valori estremi quando la guida è forte. Docs/Code
LTXVLatentUpsampler(#112)- Esegue l'ingrandimento latente di seconda fase con l'ingranditore spaziale x2 di LTX-2, migliorando la nitidezza con una crescita minima del VRAM. Usalo dopo il primo passaggio anziché aumentare la risoluzione di base per mantenere le iterazioni reattive. Upscaler model
DWPreprocessor(#158)- Genera punti chiave di pose umane pulite per il percorso di controllo delle pose. Verifica le rilevazioni con l'anteprima; se mani o arti piccoli sono rumorosi, scala gli input a una dimensione massima moderata prima della pre-elaborazione. Fornito dalla suite ausiliaria ControlNet. Repo
VHS_VideoCombine/CreateVideo(#195, #106)- Muxa frame decodificati e audio in un MP4 con il frame rate e il formato pixel selezionati. Usali solo dopo aver confermato che la decodifica audio appare allineata nell'anteprima. Fornito da Video Helper Suite. Repo
Extra opzionali#
- Prompting per LTX-2 ControlNet
- Descrivi le azioni nel tempo, non solo attributi statici.
- Includi i segnali sonori o i dialoghi necessari affinché l'audio sia generato a tempo.
- Usa un prompt negativo conciso per sopprimere gli artefatti che vedi ripetutamente.
- Dimensioni e lunghezze
- Usa dimensioni delle immagini della forma 32k + 1 per larghezza/altezza; il grafico corregge automaticamente se sbagli, ma valori esatti velocizzano l'iterazione.
- I conteggi di frame della forma 8k + 1 tendono ad essere i più stabili per la programmazione.
- Coerenza del primo frame
- Abilita il primo frame solo quando hai bisogno di una composizione di apertura bloccata; abbinalo a un
image_strengthmoderato per evitare sovra vincoli.
- Abilita il primo frame solo quando hai bisogno di una composizione di apertura bloccata; abbinalo a un
- VRAM e throughput
- Il workflow include opzioni di sequenza parallela e compilazione torch nel patcher LTXVideo per configurazioni multi-GPU o con memoria limitata. Tienili attivi per clip lunghi, disattivali quando esegui il debug del comportamento del nodo. Extension
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo Lightricks per ComfyUI-LTXVideo per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- ComfyUI-LTXVideo GitHub Repository: https://github.com/Lightricks/ComfyUI-LTXVideo
- GitHub: Lightricks/ComfyUI-LTXVideo
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.