
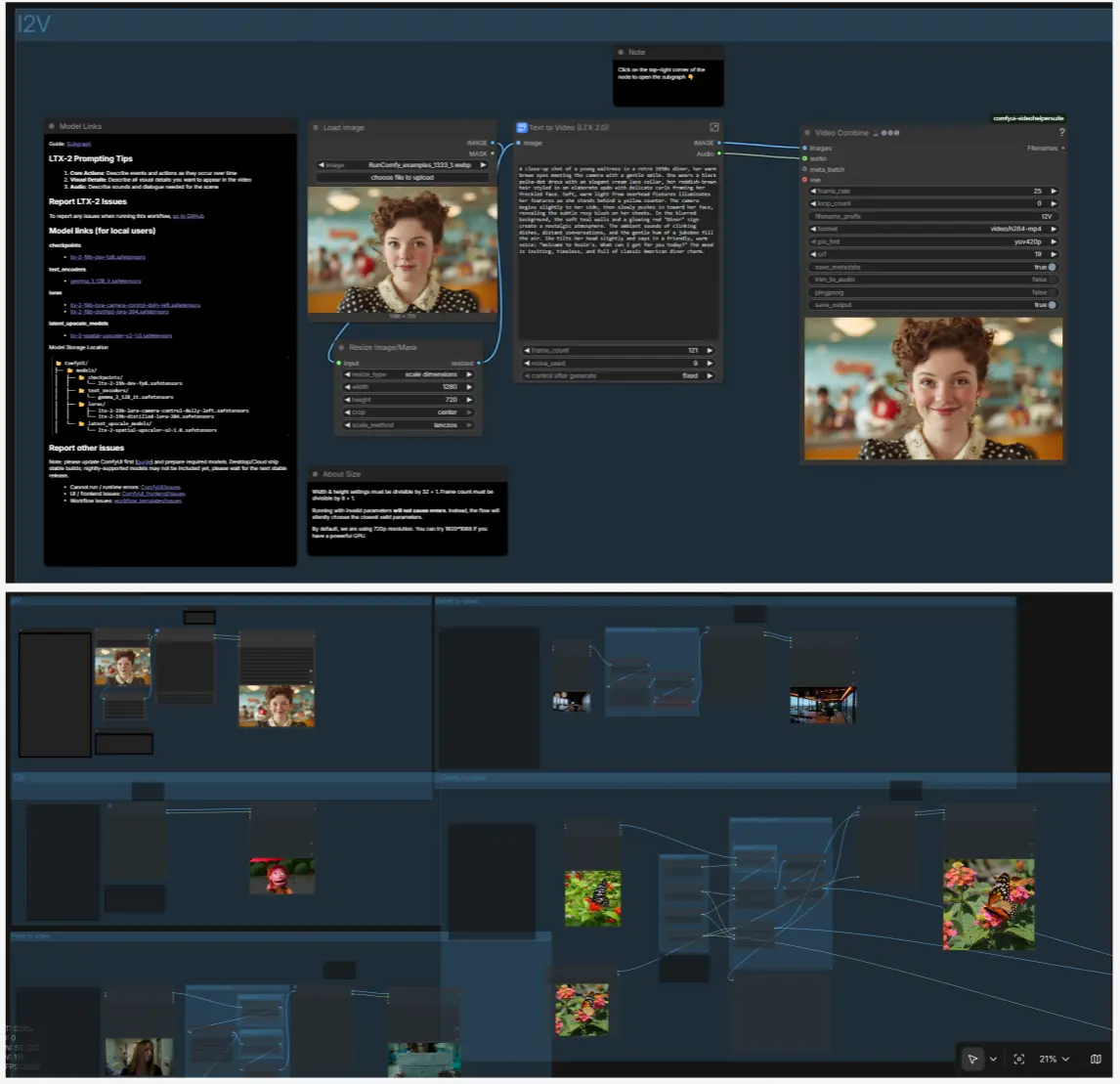
LTX-2 ComfyUI: testo, immagine, profondità e posa in tempo reale con audio sincronizzato#
Questo workflow LTX-2 ComfyUI tutto-in-uno ti consente di generare e iterare brevi video con audio in pochi secondi. Viene fornito con percorsi per testo a video (T2V), immagine a video (I2V), profondità a video, posa a video e canny a video, così puoi iniziare da un prompt, un fermo immagine o una guida strutturata e mantenere lo stesso ciclo creativo.
Costruito attorno al pipeline AV a bassa latenza di LTX-2 e al parallelismo di sequenza multi-GPU, il grafo enfatizza il feedback rapido. Descrivi movimento, camera, aspetto e suono una volta, quindi regola larghezza, altezza, conteggio dei fotogrammi o controlla i LoRAs per perfezionare il risultato senza dover ricollegare nulla.
Nota: Nota sulla Compatibilità del Workflow LTX-2 — LTX-2 include 5 workflow: Text-to-Video e Image-to-Video funzionano su tutti i tipi di macchine, mentre Depth to Video, Canny to Video e Pose to Video richiedono una macchina 2X-Large o superiore; eseguire questi workflow ControlNet su macchine più piccole potrebbe causare errori.
Modelli chiave nel workflow LTX-2 ComfyUI#
- LTX-2 19B (dev FP8) checkpoint. Modello generativo audio-visivo principale che produce fotogrammi video e audio sincronizzato da condizionamento multimodale. Lightricks/LTX-2
- LTX-2 19B Distilled checkpoint. Variante più leggera e veloce utile per bozze rapide o esecuzioni controllate da canny. Lightricks/LTX-2
- Gemma 3 12B IT text encoder. Backbone principale per la comprensione del testo utilizzato dagli encoder di prompt del workflow. Comfy-Org/ltx-2 split files
- LTX-2 Spatial Upscaler x2. Upsampler latente che raddoppia il dettaglio spaziale a metà grafo per output più puliti. Lightricks/LTX-2
- LTX-2 Audio VAE. Codifica e decodifica latenti audio in modo che il suono possa essere generato e muxato insieme al video. Incluso con il rilascio LTX-2 sopra.
- Lotus Depth D v1‑1. Depth UNet utilizzato per derivare mappe di profondità robuste dalle immagini prima della generazione video guidata dalla profondità. Comfy‑Org/lotus
- SD VAE (MSE, EMA pruned). VAE utilizzato nel ramo pre-processore di profondità. stabilityai/sd-vae-ft-mse-original
- Control LoRAs per LTX‑2. LoRAs opzionali, plug‑and‑play per guidare movimento e struttura:
Come usare il workflow LTX-2 ComfyUI#
Il grafo contiene cinque percorsi che puoi eseguire in modo indipendente. Tutti i percorsi condividono lo stesso percorso di esportazione e utilizzano la stessa logica di prompt-to-conditioning, quindi una volta imparato uno, gli altri sembrano familiari.
T2V: genera video e audio da un prompt#
Il percorso T2V inizia con CLIP Text Encode (Prompt) (#3) e un negativo opzionale in CLIP Text Encode (Prompt) (#4). LTXVConditioning (#22) lega il tuo testo e il frame rate scelto al modello. EmptyLTXVLatentVideo (#43) e LTX LTXV Empty Latent Audio (#26) creano latenti video e audio che vengono fusi da LTX LTXV Concat AV Latent (#28). Il ciclo di denoising attraversa LTXVScheduler (#9) e SamplerCustomAdvanced (#41), dopo di che VAE Decode (#12) e LTX LTXV Audio VAE Decode (#14) producono fotogrammi e audio. Video Combine 🎥🅥🅗🅢 (#15) salva un H.264 MP4 con suono sincronizzato.
I2V: anima un fermo immagine#
Carica un fermo immagine con LoadImage (#98) e ridimensiona con ResizeImageMaskNode (#99). All'interno del sottografo T2V, LTX LTXV Img To Video Inplace inietta il primo fotogramma nella sequenza latente in modo che il movimento si sviluppi dal tuo fermo immagine piuttosto che dal rumore puro. Mantieni il tuo prompt testuale focalizzato su movimento, camera e atmosfera; il contenuto proviene dall'immagine.
Profondità a video: movimento consapevole della struttura da mappe di profondità#
Usa il preprocessore “Image to Depth Map (Lotus)” per trasformare un input in un'immagine di profondità, decodificata da VAEDecode e opzionalmente invertita per la polarità corretta. Il percorso “Depth to Video (LTX 2.0)” quindi alimenta la guida di profondità tramite LTX LTXV Add Guide in modo che il modello rispetti la struttura globale della scena mentre anima. Il percorso riutilizza gli stessi stadi di scheduler, sampler e upscaler e termina con la decodifica in piastrelle in immagini e audio muxato per l'esportazione.
Posa a video: guida il movimento dalla posa umana#
Importa una clip con VHS_LoadVideo (#198); DWPreprocessor (#158) stima la posa umana in modo affidabile tra i fotogrammi. Il sottografo “Pose to Video (LTX 2.0)” combina il tuo prompt, il condizionamento della posa e un opzionale Pose Control LoRA per mantenere arti, orientamento e battiti coerenti permettendo allo stile e allo sfondo di fluire dal testo. Usalo per danza, acrobazie semplici o riprese parlate dove il tempismo del corpo è importante.
Canny a video: animazione fedele ai bordi e modalità di velocità distillata#
Fornisci fotogrammi a Canny (#169) per ottenere una mappa dei bordi stabile. Il ramo “Canny to Video (LTX 2.0)” accetta i bordi più un opzionale Canny Control LoRA per alta fedeltà alle silhouette, mentre “Canny to Video (LTX 2.0 Distilled)” offre un checkpoint distillato più veloce per iterazioni rapide. Entrambe le varianti ti permettono di iniettare opzionalmente il primo fotogramma e scegliere la forza dell'immagine, quindi esportare tramite CreateVideo o VHS_VideoCombine.
Impostazioni video ed esportazione#
Imposta larghezza e altezza tramite Width (#175) e height (#173), i fotogrammi totali con Frame Count (#176), e attiva Enable First Frame (#177) se vuoi bloccare un riferimento iniziale. Usa i nodi VHS_VideoCombine alla fine di ciascun percorso per controllare crf, frame_rate, pix_fmt e il salvataggio dei metadati. È previsto un SaveVideo (#180) dedicato per il percorso canny distillato quando preferisci l'output VIDEO diretto.
Prestazioni e multi-GPU#
Il grafo applica LTXVSequenceParallelMultiGPUPatcher (#44) con torch_compile abilitato per dividere le sequenze tra GPU per una latenza inferiore. KSamplerSelect (#8) ti permette di scegliere tra sampler inclusi Euler e stili di stima del gradiente; conteggi di fotogrammi più piccoli e passi inferiori riducono i tempi di risposta, così puoi iterare rapidamente e scalare quando sei soddisfatto.
Nodi chiave nel workflow LTX-2 ComfyUI#
LTX Multimodal Guider(#17). Coordina come il condizionamento del testo guida entrambi i rami video e audio. RegolacfgemodalityneiLTX Guider Parameterscollegati (#18 per VIDEO, #19 per AUDIO) per bilanciare fedeltà contro creatività; aumentacfgper un'aderenza più stretta al prompt e aumentamodality_scaleper enfatizzare un ramo specifico.LTXVScheduler(#9). Costruisce un programma sigma su misura per lo spazio latente di LTX‑2. Usastepsper scambiare velocità per qualità; quando si prototipa, meno passi riducono la latenza, poi aumenta i passi per i rendering finali.SamplerCustomAdvanced(#41). Il denoiser che lega insiemeRandomNoise, il sampler scelto daKSamplerSelect(#8), i sigma dello scheduler e il latente AV. Cambia sampler per diverse texture di movimento e comportamento di convergenza.LTX LTXV Img To Video Inplace(vedi rami I2V, ad es., #107). Inietta un'immagine in un latente video in modo che il primo fotogramma ancoraggio il contenuto mentre il modello sintetizza il movimento. Regolastrengthper quanto rigorosamente viene preservato il primo fotogramma.LTX LTXV Add Guide(in percorsi guidati, ad es., profondità/posa/canny). Aggiunge una guida strutturale (immagine, posa o bordi) direttamente nello spazio latente. Usastrengthper bilanciare la fedeltà della guida con la libertà generativa e abilita il primo fotogramma solo quando vuoi un ancoraggio temporale.Video Combine 🎥🅥🅗🅢(#15 e fratelli). Confeziona fotogrammi decodificati e l'audio generato in MP4. Per le anteprime, aumentacrf(più compressione); per i finali, abbassacrfe conferma cheframe_ratecorrisponde a ciò che hai impostato nel condizionamento.LTXVSequenceParallelMultiGPUPatcher(#44). Abilita l'inferenza sequenziale-parallela con ottimizzazioni di compilazione. Lascialo attivo per la massima produttività; disabilitalo solo quando esegui il debug del posizionamento del dispositivo.
Extra opzionali#
- Suggerimenti per il prompting per LTX-2 ComfyUI
- Descrivi le azioni principali nel tempo, non solo l'aspetto statico.
- Specifica i dettagli visivi importanti che devi vedere nel video.
- Scrivi la colonna sonora: ambiente, foley, musica e qualsiasi dialogo.
- Regole di dimensionamento e frame rate
- Usa larghezza e altezza che sono multipli di 32 (ad esempio 1280×720).
- Usa conteggi di fotogrammi che sono multipli di 8 (121 in questo modello è una buona lunghezza).
- Mantieni il frame rate coerente dove appare; il grafo include caselle float e int e devono corrispondere.
- Guida LoRA
- Le LoRAs per camera, profondità, posa e canny sono integrate; inizia con forza 1 per i movimenti della camera, poi aggiungi un secondo LoRA solo quando necessario. Sfoglia la collezione ufficiale su Lightricks/LTX‑2.
- Iterazioni più veloci
- Riduci il conteggio dei fotogrammi, riduci i passi in
LTXVScheduler, e prova il checkpoint distillato per il percorso canny. Quando il movimento funziona, scala risoluzione e passi per i finali.
- Riduci il conteggio dei fotogrammi, riduci i passi in
- Riproducibilità
- Blocca
noise_seednei nodi Random Noise per ottenere risultati ripetibili mentre perfezioni prompt, dimensioni e LoRAs.
- Blocca
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo Lightricks per il modello di generazione video multimodale LTX-2 e il codice di ricerca LTX-Video, e Comfy Org per i nodi partner ComfyUI LTX-2/l'integrazione, per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Comfy Org/LTX-2 Ora Disponibile in ComfyUI!
- GitHub: Lightricks/LTX-Video
- Hugging Face: Lightricks/LTX-Video-ICLoRA-detailer-13b-0.9.8
- arXiv: 2501.00103
- Docs / Release Notes: LTX-2 Ora Disponibile in ComfyUI!
Nota: L'uso dei modelli, dataset e codice menzionati è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.

