
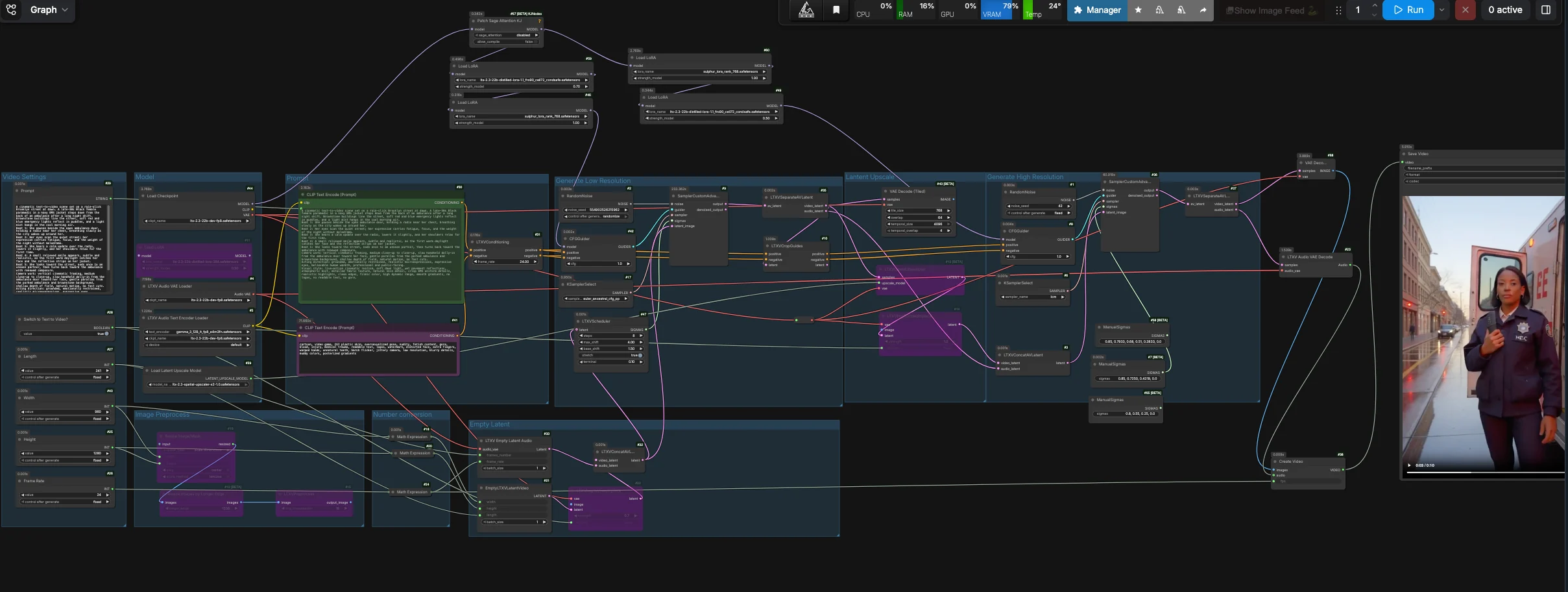
LTX 2.3 Sulphur T2V workflow: prompt‑to‑cinema con microespressioni, atmosfera e telecamera guidata#
Il workflow LTX 2.3 Sulphur T2V trasforma prompt ben scritti in clip cinematografici che enfatizzano microespressioni credibili, dettagli della scena atmosferici e movimento guidato dalla storia. Combina un passaggio di generazione LTX 2.3 distillato con guida in stile Sulphur, guida opzionale al controllo della telecamera e un percorso di decodifica a piastrelle stabile per risultati affidabili da testo a video.
Costruito per i creatori che vogliono ritmi di recitazione fondati e movimento della telecamera controllabile, questo setup ComfyUI bilancia la fedeltà narrativa con la stabilità temporale. Puoi eseguire un puro testo-a-video o partire da un'immagine fissa, quindi decodificare il latente del primo passaggio stabile in una sequenza pulita e amichevole per l'editor con una traccia audio segnaposto per un facile editing.
Modelli chiave nel workflow Comfyui LTX 2.3 Sulphur T2V#
- Lightricks LTX‑2.3 22B FP8 checkpoint. Il modello base da testo a video che alimenta generazione e decodifica. Model repository
- LTX‑2.3 distilled LoRA. Un adattatore distillato che mantiene la qualità consentendo campionamento più veloce, a minor numero di passaggi e movimento stabile. Model family
- LTX‑2.3 spatial upscaler x2. Incluso nel grafico per esperimenti, mentre il percorso di esportazione predefinito utilizza la decodifica stabile del primo passaggio per risultati più puliti su questo setup. Upscaler
- LTX‑2 19B LoRA Camera Control Dolly Left. Guida opzionale per movimento dolly-in stabile e parallax delicato quando la tua scena lo richiede. LoRA
- LTX text encoder (Gemma 3 12B variants). Il tokenizer e il modello di embedding che interpreta il tuo prompt e le note di ritmo. Text encoders
- LTX audio VAE. Imballa un flusso audio silenzioso affinché il video risultante si carichi correttamente nei NLE. Model repository
- Sulphur LoRA (incluso). Un adattatore di stile e ritmo di recitazione curato per microespressioni espressive ma contenute e armonia cromatica cinematografica.
Come utilizzare il workflow Comfyui LTX 2.3 Sulphur T2V#
Questo workflow predefinisce un percorso stabile da testo a video di primo passaggio. Genera un latente video coerente, separa le corsie video e audio, decodifica il latente video di primo passaggio con decodifica VAE a piastrelle, quindi confeziona i fotogrammi e l'audio silenzioso in un file video pronto per l'editing. I nodi di upscale e rifinitura latenti rimangono nel grafico per esperimenti avanzati, ma l'output predefinito bypassa quel ramo per affidabilità.
Modello#
Il gruppo Modello carica il checkpoint LTX‑2.3 FP8, l'encoder di testo LTX, l'audio VAE e gli adattatori usati in tutto. Le LoRA distillate e Sulphur sono applicate al modello base affinché la scena aderisca strettamente ai tuoi ritmi e all'intento facciale. Se desideri il movimento dolly, abilita la LoRA di controllo della telecamera nei nodi LoraLoader forniti. Il percorso predefinito alimenta il campionatore primario attraverso CFGGuider (#42), mentre il ramo di rifinitura è tenuto disponibile per esperimenti manuali.
Prompt#
Scrivi la tua scena nel campo Prompt (#29) come brevi linee di ritmo più brevi note di telecamera. Il testo positivo è codificato da CLIPTextEncode (#30), mentre una lista negativa curata in CLIPTextEncode (#41) sopprime la lucentezza CGI, gli artefatti, il tremolio e lo sfarfallio duro. Mantieni la direzione della recitazione concisa e specifica per occhi, spalle e respiro per sbloccare le microespressioni per cui questo workflow è ottimizzato. Il linguaggio della telecamera come "lento dolly a mano libera" e "parallax delicato" si mappa bene al pianificatore e alla LoRA opzionale della telecamera.
Impostazioni video#
Scegli output Width, Height, Frame Rate e Length nel gruppo Impostazioni video (#40, #25, #26, #27). Internamente, il workflow deriva un latente a mezza risoluzione per il passaggio di generazione per migliorare la coerenza temporale, quindi decodifica direttamente quel latente stabile. Usa Switch to Text to Video? (#28) per eseguire puro T2V, o disattivalo e alimenta un'immagine iniziale attraverso il percorso di preelaborazione delle immagini per I2V controllato. Le dimensioni dovrebbero restare su multipli comuni per una decodifica veloce e compatibile con le piastrelle.
Latente vuoto#
EmptyLTXVLatentVideo (#21) crea un latente video vuoto secondo le tue impostazioni, e LTXVEmptyLatentAudio (#33) crea un latente audio corrispondente affinché il mux del contenitore sia amichevole per l'editor. Se desideri partire da un'immagine, LTXVImgToVideoInplace (#22) può iniettarla nella timeline latente a una strength controllabile. Quando bypass è attivo, il nodo produce un init puro guidato dal testo.
Genera a bassa risoluzione#
I latenti audio e video sono uniti da LTXVConcatAVLatent (#32) e temporizzati da LTXVScheduler (#47), che imposta un programma di sigma consapevole del video per movimento fluido e viaggio della telecamera. CFGGuider (#42) combina il tuo condizionamento positivo e negativo con la pila di modelli, e SamplerCustomAdvanced (#9) esegue il passaggio di generazione principale. LTXVSeparateAVLatent (#35) quindi divide la clip nuovamente in latenti video e audio; l'output predefinito utilizza questo latente video stabile per la decodifica a piastrelle.
Upscale latente opzionale#
LTXVLatentUpsampler (#13) applica l'upscaler spaziale LTX x2 da LatentUpscaleModelLoader (#39) mantenendo intatta la struttura temporale. LTXVImgToVideoInplace (#14) rewrappa il latente video upscalato insieme alla corsia audio esistente. Questo ramo rimane disponibile se desideri sperimentare con rifinitura ad alta risoluzione, ma non è collegato all'output finale predefinito.
Rifinitura opzionale#
Il ramo di rifinitura utilizza CFGGuider (#8) e SamplerCustomAdvanced (#36) con un programma di sigma breve e manuale. È utile per utenti avanzati che vogliono testare il percorso ad alta risoluzione, ma l'output del workflow predefinito bypassa questo ramo perché la decodifica a piastrelle del primo passaggio stabile offre risultati più puliti sul setup RunComfy fornito.
Output#
VAEDecodeTiled (#43) decodifica il latente video stabile da LTXVSeparateAVLatent (#35), e LTXVAudioVAEDecode (#23) produce una traccia silenziosa che rende felici gli editor. CreateVideo (#38) assembla la sequenza al tuo fps scelto, e SaveVideo (#45) lo scrive su disco. Ottieni un video pronto da condividere con movimento stabile, gradienti puliti e flusso di telecamera controllato.
Nodi chiave nel workflow Comfyui LTX 2.3 Sulphur T2V#
LTXVScheduler (#47)#
Orchestra la sequenza di sigma consapevole del video per il primo passaggio. I suoi controlli di shift influenzano quanto fortemente il movimento si accumula tra i fotogrammi; shift più alti enfatizzano il viaggio della telecamera e il movimento del soggetto più veloce, mentre valori più bassi favoriscono un inquadramento più stabile. Se abiliti una LoRA di controllo della telecamera, shift modesti si abbinano meglio per evitare derive esagerate.
LTXVCropGuides (#10)#
Genera canali di condizionamento consapevoli del ritaglio dal tuo testo affinché le regioni importanti, specialmente i volti, si risolvano con maggiore fedeltà. Usalo per guidare microespressioni e dettagli degli occhi senza sovraccaricare il campionatore globale. Se i primi piani sembrano morbidi, stringi i tuoi ritmi di recitazione e lascia che Crop Guides faccia la guida fine.
LTXVImgToVideoInplace (#22, #14)#
Trasforma un'immagine fissa in un latente temporaneamente coerente o rewrappa un latente upscalato per rifinitura opzionale. Il controllo strength imposta quanto dell'immagine sorgente è preservato attraverso la timeline; valori più bassi consentono più adattamento generativo, valori più alti mantengono inquadratura e identità bloccate. Attiva bypass per passare pulitamente tra I2V e puro T2V.
LTXVLatentUpsampler (#13)#
Applica l'upscaler spaziale LTX x2 in-latente per sollevare texture e bordi per esperimenti di rifinitura opzionale. Il percorso di esportazione predefinito non dipende da questo nodo, quindi puoi confrontare l'output stabile di primo passaggio con il ramo di rifinitura senza cambiare la catena di output principale.
CFGGuider (#42, #8) e KSamplerSelect (#17, #6)#
Queste coppie definiscono quanto strettamente il modello segue il tuo testo e quanto aggressivamente campiona. Mantieni la guida conservativa per il realismo del video; aumentarla può aumentare l'aderenza al prompt ma può irrigidire il movimento o aggiungere sfarfallio. L'esportazione predefinita si affida al campionatore primario per movimento stabile, mentre il campionatore secondario è riservato per test di rifinitura opzionale.
Extra opzionali#
- Scrivi da 3 a 6 ritmi che descrivano intenzione e linguaggio del corpo piuttosto che trama; le microespressioni emergono da segnali specifici come "gli occhi si ammorbidiscono" o "le spalle si rilassano."
- Mantieni il linguaggio della telecamera compatto: un verbo di movimento più un soggetto, ad esempio "lento dolly-in sul suo viso" o "parallax delicato dalle auto parcheggiate."
- Se desideri un'inquadratura statica, disabilita la LoRA di controllo della telecamera e riduci leggermente gli shift del pianificatore; per più viaggio, abilita la LoRA e aumenta modestamente lo shift.
- Usa larghezza e altezza che siano multipli puliti di 32 per una decodifica prevedibile e compatibile con le piastrelle.
- Per la riproducibilità, blocca i semi in
RandomNoise(#2, #1); cambia solo un seme quando esplori variazioni. - Il prompt negativo sopprime già artefatti CGI e sfarfallio; mantienilo concentrato e lascia che il tuo testo positivo trasmetta stile e intento.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine RunningHub per il riferimento al workflow, Lightricks per il modello LTX 2.3, LoRA distillato e upscaler spaziale, e LoRA di controllo della telecamera, e Comfy-Org per l'encoder di testo LTX per i loro contributi e manutenzione. Per dettagli autorevoli, fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- RunningHub/Workflow Reference
- Docs / Note di rilascio: Post
- Lightricks/LTX-2.3-fp8
- Hugging Face: Lightricks/LTX-2.3-fp8
- Lightricks/LTX-2.3
- Hugging Face: Lightricks/LTX-2.3
- Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Hugging Face: Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Comfy-Org/ltx-2
- Hugging Face: Comfy-Org/ltx-2
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.