
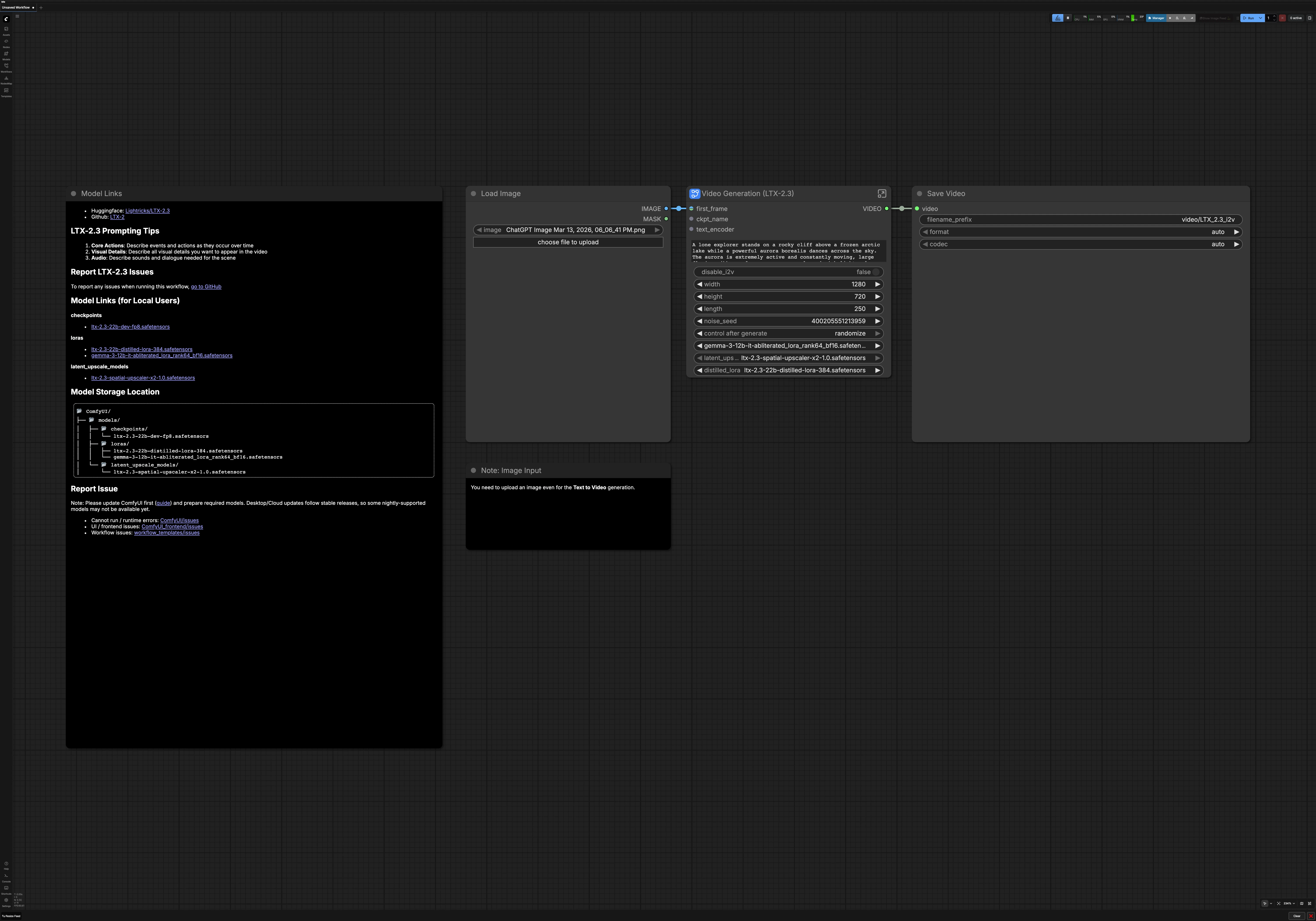
LTX 2.3 Da Immagine a Video per ComfyUI#
Questo workflow trasforma una singola immagine o un semplice prompt testuale in un video AI cinematografico e fluido con LTX 2.3 Da Immagine a Video. È realizzato per i creatori che desiderano alta coerenza visiva, forte consistenza della scena e movimento raffinato senza cablaggio manuale. Usalo su RunComfy o in qualsiasi ambiente ComfyUI per generare risultati dinamici e stilizzati che restano fedeli al tuo prompt.
Il grafico supporta due modalità creative: da immagine a video con il tuo primo fotogramma come ancoraggio visivo, o da testo a video guidato interamente dal linguaggio. Include anche il miglioramento automatico del prompt, l'aumento latente per dettagli più nitidi e la decodifica audio opzionale affinché il tuo rendering finale LTX 2.3 Da Immagine a Video sia pronto per la pubblicazione.
Modelli chiave nel workflow ComfyUI LTX 2.3 Da Immagine a Video#
- Modello video Lightricks LTX 2.3 22B. Il core del video diffusion transformer che sintetizza movimento e visuali temporalmente coerenti da testo e guida d'immagine opzionale. I file del modello e la documentazione sono disponibili su Hugging Face e riferimenti a livello di codice su GitHub.
- LTX Audio VAE. Il codificatore variazionale audio utilizzato per decodificare il latente audio del modello in una traccia audio da combinare con i fotogrammi. Distribuito con il rilascio LTX 2.3 su Hugging Face.
- LTX 2.3 Spatial Upscaler x2. Un modello di super-risoluzione nello spazio latente che migliora la nitidezza e la fedeltà spaziale prima del passaggio finale di campionamento ad alta risoluzione. Disponibile nel repository LTX 2.3 su Hugging Face.
- Gemma 3 12B Instruct text encoder più LoRA. Un encoder di testo compatto sintonizzato per istruzioni e LoRA usato qui per migliorare la comprensione del prompt e la formulazione per il video. L'encoder confezionato e i pesi LoRA utilizzati da questo template sono forniti negli asset Comfy-Org LTX-2 su Hugging Face.
Come usare il workflow ComfyUI LTX 2.3 Da Immagine a Video#
A livello generale, il tuo prompt e il primo fotogramma opzionale vengono codificati, un video latente a bassa risoluzione viene campionato, quindi aumentato nello spazio latente e raffinato ad alta risoluzione. Il risultato viene decodificato in fotogrammi e audio, quindi composto in un MP4 finale. Puoi passare da immagine a video a testo a video in qualsiasi momento prima dell'esecuzione.
- Modello
- Questo gruppo carica il checkpoint LTX 2.3, l'audio VAE e l'encoder di testo. Applica anche la LTX 2.3 LoRA al modello base per migliorare il seguito delle istruzioni. Insieme definiscono la base su cui il resto della pipeline LTX 2.3 Da Immagine a Video si costruisce. Solitamente non modifichi nulla qui a meno che non sostituisci varianti di modello o stili LoRA.
- Prompt
- Inserisci la descrizione della tua scena e i negativi opzionali. Il testo è codificato per entrambi i condizionamenti positivi e negativi e abbinato alla velocità dei fotogrammi selezionata affinché la pianificazione del movimento si allinei con il tempismo. Mantieni il linguaggio consapevole del tempo con verbi che descrivono il cambiamento, ad esempio "la telecamera avanza" o "le foglie vorticano nel vento". I prompt negativi aiutano a evitare artefatti indesiderati come watermark o semplificazioni cartoonesche.
- Miglioramento del Prompt
- Il grafico include un aiutante che analizza la tua immagine e testo, quindi genera una bozza di prompt più forte e consapevole del tempo che puoi adottare o modificare. Ciò facilita la guida di LTX 2.3 Da Immagine a Video verso descrizioni cinematografiche e orientate all'azione. È particolarmente utile quando inizi da un singolo fermo immagine e desideri un movimento che sembri intenzionale. Il nodo di anteprima ti consente di ispezionare il testo migliorato prima della generazione.
- Impostazioni Video
- Scegli se eseguire da immagine a video o passare a testo a video con un semplice interruttore. Imposta larghezza, altezza, durata e velocità dei fotogrammi per adattarti alla tua piattaforma di destinazione. Queste impostazioni guidano l'allocazione latente e la decodifica a valle, quindi mantienile in sintonia con il tuo intento creativo. Se prevedi di pubblicare ampiamente, prediligi dimensioni e tempistiche compatibili con i codec.
- Preprocessamento Immagine
- Il tuo primo fotogramma viene ridimensionato e normalizzato a un aspetto amichevole per il modello mantenendo la composizione. Un leggero prefiltro aiuta a stabilizzare i bordi e ridurre il rumore di compressione che può causare sfarfallio durante il movimento. Questo passaggio è importante anche quando usi solo l'immagine per suggerire layout e colore.
- Latente Vuoto
- Il workflow alloca latenti video e audio vuoti basati sulle tue dimensioni, durata e velocità dei fotogrammi. Questo fornisce una tela pulita per il campionatore e garantisce che audio e video rimangano allineati in lunghezza. Il rumore è generato deterministicamente quando desideri riproducibilità o randomizzato per variazione tra le esecuzioni.
- Genera Bassa Risoluzione
- Un primo passaggio di campionamento incide movimento e struttura in un video latente compatto. Se stai usando da immagine a video,
LTXVImgToVideoInplace(#249) inietta il tuo primo fotogramma come ancoraggio visivo affinché il movimento si evolva da un punto di partenza coerente. Il condizionamento del tuo testo positivo e negativo guida contenuto e stile, mentreManualSigmas(#252) eKSamplerSelectdefiniscono quanto aggressivamente il rumore viene rimosso nel tempo.LTXVCropGuides(#212) aiuta a mantenere un'inquadratura che corrisponde al tuo prompt. L'audio-video latente risultante viene quindi suddiviso per un'elaborazione separata.
- Un primo passaggio di campionamento incide movimento e struttura in un video latente compatto. Se stai usando da immagine a video,
- Aumento Latente
- Prima di impegnarsi nel raffinamento ad alta risoluzione,
LTXVLatentUpsampler(#253) applica l'ingranditore spaziale x2 al latente a bassa risoluzione. Farlo nello spazio latente è veloce e preserva il movimento appreso mentre aumenta la capacità di dettaglio. È un modo sicuro per aggiungere nitidezza senza introdurre artefatti.
- Prima di impegnarsi nel raffinamento ad alta risoluzione,
- Genera Alta Risoluzione
- Un secondo campionatore affina il latente aumentato a dimensioni spaziali maggiori per bloccare texture, illuminazione e piccoli movimenti. Quando si esegue da testo a video, il passaggio da immagine a video precedente può essere bypassato e
LTXVImgToVideoInplace(#230) semplicemente passa il latente.VAEDecodeTiled(#251) quindi decodifica il video latente in fotogrammi in modo efficiente. In parallelo, il latente audio viene decodificato con il LTX Audio VAE affinché entrambi i flussi finiscano accurati per fotogramma.
- Un secondo campionatore affina il latente aumentato a dimensioni spaziali maggiori per bloccare texture, illuminazione e piccoli movimenti. Quando si esegue da testo a video, il passaggio da immagine a video precedente può essere bypassato e
- Esporta
CreateVideo(#242) combina fotogrammi e traccia audio decodificata in un singolo video alla velocità dei fotogrammi scelta. Il nodoSaveVideodi alto livello scrive il file finale nella tua uscita ComfyUI affinché tu possa scaricarlo immediatamente. Il tuo rendering LTX 2.3 Da Immagine a Video è ora pronto per l'anteprima o la pubblicazione.
Nodi chiave nel workflow ComfyUI LTX 2.3 Da Immagine a Video#
LTXVImgToVideoInplace(#249 e #230)- Converte un fermo immagine in un video latente o passa il latente quando disabilitato. Usalo quando desideri che il primo fotogramma definisca layout, palette e posizionamento dei personaggi. Attiva l'interruttore da testo a video se preferisci che il movimento emerga solo dal prompt. La documentazione per la famiglia di operatori è mantenuta nell'integrazione ComfyUI su GitHub.
LTXVConditioning(#239)- Combina il testo codificato positivo e negativo con la tua velocità dei fotogrammi per produrre un condizionamento che guida sia il contenuto che il ritmo del movimento. Preferisci frasi brevi e chiare che descrivono il cambiamento nel tempo e riserva i negativi per artefatti che vedi costantemente e vuoi sopprimere. Questo nodo è il posto più efficace per regolare stile e comportamento della scena senza toccare i campionatori.
ManualSigmas(#252) conKSamplerSelect- Il programma del rumore e il campionatore lavorano insieme per bilanciare il grande movimento rispetto al dettaglio fine. Un rumore iniziale più alto incoraggia un movimento più ampio mentre i passaggi successivi consolidano la texture. Regola questi solo dopo aver buoni prompt e guida d'immagine in atto. I controlli di campionamento sottostanti seguono la semantica standard di ComfyUI, vedi implementazioni di riferimento nel repository LTX su GitHub.
LTXVLatentUpsampler(#253)- Applica lo scaler spaziale LTX 2.3 nello spazio latente affinché tu possa affinare ad alta risoluzione nella fase successiva. Usalo quando hai bisogno di maggiore nitidezza o pianifichi di consegnare formati più grandi. Il modello x2 è distribuito con LTX 2.3 su Hugging Face.
VAEDecodeTiled(#251) eCreateVideo(#242)- La decodifica a piastrelle previene picchi di memoria ad alta risoluzione e garantisce qualità del fotogramma coerente.
CreateVideopoi assembla fotogrammi e traccia audio decodificata in un MP4 finale alla tua fps selezionata. Mantieni il tuo fps coerente con il valore usato durante il condizionamento per evitare derapamenti di riproduzione.
- La decodifica a piastrelle previene picchi di memoria ad alta risoluzione e garantisce qualità del fotogramma coerente.
Extra opzionali#
- Devi ancora caricare un'immagine del primo fotogramma anche quando usi da testo a video. L'interruttore lo ignorerà durante la generazione ma l'UI richiede un'immagine segnaposto.
- Per il prompting LTX 2.3 Da Immagine a Video, inizia con l'azione principale, poi specifiche visive, poi atmosfera. Parole di tempo come "lentamente", "improvvisamente" e "continua" aiutano il modello a pianificare il movimento.
- Usa prompt negativi per evitare sovrapposizioni e artefatti UI come "watermark", "sottotitoli" o "fermo immagine".
- Se lo stile appare troppo forte o troppo debole, prova un diverso LoRA o regola il suo peso nel caricatore LoRA. Puoi anche rimuovere il LoRA per appoggiarti all'aspetto del modello base.
- Riutilizza un seme di rumore fisso per riproducibilità quando iteri sul testo, quindi randomizza per variazione una volta bloccato lo scatto.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo Lightricks per LTX-2.3 e EyeForAILabs per il Tutorial EyeForAILabs su YouTube per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model
- EyeForAILabs/Tutorial su YouTube
- Documenti / Note di Rilascio: EyeForAILabs YouTube Tutorial
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.