
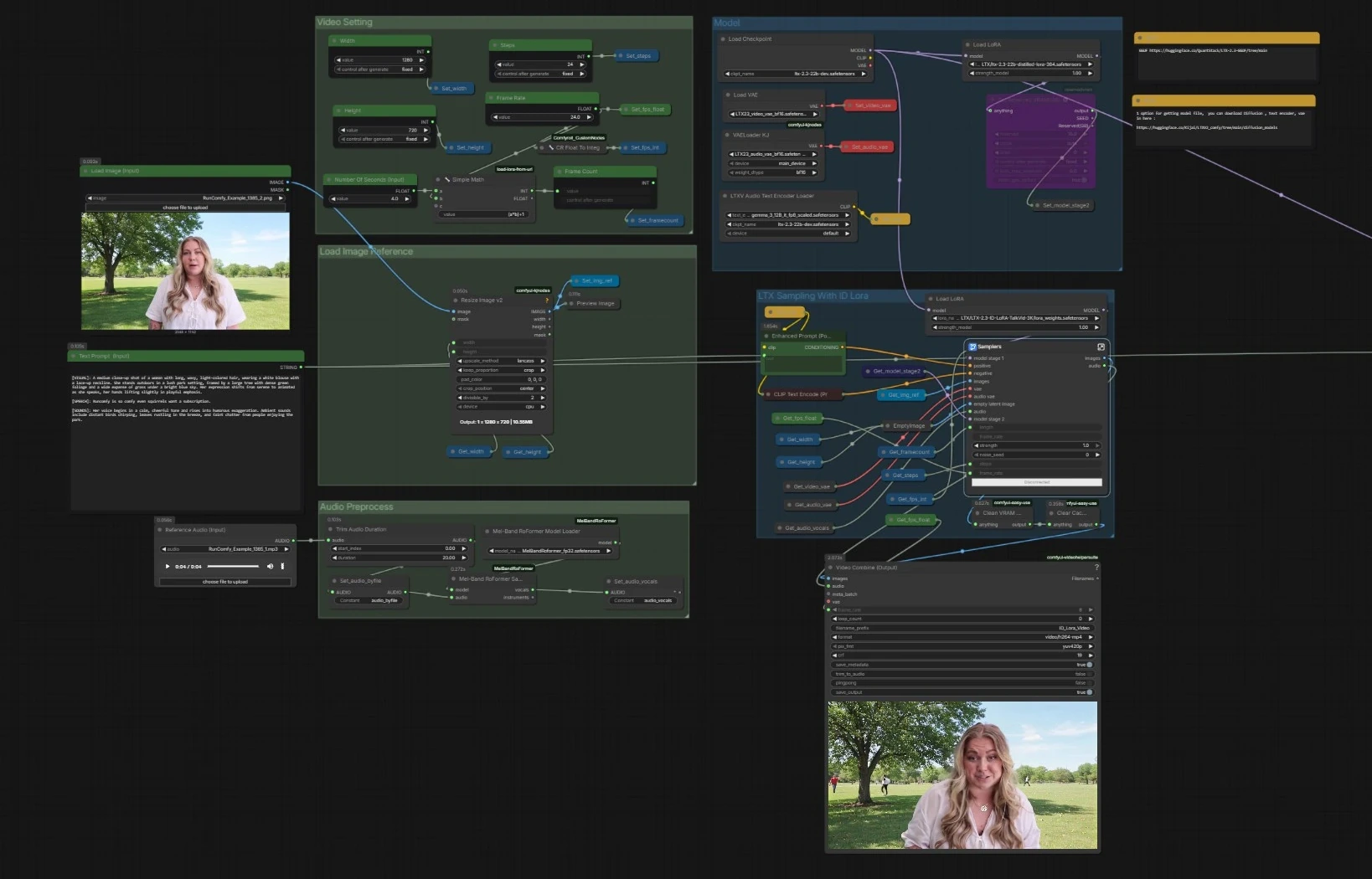
Flusso di lavoro video parlante LTX 2.3 ID-LoRA per ComfyUI#
Questo flusso di lavoro trasforma una singola immagine del viso, un breve clip vocale e un prompt in un video parlante completamente sincronizzato. Basato su LTX-2.3, fonde audio e immagini in un unico processo di diffusione e aggiunge un adattatore di identità In-Context LoRA in modo che la persona nella tua immagine di riferimento rimanga coerente in tutti i fotogrammi. LTX 2.3 ID-LoRA è ideale per avatar, host virtuali e qualsiasi scenario in cui sincronizzazione labiale, somiglianza e controllo del prompt devono allinearsi in un unico passaggio.
Fornisci tre elementi: un'immagine di riferimento, una o due frasi di audio e un prompt di testo che descrive aspetto e performance. Il percorso LTX 2.3 ID-LoRA gestisce l'identità mentre un preprocessore audio leggero migliora la chiarezza della voce per segnali labiali più forti. Il risultato è un video coerente, che preserva l'identità con discorso sincronizzato che non richiede addestramento specifico per soggetto.
Modelli chiave nel flusso di lavoro Comfyui LTX 2.3 ID-LoRA#
- Lightricks LTX-2.3 22B checkpoint di base. Il modello di base audio-video congiunto che genera fotogrammi e suoni sincronizzati da testo, immagine e condizionamento audio. È il generatore principale utilizzato da questa pipeline ComfyUI. Model card
- LTX-2.3 LoRA distillato 384. Adattatore LoRA ufficiale che applica la guida distillata al modello di base per stabilizzare e velocizzare il campionamento senza sacrificare la qualità. È collegato come modello di secondo stadio in questo flusso di lavoro. Vedi la tabella dei checkpoint nella pagina LTX-2.3. Model card
- LTX-2.3 upscaler spaziale x2. Upscaler dello spazio latente utilizzato all'interno del sottografo del campionatore per migliorare il dettaglio spaziale prima della decodifica, migliorando la fedeltà del viso e dei bordi nel video finale. Model card
- Gemma 3 12B Instruct text encoder per LTX-2.3. Fornisce il condizionamento del testo che guida stile, scena e performance. Questo flusso di lavoro utilizza il codificatore Gemma 3 confezionato per LTX-2 in ComfyUI. Comfy-Org text encoders
- LTX-2.3 VAEs per video e audio. VAEs costruiti appositamente decodificano latenti visivi e acustici prodotti dal modello in immagini e una forma d'onda. Build compatibili bf16 sono referenziate nel grafo. Fonti di esempio: Video VAE · Audio VAE
- Mel-Band RoFormer per separazione vocale. Preprocessore opzionale che estrae voci pulite dall'audio di riferimento in modo che il modello possa tracciare sillabe e forme della bocca più affidabilmente. Paper · ComfyUI node
- LTX 2.3 ID-LoRA (IC-LoRA). Un LoRA di identità in contesto addestrato per l'uso in video parlanti che orienta il generatore verso il volto nella tua immagine di riferimento rispettando i suggerimenti e i segnali vocali. Lightricks documenta l'uso di LoRA e IC-LoRA con LTX-2.3 sulla pagina del modello. Model card
Come usare il flusso di lavoro Comfyui LTX 2.3 ID-LoRA#
Flusso generale. La pipeline carica il LTX-2.3 di base con codificatori di testo e VAEs, prepara la tua immagine e audio, quindi esegue un campionatore LTX a due stadi che combina testo, il riferimento del viso e una traccia vocale per generare fotogrammi e discorsi sincronizzati. È incluso un campionatore parallelo senza ID-LoRA per confronti rapidi. I fotogrammi finali e l'audio sono muxed in un MP4.
- Modello
- Il grafo carica il checkpoint di base con
CheckpointLoaderSimple(#5493), i codificatori di testo basati su Gemma tramiteLTXAVTextEncoderLoader(#5494), e i VAEs dedicati per videoVAELoader(#5651) e audioVAELoaderKJ(#5649). Applica quindi due adattatori: il LoRA distillato ufficiale per formare un modello di stadio-2 e il LTX 2.3 ID-LoRA per il condizionamento dell'identità tramiteLoraLoaderModelOnly(#5573). - Questo stadio assicura che il generatore comprenda il tuo prompt, abbia le giuste pile di decodifica, ed è pronto con guida di efficienza e bias di identità.
- Generalmente non modifichi nulla qui oltre a scambiare checkpoint o LoRA se hai alternative.
- Il grafo carica il checkpoint di base con
- Impostazione Video
- Controlla le dimensioni di output, il frame rate, i passaggi e la lunghezza.
Larghezza(#5284),Altezza(#5286), eFrame Rate(#5289) alimentano una piccola utility che calcola i fotogrammi totali dai secondi, mantenendo il tempo coerente tra audio e video. - Le impostazioni sono memorizzate una volta e lette da tutti i nodi a valle in modo che i due campionatori e il muxer rimangano allineati.
- Regola questi valori prima quando desideri un aspetto diverso, fluidità o durata.
- Controlla le dimensioni di output, il frame rate, i passaggi e la lunghezza.
- Carica Immagine di Riferimento
- Fornisci una singola immagine chiara del viso tramite
Load Image (Input)(#5525). L'immagine è ridimensionata conImageResizeKJv2(#5280) per abbinare il tuo output scelto. - Questa immagine preprocessata diventa l'ancora per l'identità nella fase LTX 2.3 ID-LoRA, guidando la somiglianza e la composizione dello scatto.
- Usa una foto ben illuminata, frontale, con sfocatura minima per i migliori risultati.
- Fornisci una singola immagine chiara del viso tramite
- Preprocessa Audio
- Inserisci un breve WAV o MP3 usando
Reference Audio (Input)(#5652). Il clip è tagliato se necessario e poi passato aMelBandRoFormerSampler(#5473) per isolare le voci. - Voci pulite aiutano il modello a dedurre i fonemi e il timing per movimenti labiali accurati e ritmo del discorso.
- Se il tuo audio è già solo voce, puoi saltare la separazione e alimentarlo direttamente.
- Inserisci un breve WAV o MP3 usando
- Campionamento LTX Con ID Lora
- Questo è il percorso principale. Il sottografo del campionatore (
Samplers(#5278)) combina il tuo prompt positivo daEnhanced Prompt (Positive)(#5174), la lista negativa, il riferimento del viso e la traccia vocale attraverso la pipeline latente AV di LTX-2.3. LTXVReferenceAudioallinea il movimento con il discorso mentreLTXVImgToVideoInplaceinietta l'immagine del viso nel video latente come un ancoraggio. L'adattatore LTX 2.3 ID-LoRA indirizza il generatore verso l'identità del tuo soggetto.- Lo stadio include un upscaler latente interno per sollevare il dettaglio prima della decodifica. Produce fotogrammi più un flusso audio sincronizzato.
- Questo è il percorso principale. Il sottografo del campionatore (
- Campionamento LTX Senza ID Lora
- Un campionatore speculare (
Samplers(#5643)) esegue lo stesso condizionamento ma senza l'adattatore ID-LoRA. Usalo per controlli A/B o quando desideri più libertà lontano dall'identità di riferimento. - Tutto il resto rimane identico, quindi le differenze che noti sono dovute solo al condizionamento dell'identità.
- Questo percorso può essere utile per bozze rapide o deviazioni creative.
- Un campionatore speculare (
- Combina Video e Output
- I fotogrammi e l'audio generato sono muxed in MP4 con
Video Combine (Output)(#5218). Il frame rate proviene dalla tua impostazione globale, quindi movimento e sincronizzazione labiale corrispondono al timing del campionatore. - Il
Video Combinesecondario (#5645) visualizza in anteprima il ramo senza ID-LoRA se lo hai abilitato, il che è utile per i confronti. - Il flusso di lavoro pulisce la cache tra i run per mantenere stabile la VRAM in sessioni lunghe.
- I fotogrammi e l'audio generato sono muxed in MP4 con
Nodi chiave nel flusso di lavoro Comfyui LTX 2.3 ID-LoRA#
LoraLoaderModelOnly(#5573)- Carica il LTX 2.3 ID-LoRA che preserva l'identità facciale. Riduci il suo peso se desideri più variazioni creative o aumentalo per bloccare più strettamente la somiglianza. Abbinalo con attenzione alla forza del prompt affinché identità e stile non competano. Riferimento: uso di LTX-2.3 LoRA sulla pagina del modello. Model card
LTXVReferenceAudio(#5589)- Converte il tuo audio di riferimento in condizionamento per timing delle sillabe, prosodia e forme della bocca. Alimenta un discorso pulito per il miglior allineamento. Se senti pompare o articolazione fuori tempo, accorcia o semplifica il clip piuttosto che aumentare la forza.
LTXVImgToVideoInplace(#5245, usato anche dopo)- Inietta l'immagine del viso nel flusso video latente come un priore spaziale. Il controllo della forza dell'immagine bilancia l'aderenza alla foto rispetto alla libertà di movimento. Per una forte identità con movimento naturale, mantieni la forza dell'immagine moderata e lascia che l'ID-LoRA porti la somiglianza.
LTXVConditioning(#5621)- Confeziona il condizionamento del testo e i segnali di timing per i campionatori LTX. Assicurati che il suo input di frame-rate corrisponda al tuo frame rate di output affinché i campi di movimento e il timing dei fonemi rimangano coerenti.
VHS_VideoCombine(#5218)- Muxa fotogrammi e audio al file finale. Se il tuo audio è leggermente più lungo dei fotogrammi, abilita il taglio qui per evitare una coda nera finale. Per la compatibilità della piattaforma, mantieni le impostazioni H.264 predefinite a meno che non ci sia una ragione per cambiarle. Riferimento nodo: ComfyUI-VideoHelperSuite
MelBandRoFormerSampler(#5473)- Separa le voci dalla musica usando un trasformatore Mel-band in modo che il generatore si blocchi sul discorso. Se le sibilanti si sfocano o le esplosive scoppiano, prova un file modello diverso della stessa famiglia o riduci il volume di input. Letture di sfondo: arXiv
Extra opzionali#
- Per generazioni più stabili con LTX-2.3, usa larghezza e altezza divisibili per 32 e scegli un conteggio dei fotogrammi di 8n + 1 come documentato da Lightricks. Model card
- Mantieni l'immagine di riferimento coerente con il tuo prompt. Se descrivi un'illuminazione esterna ma fornisci una foto interna, l'identità può mantenersi mentre colore e ombreggiatura combattono il prompt.
- Dai all'audio 2 a 8 secondi con ritmo naturale. Clip sovra-compressi o riverberanti riducono la fedeltà della sincronizzazione labiale anche dopo la separazione vocale.
- Quando i volti si spostano, abbassa leggermente la forza dell'immagine e affidati di più al LTX 2.3 ID-LoRA. Quando i volti vagano troppo, fai il contrario.
- Per riprese più lunghe, genera in segmenti che condividono lo stesso seed e impostazioni globali, quindi unisci i clip in editing video se necessario.
Riferimenti e repository utili#
- Pesi aperti e note LTX-2.3: Pagina modello Hugging Face
- Nodi ufficiali ComfyUI per video LTX: Lightricks/ComfyUI-LTXVideo
- Codice base e paper LTX-2: Lightricks/LTX-Video · arXiv
- Codificatori IT Gemma 3 12B per LTX in ComfyUI: Comfy-Org/ltx-2 text_encoders
- Sfondo Mel-Band RoFormer: arXiv
Ringraziamenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo sinceramente i creatori del flusso di lavoro LTX 2.3 ID-LoRA Source per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- LTX 2.3 ID-LoRA Source
- Documenti / Note di rilascio: YouTube @Benji’s AI Playground
Nota: L'uso dei modelli, dataset e codice referenziati è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.