
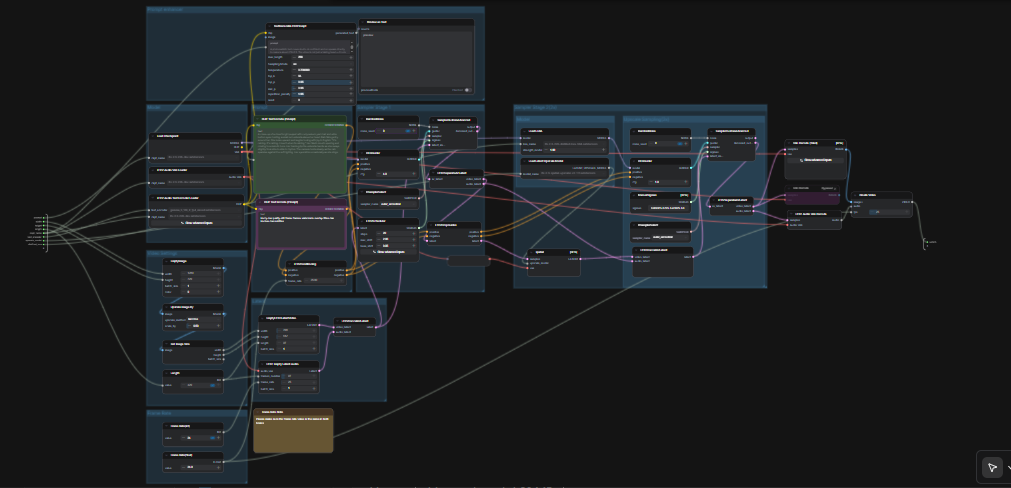
LTX 2.3 ComfyUI: Da Testo a Video con audio pulito, campionamento a due fasi e upscaling spaziale 2×#
Questo workflow LTX 2.3 ComfyUI trasforma brevi prompt in video cinematografici rifiniti con audio sincronizzato. È costruito attorno al modello LTX-2.3 di Lightricks e configurato per alta coerenza visiva, movimento stabile e output adatto alla trasmissione. Creatori, editori e artisti tecnici possono passare da un singolo prompt a un MP4 con audio in un unico passaggio, utilizzando un grafico semplificato che include un potenziatore di prompt, due fasi di campionamento e un upscaler latente 2×.
Rispetto alle configurazioni tipiche da testo a video, questo grafico enfatizza la consistenza delle scene e la fedeltà del prompt. Il percorso predefinito genera un latente AV, lo scala in spazio latente per dettagli più nitidi, quindi decodifica in fotogrammi e audio prima di confezionare tutto in un file video pronto per essere condiviso. Se stai esplorando modelli video open-source moderni, questo workflow LTX 2.3 ComfyUI è un modo rapido per ottenere movimento di qualità produttiva.
Modelli chiave nel workflow LTX 2.3 ComfyUI#
- LTX-2.3 22B (dev) checkpoint di Lightricks. Il modello core da testo a video che produce movimento ad alta coerenza e forte consistenza delle scene. Hugging Face • GitHub
- Gemma 3 12B Instruct text encoder (FP4 mixed). Fornisce una robusta comprensione del linguaggio per un migliore ancoraggio del prompt e dettagli di scena più ricchi. Hugging Face
- LTX-2.3 Spatial Upscaler x2 1.0. Un upscaler in spazio latente che affina i dettagli spaziali senza rompere la consistenza del movimento. Hugging Face
- LTX-2.3 22B Distilled LoRA (384). Un adattatore distillato che affina la fedeltà delle texture e stabilizza lo stile durante la fase di upscaling/raffinamento. Hugging Face
- LTX Audio VAE. Il modulo audio associato a LTX-2.3 che consente la generazione di suoni puliti e sincronizzati dallo stesso prompt. Hugging Face
Come usare il workflow LTX 2.3 ComfyUI#
Il grafico funziona in due passaggi coordinati. Prima genera un latente AV a una risoluzione di lavoro con il tuo prompt. Poi esegue un upscaling latente 2× e un secondo passaggio di campionamento con un LoRA distillato prima di decodificare in fotogrammi e audio, infine muxando in MP4.
Potenziatore di prompt#
Il nodo TextGenerateLTX2Prompt (#149) riscrive il linguaggio semplice in un prompt amichevole per il modello che copre azioni, elementi visivi e suggerimenti audio. Inserisci la descrizione della tua scena; immagini di riferimento opzionali possono essere collegate quando desideri una guida per l'inquadratura o lo stile. Il testo generato viene instradato a un encoder positivo mentre un prompt negativo incentrato sulla qualità riduce gli artefatti. Questo equilibrio aiuta il modello LTX-2.3 a rimanere sul compito senza vincolare eccessivamente la creatività.
Modello#
Il CheckpointLoaderSimple (#146) carica il checkpoint LTX-2.3 22B ed espone sia il modello che il suo VAE. LTXAVTextEncoderLoader (#147) introduce l'encoder di testo Gemma 3 12B Instruct che il workflow utilizza per il condizionamento positivo e negativo. Mantieni queste selezioni a meno che non stai testando altre varianti LTX, poiché il resto del grafico è sintonizzato per questo abbinamento.
Impostazioni video#
Risoluzione e durata sono impostate con un'immagine leggera e il controllo Length. Il grafico legge la dimensione dell'immagine, la scala per una risoluzione di lavoro e inoltra quei valori al creatore di latente video. I modelli LTX hanno vincoli di stride; attieniti a dimensioni che seguono un pattern di stride 32 e lunghezze che si allineano con la cadenza dei fotogrammi del modello. Il grafico adatta delicatamente i valori illegali ai più vicini validi, ma scegliere dimensioni valide in anticipo offre la migliore composizione.
Frame Rate#
Due piccoli controlli impostano FPS per il condizionamento e la codifica finale: Frame Rate(int) (#141) e Frame Rate(float) (#140). Mantienili identici in modo che il timing del movimento e l'allineamento audio rimangano consistenti lungo la pipeline. Scegli un tasso filmico se vuoi un movimento più fluido o abbina i valori predefiniti della piattaforma quando prendi di mira formati social.
Latente#
EmptyLTXVLatentVideo (#121) inizializza il latente video e LTXVEmptyLatentAudio (#119) fa lo stesso per l'audio. LTXVConcatAVLatent (#122) li unisce in un unico latente AV in modo che la guida del testo possa orientare entrambe le modalità insieme. LTXVConditioning (#120) attacca il condizionamento positivo e negativo, e LTXVCropGuides (#115) adatta la guida al layout spaziale del latente per un'inquadratura più affidabile.
Fase di campionamento 1#
Questa fase crea il latente AV iniziale usando RandomNoise (#151), KSamplerSelect (#144) e il LTXVScheduler (#112) consapevole di LTX con un CFGGuider (#139). Il scheduler è adattato per LTX per bilanciare la stabilità temporale con l'aderenza al prompt. Se vuoi più variazione, cambia il seme del rumore; per un'aderenza più stabile allo script, preferisci campionatori che mantengono la coerenza temporale.
Modello (LoRA)#
LoraLoaderModelOnly (#143) applica il LoRA distillato LTX-2.3 prima del raffinamento. Questo adattatore migliora sottilmente la lucentezza delle texture e la fedeltà dello stile senza perdere la consistenza del movimento. È più evidente su pelle, tessuto e riflessi speculari.
Campionamento di upscaling (2×)#
LTXVLatentUpsampler (#130) esegue un upscaling spaziale 2× in spazio latente usando il LatentUpscaleModelLoader (#114) caricato e il VAE di base. Poiché l'upscaling avviene prima della decodifica, mantieni la fluidità temporale mentre guadagni dettagli spaziali fini. I latenti video e audio upscalati sono quindi riuniti con LTXVConcatAVLatent (#129) per il passaggio di raffinamento.
Fase di campionamento 2 (2×)#
Il secondo passaggio raffina il latente upscalato usando RandomNoise (#127), KSamplerSelect (#145) e una pianificazione ManualSigmas (#113) sotto un CFGGuider (#116). Questa fase è dove i micro-dettagli e la nitidezza dei bordi vengono finalizzati. Funziona meglio quando il LoRA è attivo e il prompt è specifico su texture e illuminazione.
Decodifica e Output#
LTXVSeparateAVLatent (#135) divide il latente raffinato in modo che VAEDecodeTiled (#137) possa ricostruire i fotogrammi mentre LTXVAudioVAEDecode (#138) ripristina l'audio. CreateVideo (#133) muxa fotogrammi e audio al FPS scelto, e il nodo di livello superiore SaveVideo scrive un MP4 nella cartella video del workflow. Il risultato è un file pulito e pronto per essere condiviso prodotto interamente all'interno della pipeline LTX 2.3 ComfyUI.
Nodi chiave nel workflow LTX 2.3 ComfyUI#
TextGenerateLTX2Prompt(#149): Converte descrizioni semplici in prompt strutturati che coprono movimento, attributi visivi e audio. Modifica il tuo linguaggio qui prima quando indirizzi i battiti della storia o il ritmo; di solito produce guadagni maggiori rispetto alle modifiche del campionatore.LTXVScheduler(#112): Uno scheduler specifico per LTX che modella come il rumore viene rimosso nel tempo. Abbinalo con attenzione al campionatore scelto per bilanciare la stabilità temporale e la fedeltà del prompt.LTXVLatentUpsampler(#130): Esegue un upscaling spaziale 2× direttamente in spazio latente, preservando la continuità del movimento mentre aggiunge dettagli nitidi. Usalo quando vuoi risultati più nitidi senza ricorrere a upscaler post-decodifica.LoraLoaderModelOnly(#143): Applica il LoRA distillato LTX-2.3 per il raffinamento. Aumenta l'influenza per un controllo più stretto dello stile; riducila se vuoi un aspetto più ampio del modello base.CreateVideo(#133): Muxa fotogrammi decodificati con audio generato al FPS selezionato in modo che il timing e la sincronizzazione labiale rimangano intatti. Se cambi FPS, mantieni entrambi i controlli del framerate corrispondenti.
Extra opzionali#
- Suggerimenti per il prompting: Descrivi azioni nel tempo, elenca elementi visivi chiave e specifica il suono o il dialogo che ti aspetti. Frasi chiare e concise danno il miglior segnale all'encoder LTX-2.3.
- Dimensioni e lunghezza: Preferisci dimensioni su uno stride 32 e lunghezze che rispettano la cadenza dei fotogrammi del modello. Sebbene il grafico adatti automaticamente i valori vicino-miss, input validi migliorano la composizione e riducono il leggero tremolio.
- Iterazione rapida: Cambia il seme di
RandomNoisetra le esecuzioni per esplorare varianti mantenendo lo stesso prompt e impostazioni. - Cambio di modello: I predefiniti sono sintonizzati per LTX-2.3 22B con Gemma 3 12B IT e l'upscaler spaziale 2×. Scambia i modelli solo se comprendi come ognuno influisce sul condizionamento e sulla decodifica.
Ringraziamenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine Lightricks per il modello LTX-2.3 e EyeForAILabs per il tutorial su YouTube per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: 2601.03233
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: YouTube Channel from @eyeforailabs
Nota: L'uso dei modelli, set di dati e codice referenziati è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.
