
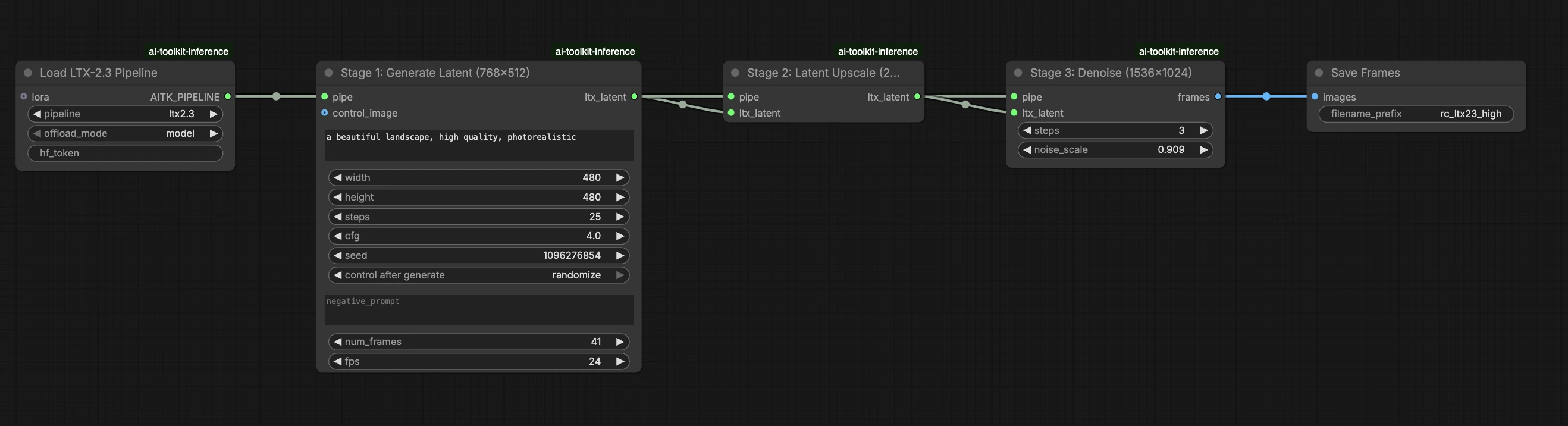
LTX 2.3 LoRA ComfyUI Inferenza: output LoRA di AI Toolkit corrispondente all'addestramento con la pipeline LTX 2.3#
Questo workflow RunComfy pronto per la produzione esegue l'inferenza LTX 2.3 LoRA in ComfyUI tramite RC LTX 2.3 (LTX2Pipeline) (allineamento a livello di pipeline, non un grafico di campionamento generico). RunComfy ha costruito e reso open-source questo nodo personalizzato—vedi i repository runcomfy-com—e puoi controllare l'applicazione dell'adattatore con lora_path e lora_scale.
Nota: questo workflow richiede una macchina 2X Large o più grande per funzionare.
Perché l'inferenza LTX 2.3 LoRA ComfyUI appare spesso diversa in ComfyUI#
Le anteprime di addestramento di AI Toolkit sono renderizzate attraverso una pipeline LTX 2.3 specifica del modello, dove la codifica del testo, la pianificazione e l'iniezione di LoRA sono progettate per funzionare insieme. In ComfyUI, ricostruendo LTX 2.3 con un grafico diverso (o un percorso di caricamento di LoRA diverso) può cambiare queste interazioni, quindi copiando lo stesso prompt, passaggi, CFG e seed si produce ancora una deriva visibile. I nodi della pipeline RC di RunComfy colmano questo divario eseguendo LTX 2.3 end-to-end in LTX2Pipeline e applicando il tuo LoRA all'interno di quella pipeline, mantenendo l'inferenza allineata al comportamento di anteprima. Fonte: RunComfy repository open-source.
Come utilizzare il workflow LTX 2.3 LoRA ComfyUI Inferenza#
Passo 1: Ottieni il percorso LoRA e caricalo nel workflow (2 opzioni)#
Opzione A — Risultato di addestramento RunComfy → download su ComfyUI locale:
- Vai a Trainer → LoRA Assets
- Trova il LoRA che vuoi usare
- Clicca sul menu ⋮ (tre punti) a destra → seleziona Copia Link LoRA
- Nella pagina del workflow ComfyUI, incolla il link copiato nel campo di input Download nell'angolo in alto a destra dell'UI
- Prima di cliccare su Download, assicurati che la cartella di destinazione sia impostata su ComfyUI > models > loras (questa cartella deve essere selezionata come destinazione del download)
- Clicca Download — questo assicura che il file LoRA venga salvato nella directory corretta
models/loras - Dopo che il download è terminato, aggiorna la pagina
- Il LoRA ora appare nel menu a tendina di selezione LoRA nel workflow — selezionalo
Opzione B — URL diretto LoRA (sovrascrive l'Opzione A):
- Incolla l'URL diretto di download
.safetensorsnel campo di inputpath / urldel nodo LoRA - Quando un URL è fornito qui, sovrascrive l'Opzione A — il workflow carica il LoRA direttamente dall'URL a runtime
- Non è richiesto alcun download locale o posizionamento del file
Suggerimento: conferma che l'URL risolva al file .safetensors effettivo (non una pagina di destinazione o un reindirizzamento).
Passo 2: Abbina i parametri di inferenza con le impostazioni del tuo campione di addestramento#
Nel nodo LoRA, seleziona il tuo adattatore in lora_path (Opzione A), o incolla un link diretto .safetensors in path / url (Opzione B sovrascrive il menu a tendina). Quindi imposta lora_scale alla stessa intensità che hai utilizzato durante le anteprime di addestramento e regolalo da lì.
I parametri rimanenti sono sul nodo Generate (e, a seconda del grafico, sul nodo Load Pipeline):
prompt: il tuo prompt di testo (includi parole chiave se hai addestrato con esse)width/height: risoluzione di output; abbina la dimensione dell'anteprima di addestramento per il confronto più pulito (multipli di 32 sono raccomandati per LTX 2.3)num_frames: numero di fotogrammi video di outputsample_steps: numero di passaggi di inferenza (30 è un valore predefinito comune)guidance_scale: valore di guida CFG (5.5 è un valore predefinito comune; non superare 7)seed: seed fisso per riprodurre; cambialo per esplorare variazioniseed_mode(solo se presente): sceglifixedorandomizeframe_rate: FPS di output; mantieni coerente con le impostazioni di addestramento per l'allineamento del movimento
Suggerimento di allineamento dell'addestramento: se hai personalizzato i valori di campionamento durante l'addestramento (seed, guidance_scale, sample_steps, parole chiave, risoluzione), rispecchia quegli esatti valori qui. Se hai addestrato su RunComfy, apri Trainer → LoRA Assets > Config per visualizzare lo YAML risolto e copiare le impostazioni di anteprima/campione nei nodi del workflow.
Passo 3: Esegui LTX 2.3 LoRA ComfyUI Inferenza#
Clicca Queue/Run — il nodo SaveVideo scrive i risultati nella tua cartella di output ComfyUI.
Lista di controllo rapida:
- ✓ LoRA è: scaricato in
ComfyUI/models/loras(Opzione A), o caricato tramite un URL diretto.safetensors(Opzione B) - ✓ Pagina aggiornata dopo il download locale (solo Opzione A)
- ✓ I parametri di inferenza corrispondono alla configurazione di
sampledell'addestramento (se personalizzati)
Se tutto quanto sopra è corretto, i risultati di inferenza qui dovrebbero corrispondere da vicino alle tue anteprime di addestramento.
Risoluzione dei problemi nell'inferenza LTX 2.3 LoRA ComfyUI#
La maggior parte delle discrepanze "anteprima di addestramento vs inferenza ComfyUI" LTX 2.3 derivano da differenze a livello di pipeline (come il modello è caricato, pianificato e come il LoRA è fuso), non da un singolo parametro errato. Questo workflow RunComfy ripristina il più vicino "baseline corrispondente all'addestramento" eseguendo l'inferenza tramite RC LTX 2.3 (LTX2Pipeline) end-to-end e applicando il tuo LoRA all'interno di quella pipeline tramite lora_path / lora_scale (invece di impilare nodi di caricamento/campionamento generici).
(1) Incongruenze di forma LoRA o avvisi "chiave non caricata"#
Perché succede Il LoRA è stato addestrato per una diversa famiglia di modelli o una variante LTX diversa. Vedrai molte righe lora key not loaded e potenzialmente errori di incongruenza di forma.
Come risolvere (consigliato)
- Assicurati che il LoRA sia stato addestrato specificamente per LTX 2.3 con AI Toolkit (LTX 2.0 / 2.1 / 2.2 LoRA non sono intercambiabili).
- Mantieni il grafico "single-path" per LoRA: carica l'adattatore solo tramite l'input
lora_pathdel workflow e lascia che LTX2Pipeline gestisca la fusione. Non impilare un caricatore LoRA generico aggiuntivo in parallelo. - Se hai già riscontrato un'incongruenza e ComfyUI inizia a produrre errori CUDA/OOM non correlati successivamente, riavvia il processo ComfyUI per reimpostare completamente lo stato della GPU + modello, quindi riprova con un LoRA compatibile.
(2) I risultati dell'inferenza non corrispondono alle anteprime di addestramento#
Perché succede Anche quando il LoRA viene caricato, i risultati possono ancora variare se il tuo grafico ComfyUI non corrisponde alla pipeline di anteprima di addestramento (valori predefiniti diversi, percorso di iniezione LoRA diverso, pianificazione diversa).
Come risolvere (consigliato)
- Usa questo workflow e incolla il tuo link diretto
.safetensorsinlora_path. - Copia i valori di campionamento dalla tua configurazione di addestramento AI Toolkit (o RunComfy Trainer → LoRA Assets Config):
width,height,num_frames,sample_steps,guidance_scale,seed,frame_rate. - Mantieni "extra speed stacks" fuori dal confronto a meno che tu non abbia addestrato/campionamento con essi.
(3) L'uso di LoRA aumenta significativamente il tempo di inferenza#
Perché succede Un LoRA può rendere LTX 2.3 molto più lento quando il percorso LoRA forza lavoro extra di patch/dequantizzazione o applica pesi in un percorso di codice più lento rispetto al solo modello base.
Come risolvere (consigliato)
- Usa il percorso RC LTX 2.3 (LTX2Pipeline) di questo workflow e passa il tuo adattatore tramite
lora_path/lora_scale. In questa configurazione, il LoRA viene fuso una volta durante il caricamento della pipeline (stile AI Toolkit), quindi il costo di campionamento per passo rimane vicino al modello base. - Quando cerchi di ottenere un comportamento che corrisponde all'anteprima, evita di impilare più caricatori LoRA o di mescolare percorsi di caricamento. Mantienilo a uno
lora_path+ unolora_scalefinché la baseline non corrisponde.
(4) Errori OOM su risoluzioni grandi o video lunghi#
Perché succede LTX 2.3 è un modello da 22B parametri e la generazione video è intensiva in termini di VRAM. Alte risoluzioni o molti fotogrammi possono superare la memoria della GPU, specialmente con l'overhead di LoRA.
Come risolvere (consigliato)
- Usa una macchina 2X Large (80 GB VRAM) o più grande. Questo workflow non è compatibile con macchine Medium, Large o X Large.
- Riduci la risoluzione o il conteggio dei fotogrammi se hai bisogno di iterare rapidamente, quindi scala per i rendering finali.
- Abilita il tiling VAE se disponibile — può risparmiare ~3 GB di VRAM con una perdita di qualità minima.
Esegui ora LTX 2.3 LoRA ComfyUI Inferenza#
Apri il workflow, imposta lora_path, e clicca Queue/Run per ottenere risultati LTX 2.3 LoRA che restano vicini alle tue anteprime di addestramento AI Toolkit.
