
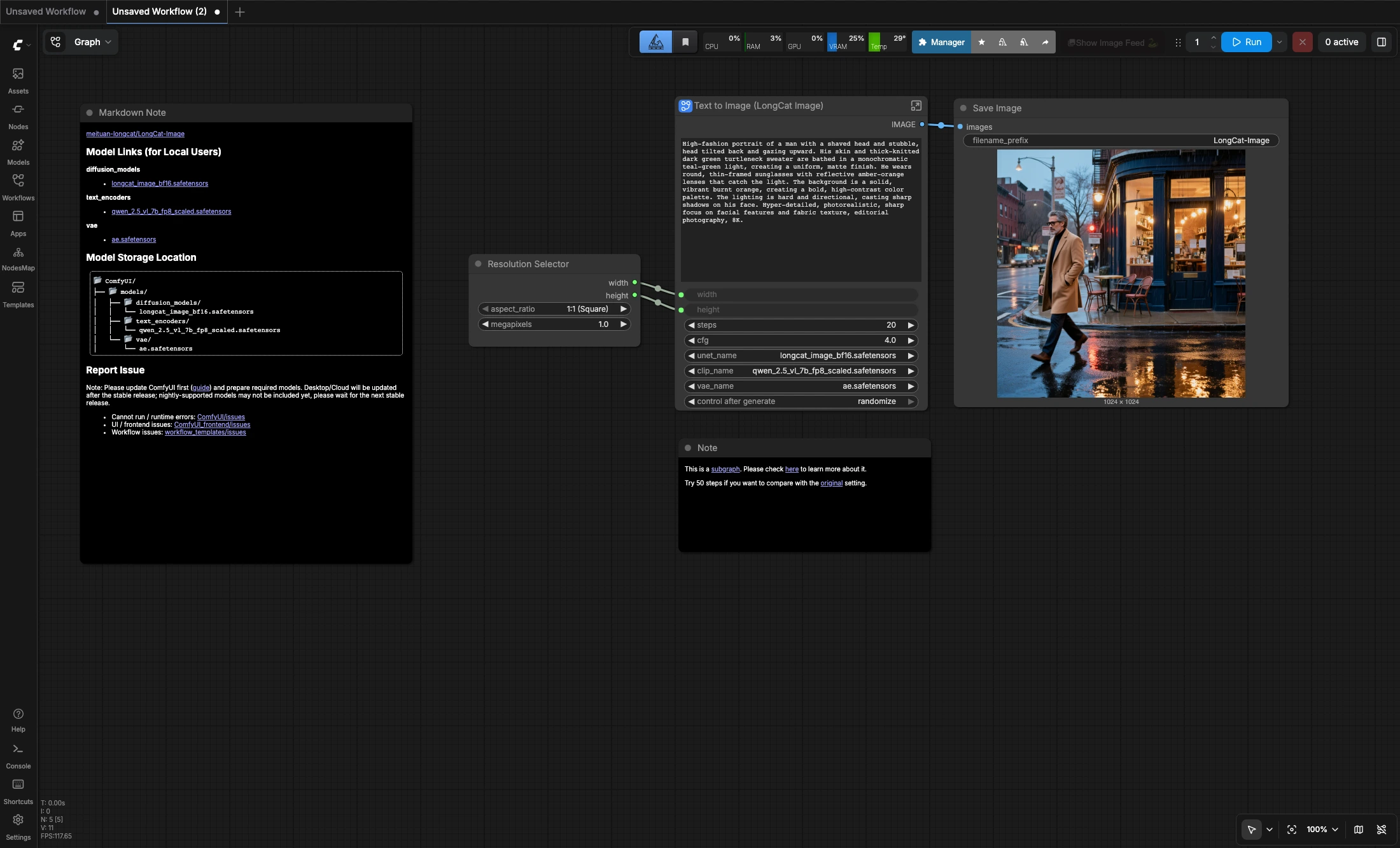



Cos'è il flusso di lavoro ComfyUI LongCat Image da testo a immagine?#
LongCat Image da testo a immagine è un flusso di lavoro ComfyUI compatto per generare immagini quadrate 1024x1024 da prompt testuali. Utilizza il modello di diffusione LongCat-Image insieme all'encoder di testo Qwen 2.5 VL e l'AE VAE, offrendoti un'impostazione semplice da prompt a immagine per ritratti, foto di prodotti e visuali in stile editoriale rifinite.
Il grafico è intenzionalmente semplice: scegli una risoluzione quadrata, scrivi il tuo prompt, esegui il flusso di lavoro e salva l'immagine. Funziona bene per iterazioni rapide con prompt in inglese o cinese, e la nota inclusa suggerisce di provare 50 passaggi se vuoi confrontare il risultato con l'impostazione del modello originale.
Caratteristiche principali di LongCat Image da testo a immagine#
- Generazione incentrata su quadrati: L'impostazione predefinita è ottimizzata per un output 1:1 a 1024x1024.
- Design del flusso di lavoro compatto: Il grafico rimane focalizzato sulla generazione da prompt a immagine senza complessità di instradamento aggiuntive.
- Prompting flessibile: Adatto per prompt testuali in inglese e cinese.
- Facile regolazione della qualità: Parti dall'impostazione predefinita di 20 passaggi, poi aumenta i passaggi quando desideri un campionamento più lento ma più deliberato.
Come usare LongCat Image in ComfyUI#
- Scegli la dimensione dell'output
- Usa il nodo
Resolution Selectorper mantenere il layout quadrato predefinito o regolare i megapixel di destinazione se necessario.
- Usa il nodo
- Scrivi il tuo prompt
- Apri il sottografo
Text to Image (LongCat Image)e sostituisci il prompt predefinito con le tue istruzioni su soggetto, illuminazione, atmosfera e composizione.
- Apri il sottografo
- Esegui il flusso di lavoro
- Metti in coda il grafico per generare un'unica immagine dal tuo prompt.
- Salva il risultato
- Il nodo
Save Imagescrive l'output finale una volta completata l'esecuzione.
- Il nodo
Suggerimenti e impostazioni#
- L'attuale impostazione predefinita funziona a 20 passaggi con CFG 4.
- Se vuoi confrontare con la raccomandazione originale del flusso di lavoro sorgente, prova 50 passaggi.
- I prompt chiari e concreti tendono a funzionare meglio rispetto a frammenti di prompt ampi o astratti in questo grafico compatto.
Risorse#
- Fonte del flusso di lavoro: Comfy.org workflow page
- Modello ufficiale: meituan-longcat/LongCat-Image on Hugging Face

