

IDM-VTON, abbreviazione di "Miglioramento dei modelli di diffusione per la prova d'abbigliamento virtuale autentica nel mondo reale," è un modello di diffusione innovativo che ti permette di provare realisticamente i capi virtualmente utilizzando solo pochi input. Ciò che distingue IDM-VTON è la sua capacità di preservare i dettagli unici e l'identità dei capi generando risultati di prova virtuali che sembrano incredibilmente autentici.
1. Comprendere IDM-VTON#
Alla base, IDM-VTON è un modello di diffusione progettato specificamente per la prova virtuale. Per usarlo, hai semplicemente bisogno di una rappresentazione di una persona e di un capo che vuoi provare. IDM-VTON poi fa la sua magia, rendendo un risultato che sembra che la persona stia effettivamente indossando il capo. Raggiunge un livello di fedeltà e autenticità dei capi che supera i precedenti metodi di prova virtuale basati sulla diffusione.
2. Il funzionamento interno di IDM-VTON#
Allora, come fa IDM-VTON a realizzare una prova virtuale così realistica? Il segreto sta nei suoi due moduli principali che lavorano insieme per codificare le semantiche dell'input del capo:
- Il primo è un adattatore di prompt immagine, o IP-Adapter in breve. Questo componente intelligente estrae le semantiche di alto livello del capo - essenzialmente, le caratteristiche chiave che definiscono il suo aspetto. Queste informazioni vengono poi fuse nel livello di attenzione incrociata del modello UNet principale di diffusione.
- Il secondo modulo è un UNet parallelo chiamato GarmentNet. Il suo compito è codificare le caratteristiche di basso livello del capo - i dettagli nitidi che lo rendono unico. Queste caratteristiche vengono poi fuse nel livello di autoattenzione del modello UNet principale.
Ma non è tutto! IDM-VTON utilizza anche prompt testuali dettagliati sia per il capo che per gli input della persona. Questi prompt forniscono un contesto aggiuntivo che migliora l'autenticità del risultato finale della prova virtuale.
3. Mettere al lavoro IDM-VTON in ComfyUI#
3.1 La star dello spettacolo: Il nodo IDM-VTON#
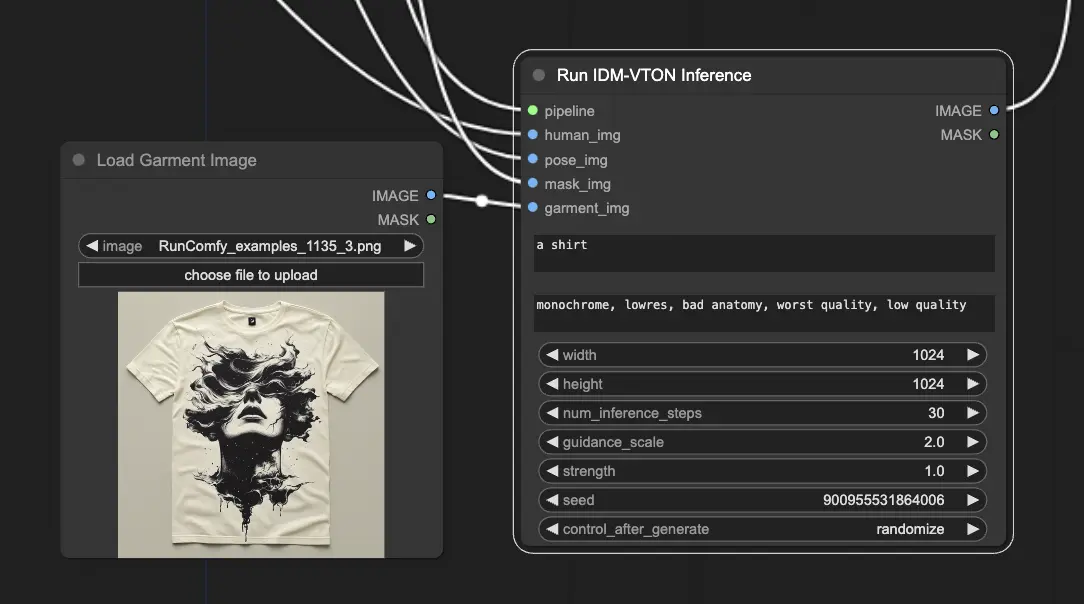
In ComfyUI, il nodo "IDM-VTON" è il motore che esegue il modello di diffusione IDM-VTON e genera l'output della prova virtuale.
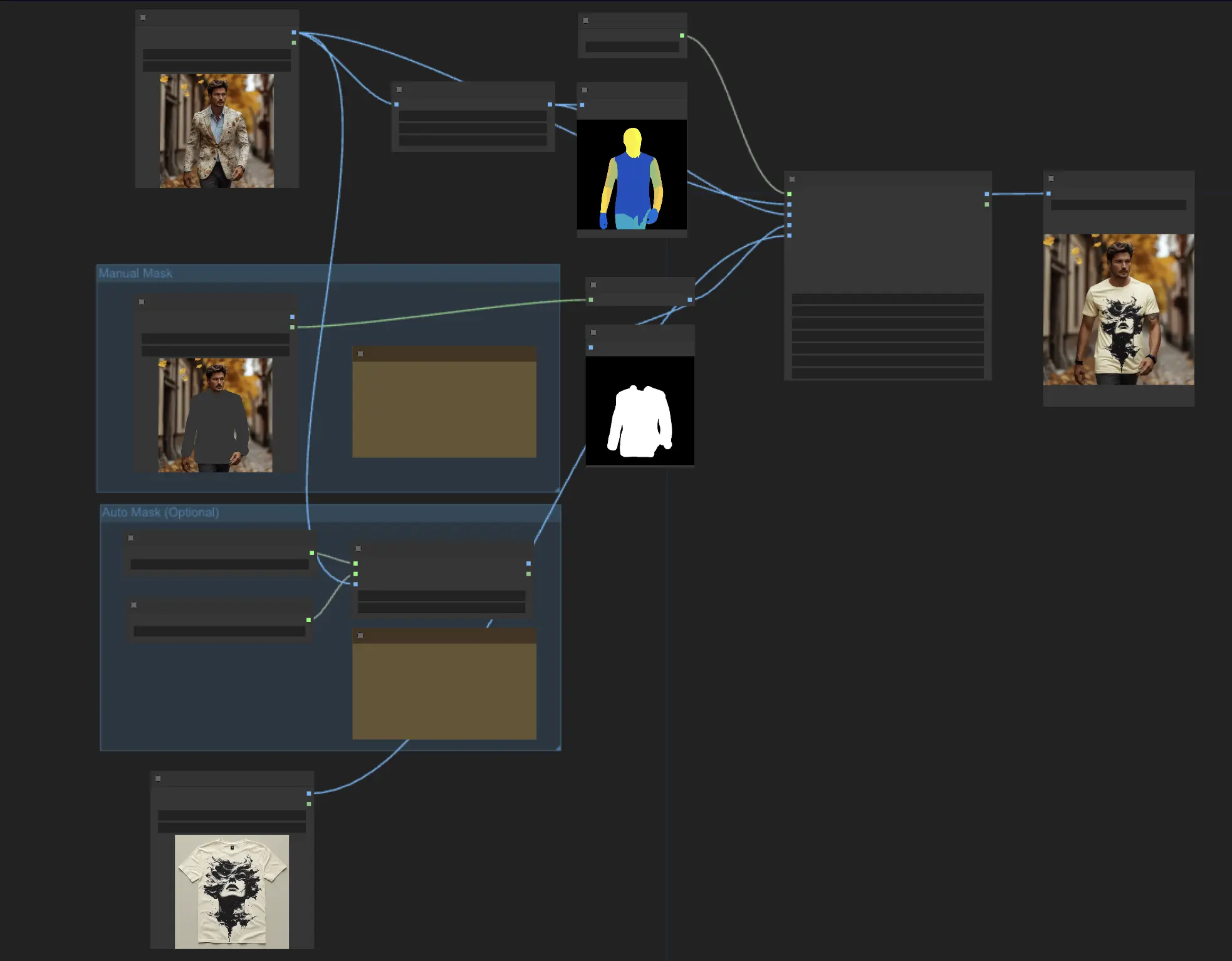
Per far funzionare il nodo IDM-VTON, sono necessari alcuni input chiave:
- Pipeline: Questa è la pipeline di diffusione IDM-VTON caricata che alimenta l'intero processo di prova virtuale.
- Human Input: Un'immagine della persona che proverà virtualmente il capo.
- Pose Input: Una rappresentazione DensePose preprocessata dell'input umano, che aiuta IDM-VTON a comprendere la posa e la forma del corpo della persona.
- Mask Input: Una maschera binaria che indica quali parti dell'input umano sono abbigliamento. Questa maschera deve essere convertita in un formato appropriato.
- Garment Input: Un'immagine del capo da provare virtualmente.
3.2 Preparare tutto#
Per far funzionare il nodo IDM-VTON, ci sono alcuni passaggi di preparazione:
- Caricamento dell'immagine umana: Si utilizza un nodo LoadImage per caricare l'immagine della persona. <img src="https://cdn.runcomfy.net/workflow_assets/1135/readme01.webp" alt="IDM-VTON" width="500" />
- Generazione dell'immagine della posa: L'immagine umana viene passata attraverso un nodo DensePosePreprocessor, che calcola la rappresentazione DensePose di cui IDM-VTON ha bisogno. <img src="https://cdn.runcomfy.net/workflow_assets/1135/readme02.webp" alt="IDM-VTON" width="500" />
- Ottenere l'immagine della maschera: Ci sono due modi per ottenere la maschera dell'abbigliamento: <img src="https://cdn.runcomfy.net/workflow_assets/1135/readme03.webp" alt="IDM-VTON" width="500" />
a. Mascheramento manuale (consigliato)
- Fare clic con il tasto destro sull'immagine umana caricata e scegliere "Apri nell'editor di maschere."
- Nell'interfaccia dell'editor di maschere, maschera manualmente le regioni dell'abbigliamento.
b. Mascheramento automatico
- Utilizzare un nodo GroundingDinoSAMSegment per segmentare automaticamente l'abbigliamento.
- Suggerire al nodo una descrizione testuale del capo (come "t-shirt").
Qualunque metodo tu scelga, la maschera ottenuta deve essere convertita in un'immagine utilizzando un nodo MaskToImage, che viene poi collegato all'input "Mask Image" del nodo IDM-VTON.
- Caricamento dell'immagine del capo: Viene utilizzata per caricare l'immagine del capo.
Per un approfondimento sul modello IDM-VTON, non perdere l'articolo originale, "Improving Diffusion Models for Authentic Virtual Try-on in the Wild". E se sei interessato a usare IDM-VTON in ComfyUI, assicurati di controllare i nodi dedicati qui. Un enorme grazie ai ricercatori e sviluppatori dietro queste incredibili risorse.

