
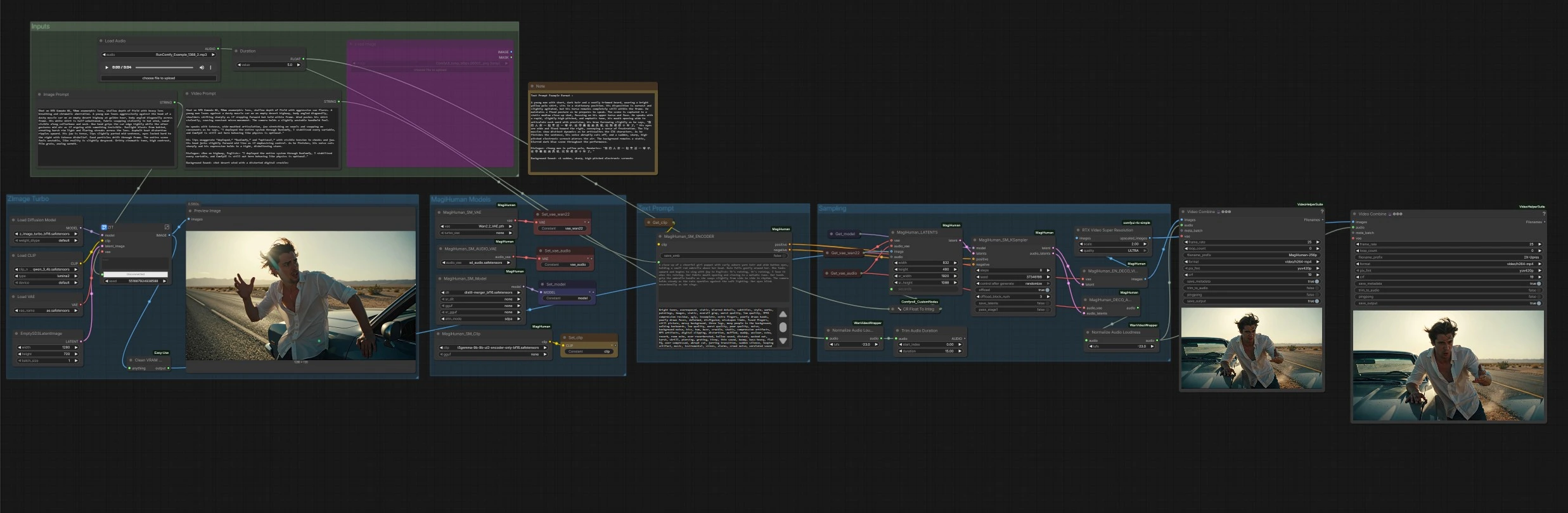
Workflow di umani digitali parlanti daVinci-MagiHuman per ComfyUI#
Questo workflow ComfyUI costruisce un'intera pipeline da testo a video attorno a daVinci-MagiHuman per generare umani digitali parlanti realistici con discorso sincronizzato, movimento labiale, espressione e micro-movimento corporeo. È progettato per creatori che desiderano un percorso veloce e a singolo clic da un prompt descrittivo a un MP4 con audio pulito. Il grafico può animare un ritratto generato ex novo o qualsiasi immagine di riferimento fornita, quindi rende video e discorso insieme, terminando con un eventuale upscaling e normalizzazione automatica della sonorità audio.
Il core daVinci-MagiHuman utilizza un Transformer a singolo flusso per co-generare video e audio da un unico prompt, il che aiuta a preservare la tempistica e la fedeltà della sincronizzazione labiale anche su clip brevi. Questa implementazione ComfyUI mantiene i controlli semplici: scrivi un Image Prompt per definire l'aspetto, un Video Prompt per definire performance e dialogo, imposta la Durata del clip e avvia.
Modelli chiave nel workflow ComfyUI daVinci-MagiHuman#
- daVinci-MagiHuman (generatore audio-video a flusso singolo da 15B). Ruolo: produce congiuntamente i fotogrammi video e il discorso dal testo mantenendo la coerenza temporale e la sincronizzazione labiale. Riferimenti: GitHub, arXiv, Hugging Face.
- Codificatore T5Gemma 9B (adattato UL2). Ruolo: codifica il Video Prompt in un ricco condizionamento che guida movimento, consegna e stile per daVinci-MagiHuman. Riferimento: Hugging Face.
- Modello di diffusione Z-Image Turbo. Ruolo: genera rapidamente un ritratto fermo di alta qualità dall'Image Prompt da usare come identità/riferimento per l'animazione. Riferimenti: Hugging Face (z_image_turbo), Hugging Face (z_image).
- Codificatore di testo Qwen 3 4B per Z-Image Turbo. Ruolo: analizza l'Image Prompt per guidare la generazione del ritratto. Riferimento: Hugging Face file.
- Wan 2.2 VAE. Ruolo: decodifica i latenti video di MagiHuman in fotogrammi RGB con forte coerenza temporale. Riferimenti: GitHub, Hugging Face example model.
- Audio VAE (sd_audio). Ruolo: decodifica i latenti audio di MagiHuman in una forma d'onda del discorso per il muxing con il video finale. Riferimento: bundle nodo personalizzato per MagiHuman GitHub.
- RTX Video Super Resolution (opzionale). Ruolo: post-upscaling dei fotogrammi decodificati per aumentare la nitidezza percepita e ridurre gli artefatti di compressione prima della codifica finale. Riferimento: wrapper ComfyUI GitHub.
Come utilizzare il workflow ComfyUI daVinci-MagiHuman#
Flusso generale: il gruppo Z-Image Turbo crea un ritratto di identità dal tuo Image Prompt. Il gruppo Modelli MagiHuman carica il checkpoint daVinci-MagiHuman, il VAE video e il VAE audio, e prepara il codificatore di testo. Il gruppo Text Prompt trasforma il tuo Video Prompt in condizionamento. Il gruppo di campionamento fonde l'immagine di riferimento e il prompt in latenti video e audio congiunti, quindi decodifica entrambi. Infine, la fase di Output muxa i fotogrammi con l'audio in MP4, con una versione opzionale upscalata.
Input#
Usa le caselle di testo Image Prompt e Video Prompt per descrivere aspetto e performance. Il controllo Durata imposta la lunghezza del clip in secondi. È presente un caricatore audio per comodità se si desidera sperimentare con varianti guidate dall'audio, ma questo template funziona in modalità guidata dal testo di default.
ZImage Turbo#
Questa fase rende un singolo ritratto di riferimento dall'Image Prompt utilizzando lo Z-Image Turbo UNet con il codificatore di testo Qwen 3 4B e il suo VAE incluso. È ottimizzato per una generazione di identità veloce e pulita con look cinematografici. Il risultato viene visualizzato in anteprima, quindi inoltrato come immagine di riferimento per l'animazione. Se hai già un primo piano, puoi bypassare questo collegando direttamente la tua immagine alla fase di animazione.
Modelli MagiHuman#
Qui il grafico carica il checkpoint base o distillato daVinci-MagiHuman insieme al VAE video Wan 2.2, al VAE audio e al codificatore T5Gemma. Questo mantiene allineati la codifica del testo, i latenti video e i latenti audio per il campionamento a flusso singolo. Puoi cambiare i pesi se hai alternative disponibili nel tuo ambiente.
Text Prompt#
Il tuo Video Prompt è codificato in condizionamento positivo e negativo. Il testo positivo dovrebbe descrivere distanza della camera, posa, lingua, stile di consegna e il contenuto esatto del dialogo. Il testo negativo può elencare difetti visivi o audio da evitare. Il codificatore alimenta entrambi i set di condizionamento nel campionatore per modellare movimento, dinamiche labiali e timbro.
Sampling#
Il campionatore costruisce una sequenza latente iniziale dall'immagine di riferimento e dalla Durata richiesta, quindi esegue la denoising con daVinci-MagiHuman per produrre latenti video e audio sincronizzati. Un'utilità converte la Durata in secondi interi per una pianificazione stabile. Al termine del campionamento, i latenti video vanno al decodificatore video e i latenti audio vanno al decodificatore audio.
Decode, loudness e export#
I latenti video sono decodificati con il Wan 2.2 VAE in fotogrammi immagine. I latenti audio sono decodificati in discorso, quindi normalizzati alla sonorità adatta alla trasmissione in modo che l'MP4 finale venga riprodotto in modo coerente su tutti i dispositivi. Sono prodotti due export: un render base e un render opzionale upscalato utilizzando RTX Video Super Resolution. Entrambi sono muxati in MP4 con audio e salvati con prefissi di nome file chiari.
Nodi chiave nel workflow ComfyUI daVinci-MagiHuman#
MagiHuman_LATENTS(#13)
Costruisce la tela latente congiunta per video e audio opzionale, prendendo l'immagine di riferimento e la lunghezza del clip. Regola seconds per impostare la durata e assicurati che la tua immagine di riferimento sia ben inquadrata per il movimento che descrivi. Una maggiore risoluzione di base aiuta la fedeltà facciale ma aumenta anche VRAM e tempo di decodifica.
MagiHuman_SM_ENCODER(#95)
Codifica il Video Prompt in condizionamento positivo e negativo per il campionatore. Metti la linea esatta parlata tra virgolette e nomina la lingua per migliorare la chiusura delle labbra e la tempistica. Usa il campo negativo per sopprimere artefatti come "sottotitoli," "statico," o "eco della stanza."
MagiHuman_SM_KSampler(#9)
Esegue la denoising daVinci-MagiHuman per co-generare latenti video e discorso. Il seed controlla la riproducibilità, mentre steps e la pianificazione interna scambiano velocità per dettaglio e stabilità del movimento. Per variazioni senza perdere identità, cambia seed o riformula leggermente la parte di performance del tuo prompt.
MagiHuman_EN_DECO_VIDEO(#5)
Decodifica latenti video con il Wan 2.2 VAE in fotogrammi RGB per export o upscaling. Usa questo percorso per il render più veloce end-to-end; clip lunghi o risoluzioni più alte aumenteranno linearmente il tempo di decodifica.
MagiHuman_DECO_AUDIO(#6)
Decodifica latenti audio in forma d'onda e li invia attraverso la normalizzazione della sonorità per una riproduzione uniforme. Se successivamente passi a una generazione guidata da audio, instrada il tuo audio esterno nel costruttore latente e mantieni questo percorso di decodifica per il muxing finale.
RTXVideoSuperResolution(#93)
Upscaler post-opzionale che affina i bordi e riduce il ringing. Usa una forza moderata per migliorare la chiarezza senza introdurre sfarfallii temporali.
Extra opzionali#
- Schema di prompting per una sincronizzazione labiale affidabile: includi un tag di altoparlante e lingua più una linea tra virgolette, ad esempio Dialogo: <Presentatore, Inglese>: "Benvenuti allo spettacolo." Aggiungi una breve nota sulla consegna, dimensione dell'inquadratura e stabilità della camera.
- Mantieni il ritratto di riferimento come un mezzo primo piano con la testa completamente all'interno del quadro. Ritagli stretti lasciano poco spazio per le dinamiche della mascella e delle guance.
- Se hai bisogno di una tempistica più rigorosa, riduci o estendi il tuo script per adattarlo alla Durata scelta. Frasi molto lunghe in clip molto brevi possono forzare un'articolazione innaturale.
- Questo template funziona in modalità solo prompt. Per test guidati da audio, collega un file audio esterno all'ingresso audio su
MagiHuman_LATENTS(#13) e regola il tuo Video Prompt per descrivere l'espressione piuttosto che il contenuto parlato.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo vivamente daVinci-MagiHuman per il daVinci-MagiHuman Workflow Source per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- daVinci-MagiHuman/Workflow Source
- Docs / Release Notes: daVinci-MagiHuman Workflow Source
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.

