
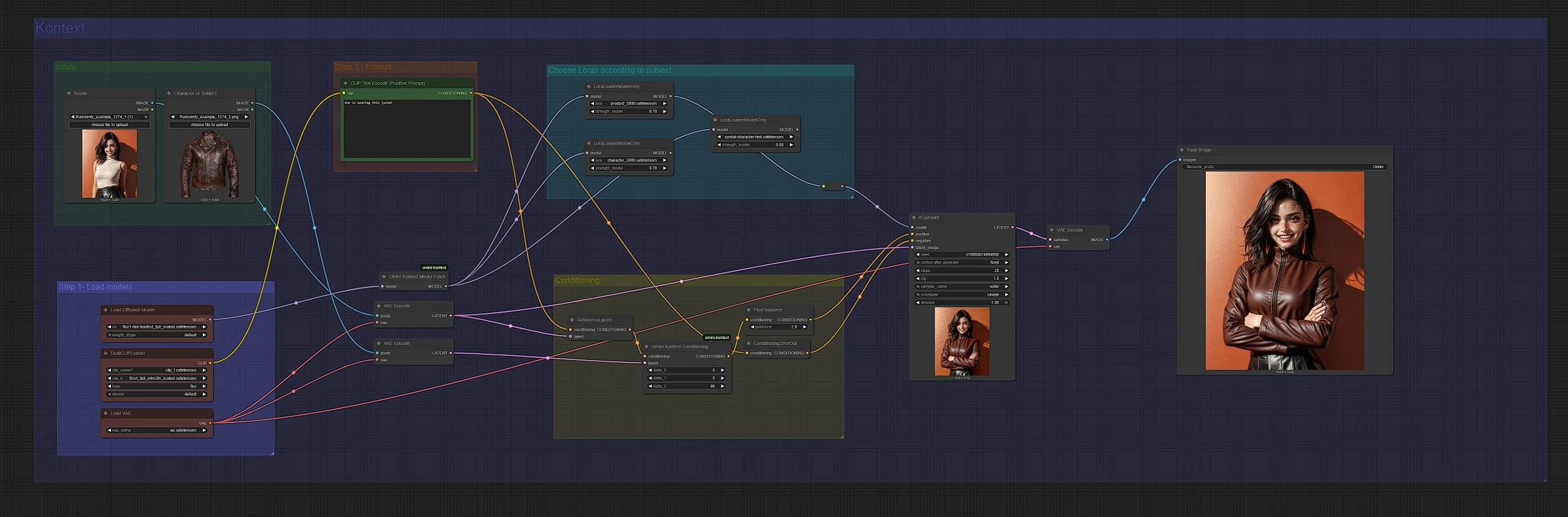





Workflow di composizione delle immagini Omni Kontext per ComfyUI#
Questo workflow ti permette di inserire un soggetto in una nuova scena con forte identità e preservazione del contesto usando Omni Kontext. Combina patch del modello Flux Omni Kontext con un condizionamento guidato da riferimenti in modo che un personaggio o prodotto fornito si integri naturalmente in uno sfondo target rispettando il tuo prompt. Sono inclusi due percorsi paralleli: un percorso Flux standard per la massima fedeltà e un percorso Nunchaku per un campionamento più veloce e adatto alla memoria con pesi quantizzati.
I creatori che desiderano asset di marca coerenti, sostituzioni di prodotti o posizionamenti di personaggi troveranno questo particolarmente utile. Fornisci un'immagine del soggetto pulita, un'immagine di scena e un breve prompt, e il grafico gestisce l'estrazione del contesto, la guida, lo stile LoRA e la decodifica per produrre un composito coerente.
Modelli chiave nel workflow Comfyui Omni Kontext#
- FLUX.1 Dev – Il backbone del trasformatore di diffusione usato per la generazione. Offre una forte aderenza ai prompt e un comportamento moderno del sampler adatto per la composizione consapevole del contesto. Model card
- Flux text encoders (CLIP-L and T5-XXL) – Encoder abbinati che tokenizzano e integrano il tuo testo in condizionamenti adatti per FLUX. Il workflow carica le varianti
clip_l.safetensorset5xxlottimizzate per Flux. Encoders - Omni Kontext nodes – Nodi personalizzati che patchano il modello e il condizionamento per iniettare il contesto dal tuo soggetto latente nel flusso di guida finale. Repository
- Nunchaku Flux DiT – Loader opzionale che supporta i pesi FLUX quantizzati FP16/BF16 e INT4 per velocità e minore VRAM mantenendo la qualità competitiva. Repository
- Lumina VAE – Un robusto VAE usato per codificare le immagini del soggetto e della scena e decodificare i risultati finali. Il workflow fa riferimento ad
ae.safetensorsda Lumina Image 2.0 riconfezionato. VAE
Come usare il workflow Comfyui Omni Kontext#
Il grafico ha due corsie speculari: la corsia superiore è il percorso standard Flux Omni Kontext, e la corsia inferiore è il percorso Nunchaku. Entrambi accettano un'immagine del soggetto e un'immagine di scena, costruiscono un condizionamento consapevole del contesto e campionano con Flux per produrre il composito.
Input#
Fornisci due immagini: una foto del soggetto pulita e una scena target. Il soggetto dovrebbe essere ben illuminato, centrato e non ostruito per massimizzare il trasferimento dell'identità. La scena dovrebbe corrispondere approssimativamente al tuo angolo di ripresa e all'illuminazione previsti. Caricale nei nodi etichettati "Character or Subject" e "Scene", quindi mantienili coerenti attraverso le esecuzioni mentre iteri sui prompt.
Carica modelli#
La corsia standard carica Flux con UNETLoader (#37) e applica la patch del modello Omni Kontext con OminiKontextModelPatch (#194). La corsia Nunchaku carica un modello Flux quantizzato con NunchakuFluxDiTLoader (#217) e applica NunchakuOminiKontextPatch (#216). Entrambe le corsie condividono gli stessi encoder di testo tramite DualCLIPLoader (#38) e lo stesso VAE tramite VAELoader (#39 o #204). Se intendi usare stili LoRA o identità, tienili collegati in questa sezione in modo che influenzino i pesi del modello prima del campionamento.
Prompt#
Scrivi prompt concisi che dicano al sistema cosa fare con il soggetto. Nella corsia superiore, CLIP Text Encode (Positive Prompt) (#6) guida l'inserimento o lo styling, e nella corsia inferiore CLIP Text Encode (Positive Prompt) (#210) svolge lo stesso ruolo. Prompt come "aggiungi il personaggio all'immagine" o "lei indossa questa giacca" funzionano bene. Evita descrizioni troppo lunghe; mantieniti sugli elementi essenziali che vuoi cambiare o mantenere.
Condizionamento#
Ogni corsia codifica il soggetto e la scena in latenti con VAEEncode, quindi fonde quei latenti con il tuo testo tramite ReferenceLatent e OminiKontextConditioning (#193 nella corsia superiore, #215 nella corsia inferiore). Questo è il passo Omni Kontext che inietta identità e segnali spaziali significativi dal riferimento nel flusso di condizionamento. Dopo di ciò, FluxGuidance (#35 superiore, #207 inferiore) imposta quanto strettamente il modello segue il condizionamento del composito. I prompt negativi sono semplificati con ConditioningZeroOut (#135, #202) in modo che tu possa concentrarti su ciò che vuoi piuttosto che su cosa evitare.
Scegli Loras in base al soggetto#
Se il tuo soggetto beneficia di un LoRA, collegalo prima del campionamento. La corsia standard utilizza LoraLoaderModelOnly (#201 e compagni) e la corsia Nunchaku utilizza NunchakuFluxLoraLoader (#219, #220, #221). Usa LoRA del soggetto per la coerenza dell'identità o dell'outfit e LoRA di stile per la direzione artistica. Mantieni la forza moderata per preservare il realismo della scena pur imponendo i tratti del soggetto.
Nunchaku#
Rivolgiti al gruppo Nunchaku quando vuoi iterazioni più veloci o hai VRAM limitata. Il NunchakuFluxDiTLoader (#217) supporta impostazioni INT4 che riducono notevolmente la memoria mantenendo il comportamento "Flux Omni Kontext" tramite NunchakuOminiKontextPatch (#216). Puoi comunque usare gli stessi prompt, input e LoRA, quindi campionare con KSampler (#213) e decodificare con VAEDecode (#208) per salvare i risultati.
Nodi chiave nel workflow Comfyui Omni Kontext#
OminiKontextModelPatch (#194)#
Applica le modifiche del modello Omni Kontext al backbone Flux in modo che il contesto di riferimento sia rispettato durante il campionamento. Lascialo abilitato ogni volta che vuoi che l'identità del soggetto e i segnali spaziali si trasferiscano nella generazione. Abbina con una forza LoRA moderata quando usi LoRA di personaggi o prodotti in modo che la patch e LoRA non competano.
OminiKontextConditioning (#193, #215)#
Unisce il tuo condizionamento di testo con i latenti di riferimento del soggetto e della scena. Se l'identità si allontana, aumenta l'enfasi sul riferimento del soggetto; se la scena viene sovrascritta, diminuiscila leggermente. Questo nodo è il cuore della composizione Omni Kontext e generalmente richiede solo piccoli aggiustamenti una volta che i tuoi input sono puliti.
FluxGuidance (#35, #207)#
Controlla quanto strettamente il modello segue il condizionamento del composito. Valori più alti spingono più vicino al prompt e al riferimento a costo della spontaneità; valori più bassi consentono maggiore varietà. Se vedi texture troppo elaborate o perdita di armonia con la scena, prova una piccola riduzione qui.
NunchakuFluxDiTLoader (#217)#
Carica una variante Flux DiT quantizzata per velocità e memoria inferiore. Scegli INT4 per rapide visualizzazioni e FP16 o BF16 per qualità finale. Combina con NunchakuFluxLoraLoader quando hai bisogno di supporto LoRA nella corsia Nunchaku.
Extra opzionali#
- Usa ritagli stretti del soggetto con sfondi puliti per migliorare la cattura dell'identità durante la codifica VAE.
- Mantieni i prompt brevi e concreti. Preferisci “aggiungi il prodotto al tavolo” rispetto a lunghe liste di stili.
- Se il soggetto sembra incollato, abbassa un po' la forza LoRA e riduci leggermente la guida per permettere alla scena di riaffermare illuminazione e prospettiva.
- Per cicli veloci, itera sulla corsia Nunchaku, quindi torna indietro alla corsia standard Flux Omni Kontext per i rendering finali.
- Salva alcuni semi intermedi che hanno funzionato bene in modo da poterli riutilizzare mentre affini la forza LoRA e la guida.
Ringraziamenti#
- Omni Kontext di Saquib764. Questo workflow adatta concetti e componenti dal progetto per abilitare la composizione Flux Omni Kontext in ComfyUI. Repository


