
InfiniteTalk: video ritratto sincronizzato sulle labbra da un'unica immagine in ComfyUI#
Questo workflow InfiniteTalk di ComfyUI crea video ritratto naturali e sincronizzati con il discorso a partire da un'unica immagine di riferimento più un clip audio. Combina la generazione di immagini in video di WanVideo 2.1 con il modello di testa parlante MultiTalk per produrre movimenti espressivi delle labbra e un'identità stabile. Se hai bisogno di brevi clip social, doppiaggi video o aggiornamenti avatar, InfiniteTalk trasforma una foto statica in un video parlante fluido in pochi minuti.
InfiniteTalk si basa sull'eccellente ricerca MultiTalk di MeiGen-AI. Per i dettagli e le attribuzioni, vedere il progetto open source: MeiGen-AI/MultiTalk.
Modelli chiave nel workflow Comfyui InfiniteTalk#
- MultiTalk (GGUF, variante InfiniteTalk): Guida il movimento facciale consapevole dei fonemi dall'audio in modo che i movimenti della bocca e della mascella seguano naturalmente il discorso. Riferimento: Kijai/WanVideo_comfy_GGUF › InfiniteTalk e idea a monte: MeiGen-AI/MultiTalk.
- WanVideo 2.1 I2V 14B (GGUF): Il generatore di immagini in video principale che preserva l'identità, l'illuminazione e la posa mentre anima i fotogrammi. Pesi consigliati: city96/Wan2.1-I2V-14B-480P-gguf.
- Wan 2.1 VAE (bf16): Decodifica i fotogrammi latenti in RGB con minimo spostamento di colore; fornito nei pacchetti WanVideo sopra.
- UMT5-XXL text encoder: Interpreta i tuoi prompt positivi e negativi per influenzare lo stile, la scena e il contesto del movimento. Famiglia di modelli: google/umt5-xxl.
- CLIP Vision: Estrae gli embedding visivi dalla tua immagine di riferimento per bloccare l'identità e l'aspetto generale.
- Wav2Vec2 (Tencent GameMate): Converte il discorso grezzo in caratteristiche audio robuste per gli embedding di MultiTalk, migliorando sincronizzazione e prosodia: TencentGameMate/chinese-wav2vec2-base.
Suggerimento: questo grafico InfiniteTalk è costruito per GGUF. Mantieni i pesi InfiniteTalk MultiTalk e la struttura WanVideo in GGUF per evitare incompatibilità. Sono disponibili anche build opzionali fp8/fp16: Kijai/WanVideo_comfy_fp8_scaled e Kijai/WanVideo_comfy.
Come usare il workflow Comfyui InfiniteTalk#
Il workflow funziona da sinistra a destra. Fornisci tre elementi: un'immagine di ritratto pulita, un file audio di discorso e un breve prompt per indirizzare lo stile. Il grafico quindi estrae indizi testuali, visivi e audio, li fonde in latenti video consapevoli del movimento e rende un MP4 sincronizzato.
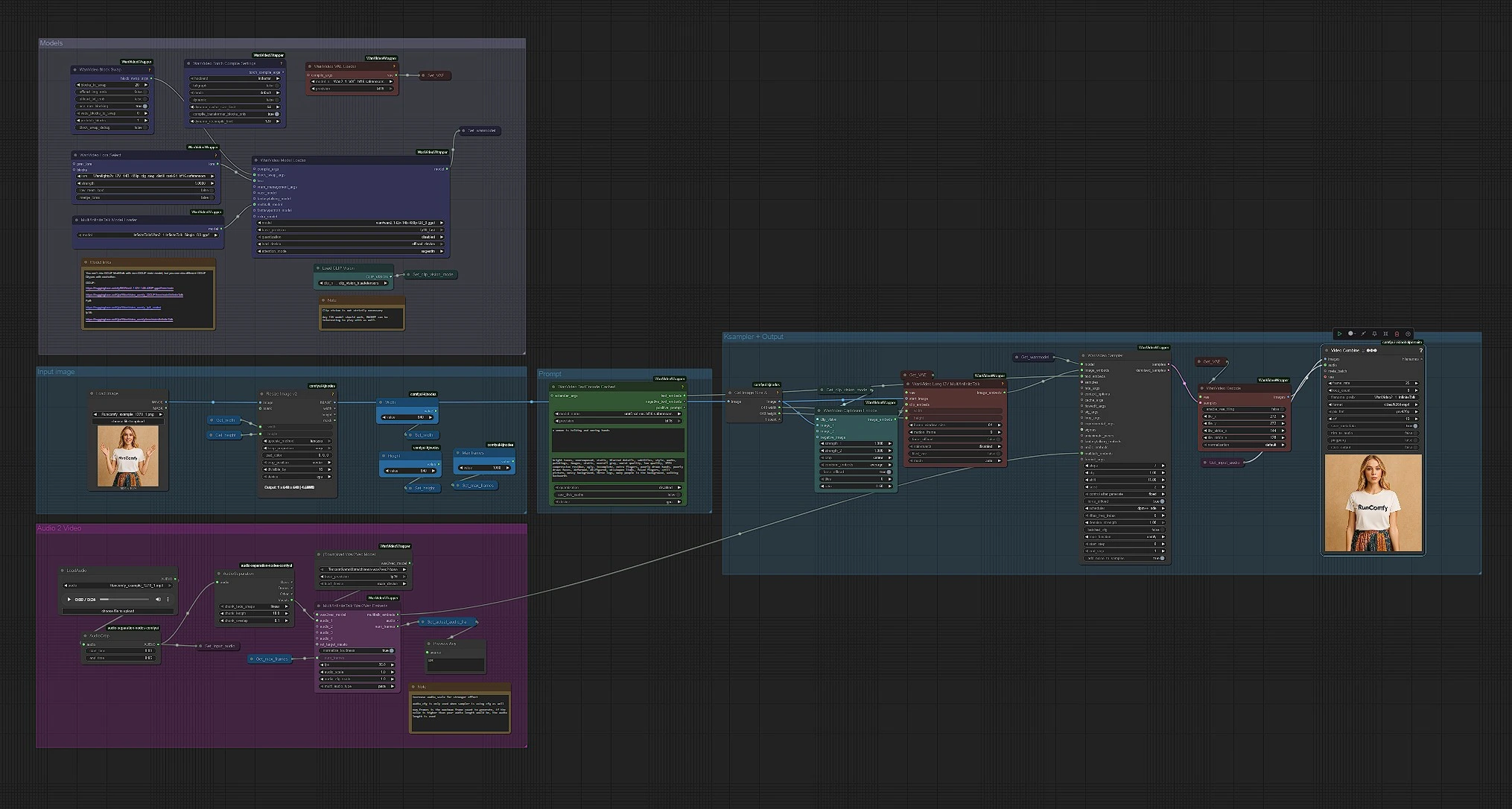
Modelli#
Questo gruppo carica WanVideo, VAE, MultiTalk, CLIP Vision e il text encoder. WanVideoModelLoader (#122) seleziona la struttura Wan 2.1 I2V 14B GGUF, mentre WanVideoVAELoader (#129) prepara il VAE corrispondente. MultiTalkModelLoader (#120) carica la variante InfiniteTalk che alimenta il movimento guidato dal discorso. Puoi opzionalmente collegare un Wan LoRA in WanVideoLoraSelect (#13) per influenzare aspetto e movimento. Lascia tutto intatto per una prima esecuzione veloce; sono pre-cablati per una pipeline 480p che è compatibile con la maggior parte delle GPU.
Prompt#
WanVideoTextEncodeCached (#241) prende i tuoi prompt positivi e negativi e li codifica con UMT5. Usa il prompt positivo per descrivere il soggetto e il tono della scena, non l'identità; l'identità proviene dalla foto di riferimento. Mantieni il prompt negativo concentrato sugli artefatti che vuoi evitare (sfocature, arti extra, sfondi grigi). I prompt in InfiniteTalk modellano principalmente l'illuminazione e l'energia del movimento mentre il volto rimane coerente.
Immagine di input#
CLIPVisionLoader (#238) e WanVideoClipVisionEncode (#237) incorporano il tuo ritratto. Usa una foto nitida, frontale e a mezzo busto con luce uniforme. Se necessario, ritaglia delicatamente in modo che il volto abbia spazio per muoversi; un ritaglio pesante può destabilizzare il movimento. Gli embedding dell'immagine vengono trasmessi in avanti per preservare identità e dettagli degli abiti mentre il video si anima.
Audio a MultiTalk#
Carica il tuo discorso in LoadAudio (#125); taglialo con AudioCrop (#159) per anteprime rapide. DownloadAndLoadWav2VecModel (#137) scarica Wav2Vec2 e MultiTalkWav2VecEmbeds (#194) trasforma il clip in caratteristiche di movimento consapevoli dei fonemi. Brevi tagli da 4-8 secondi sono ottimi per iterazioni; puoi eseguire riprese più lunghe una volta che ti piace l'aspetto. Tracce vocali pulite e asciutte funzionano meglio; musica di sottofondo forte può confondere il sincronismo delle labbra.
Da immagine a video, campionamento e output#
WanVideoImageToVideoMultiTalk (#192) fonde la tua immagine, gli embedding CLIP Vision e MultiTalk in embedding di immagine per fotogramma dimensionati dai costanti Width e Height. WanVideoSampler (#128) genera i fotogrammi latenti usando il modello WanVideo da Get_wanmodel e i tuoi embedding testuali. WanVideoDecode (#130) converte i latenti in fotogrammi RGB. Infine, VHS_VideoCombine (#131) mescola fotogrammi e audio in un MP4 a 25 fps con un'impostazione di qualità bilanciata, producendo il clip InfiniteTalk finale.
Nodi chiave nel workflow Comfyui InfiniteTalk#
WanVideoImageToVideoMultiTalk (#192)#
Questo nodo è il cuore di InfiniteTalk: condiziona l'animazione della testa parlante fondendo l'immagine iniziale, le caratteristiche CLIP Vision e la guida MultiTalk alla tua risoluzione target. Regola width e height per impostare l'aspetto; 832×480 è un buon default per velocità e stabilità. Usalo come punto principale per allineare identità e movimento prima del campionamento.
MultiTalkWav2VecEmbeds (#194)#
Converte le caratteristiche Wav2Vec2 in embedding di movimento MultiTalk. Se il movimento delle labbra è troppo sottile, aumenta la sua influenza (scalatura audio) in questa fase; se è troppo esagerato, riduci l'influenza. Assicurati che l'audio sia dominante nel discorso per un'accurata tempistica dei fonemi.
WanVideoSampler (#128)#
Genera i latenti video dati immagine, testo e embedding MultiTalk. Per le prime esecuzioni, mantieni il pianificatore e i passaggi predefiniti. Se vedi sfarfallio, aumentare i passaggi totali o abilitare CFG può aiutare; se il movimento sembra troppo rigido, riduci CFG o la forza del campionatore.
WanVideoTextEncodeCached (#241)#
Codifica i prompt positivi e negativi con UMT5-XXL. Usa un linguaggio conciso e concreto come "luce da studio, pelle morbida, colore naturale" e mantieni i prompt negativi concentrati. Ricorda che i prompt affinano inquadratura e stile, mentre la sincronizzazione delle labbra proviene da MultiTalk.
Extra opzionali#
- Mantieni MultiTalk e WanVideo nella stessa famiglia di distribuzione (tutti GGUF o tutti non-GGUF) per evitare incompatibilità.
- Itera con un ritaglio audio da 5-8 secondi e la dimensione predefinita 480p; esegui l'upscaling successivamente se necessario.
- Se l'identità vacilla, prova una foto sorgente più pulita o un LoRA più mite. LoRA forti possono sostituire la somiglianza.
- Registra il discorso in una stanza silenziosa e normalizza i livelli; InfiniteTalk traccia i fonemi meglio con voce chiara e asciutta.
Riconoscimenti#
Il workflow InfiniteTalk rappresenta un grande passo avanti nella generazione di video alimentati dall'AI combinando il sistema flessibile di nodi di ComfyUI con il modello AI MultiTalk. Questa implementazione è stata resa possibile grazie alla ricerca originale e al rilascio di MeiGen-AI, il cui progetto MultiTalk alimenta la sincronizzazione naturale del discorso di InfiniteTalk. Un ringraziamento speciale va anche al team del progetto InfiniteTalk per aver fornito il riferimento sorgente e alla comunità degli sviluppatori di ComfyUI per aver consentito un'integrazione fluida del workflow.
Inoltre, credito va a Kijai, che ha implementato InfiniteTalk nel nodo Wan Video Sampler, rendendo più facile per i creatori produrre ritratti parlanti e cantanti di alta qualità direttamente all'interno di ComfyUI. Il link alla risorsa originale per InfiniteTalk è disponibile qui: InfiniteTalk Example Workflow.
Insieme, questi contributi rendono possibile per i creatori trasformare semplici ritratti in avatar parlanti continui e realistici, sbloccando nuove opportunità per narrazioni, doppiaggi e contenuti di performance guidati dall'AI.