
Flusso di lavoro per la generazione e modifica di video multimodali Bernini#
Questo flusso di lavoro per la generazione e modifica di video multimodali Bernini è una pipeline pronta all'uso di ComfyUI per la modifica video consapevole dell'identità e trasformazione da video a video guidata da riferimenti. Combina un video sorgente, una o più immagini di riferimento e un prompt focalizzato per preservare il movimento e il comportamento della fotocamera mentre sostituisce o cambia stile al soggetto. Il flusso di lavoro abbina i backbones di diffusione alta e bassa di Bernini con la codifica testuale in stile Wan, un VAE compatibile con Bernini, LightX2V LoRAs e un conditioning specifico di Bernini affinché i risultati appaiano consistenti da un fotogramma all'altro.
Progettato per creatori e ricercatori che valutano Bernini all'interno di ComfyUI, il flusso di lavoro eccelle nella sostituzione di personaggi, modifiche che preservano il movimento, mimetismo e generazione di brevi video consapevoli della fotocamera. Esporta un MP4 modificato più un confronto opzionale affiancato, rendendo facile rivedere l'impatto del tuo prompt e set di riferimenti. In tutto questo README il termine flusso di lavoro per la generazione e modifica di video multimodali Bernini si riferisce a questo grafico end-to-end.
Modelli chiave nel flusso di lavoro per la generazione e modifica di video multimodali Bernini in ComfyUI#
- Famiglia di modelli di diffusione Bernini di ByteDance (backbones ALTI e BASSI). Fornisce le reti di denoising core utilizzate in un programma a due fasi: il modello ALTO gestisce la struttura sotto rumore più forte mentre il modello BASSO affina i dettagli e la consistenza temporale. Vedi l'hub dei modelli per i pesi di riferimento e le note: ByteDance/Bernini.
- Codificatore di testo Wan (umT5-XXL). Un codificatore T5 in stile Wan che trasforma le tue istruzioni in conditioning per Bernini; esposto in ComfyUI tramite un'interfaccia compatibile con CLIP. Gli asset adatti per ComfyUI sono disponibili qui: Kijai/WanVideo_comfy_fp8_scaled.
- Wan 2.1 VAE. Esegue il decoding latente per trasformare i latenti denoised in fotogrammi video con fedeltà cromatica che corrisponde all'addestramento Wan/Bernini. Un VAE pronto per ComfyUI è incluso nello stesso pacchetto di asset: Kijai/WanVideo_comfy_fp8_scaled.
- Coppia LightX2V LoRA (high_noise e low_noise). Adattatori leggeri che indirizzano Bernini verso un movimento stabile preservando l'identità di riferimento attraverso i fotogrammi. I pesi FP8 LoRA forniti si allineano con il campionamento a due fasi utilizzato in questo flusso di lavoro e sono confezionati con gli asset di Bernini sopra: Kijai/WanVideo_comfy_fp8_scaled.
Come utilizzare il flusso di lavoro per la generazione e modifica di video multimodali Bernini in ComfyUI#
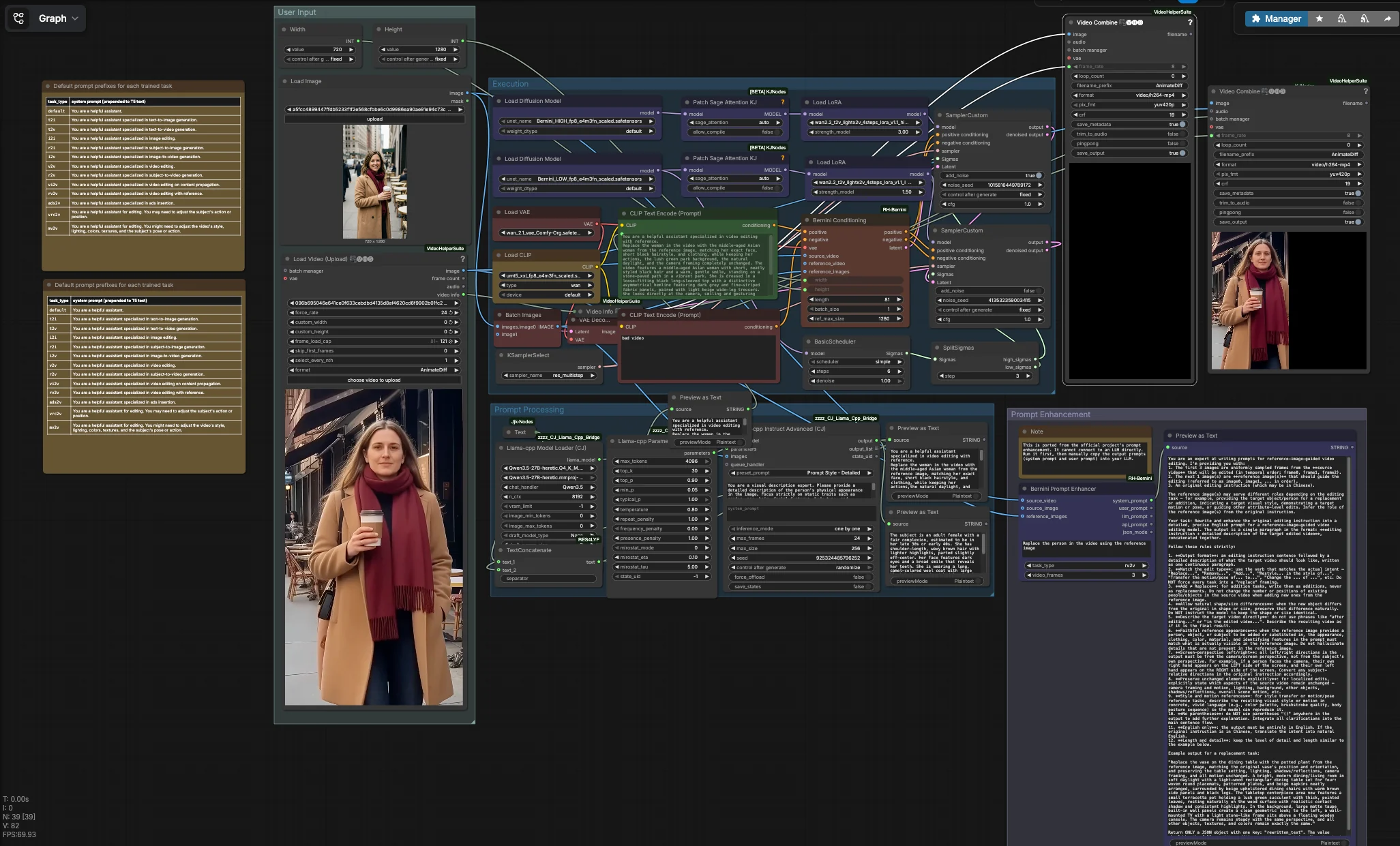
Questo flusso di lavoro ha quattro gruppi coordinati. Fornisci un video sorgente e una o più immagini di riferimento, forma il testo delle istruzioni, quindi il gruppo di Esecuzione esegue un passaggio Bernini a due fasi che decodifica in fotogrammi e assembla il tuo video di output. Un'utilità parallela può generare prompt di sistema e utente scaffolding per la scrittura assistita da LLM.
Input Utente#
Carica il tuo video sorgente con VHS_LoadVideo (#90). Il nodo legge il clip ed espone i suoi metadati in modo che il rendering finale erediti il frame rate originale, il che aiuta a preservare la sensazione di movimento. Aggiungi uno o più riferimenti di identità con LoadImage (#31); i volti frontali e ben illuminati con espressioni neutre funzionano meglio. Imposta la dimensione target utilizzando Width (#109) e Height (#110), idealmente abbinando il rapporto d'aspetto della sorgente per evitare allungamenti. Un prompt negativo predefinito è codificato da CLIPTextEncode (#4) per sopprimere gli artefatti comuni nei video di bassa qualità; puoi affinarlo se necessario.
Elaborazione del Prompt#
Se desideri che l'istruzione corrisponda esattamente all'identità di riferimento, il grafico può riassumere i tratti statici dalle tue immagini di riferimento utilizzando un LLM locale. llama_cpp_model_loader (#93) e llama_cpp_instruct_adv (#92) analizzano le immagini raggruppate da BatchImagesNode (#74) e restituiscono una descrizione concisa degli attributi immutabili come capelli, età e abbigliamento. Quella descrizione è concatenata con la tua direttiva di compito da JjkText (#104) tramite TextConcatenate (#102). Il risultato fluisce in CLIPTextEncode (#3), che diventa il conditioning positivo per Bernini. I nodi di anteprima mostrano il testo composto in modo da poter iterare rapidamente prima di eseguire le fasi pesanti.
Potenziamento del Prompt#
BerniniPromptEnhancer (#60) genera prompt “di sistema” e “utente” strutturati su misura per il tipo di compito selezionato e gli input. Eseguilo per ottenere istruzioni più forti che puoi incollare nel tuo LLM per un'espansione più ricca del prompt; per progettazione non è cablato nel grafico principale. Questa utilità proviene dal pacchetto di nodi personalizzati Bernini: ComfyUI-RH-Bernini. Trattalo come uno strumento di pre-scrittura per standardizzare il linguaggio che funziona bene con il conditioning di Bernini.
Esecuzione#
Il percorso principale inizia caricando gli UNets HIGH e LOW di Bernini e collegando LightX2V LoRAs per ciascuna fase. BerniniConditioning (#34) fonde le tue codifiche positive e negative, VAE, fotogrammi video sorgente e immagini di riferimento per costruire un conditioning specifico di Bernini e un latente iniziale allineato alla tua risoluzione e conteggio dei fotogrammi. Un BasicScheduler (#18) crea il programma di denoising, quindi SplitSigmas (#17) lo divide in intervalli HIGH e LOW. Il campionatore HIGH SamplerCustom (#19) stabilisce la struttura e l'identità sotto rumore più forte, passando il suo latente al campionatore LOW SamplerCustom (#15) per dettagli e rifinitura temporale. KSamplerSelect (#27) sceglie l'algoritmo del campionatore, VAEDecode (#16) trasforma il latente finale in fotogrammi, e VHS_VideoCombine (#87) rende un MP4 che eredita il frame rate della sorgente. In parallelo, ImageConcanate (#97) e un secondo VHS_VideoCombine (#96) producono un confronto affiancato per controlli rapidi di qualità. I/O video e assemblaggio sono forniti dalla Video Helper Suite: ComfyUI-VideoHelperSuite.
Nodi chiave nel flusso di lavoro per la generazione e modifica di video multimodali Bernini in ComfyUI#
BerniniConditioning (#34) Costruisce un conditioning nativo di Bernini combinando le tue codifiche testuali, VAE, video sorgente e immagini di riferimento. Prepara anche il volume latente iniziale e gestisce le dimensioni spaziali e temporali. Regola width e height per abbinare la risoluzione target e usa length per controllare il numero di fotogrammi generati. Se il soggetto di riferimento è piccolo nell'immagine, aumenta ref_max_size in modo che il modello percepisca meglio i dettagli dell'identità. Questo nodo fa parte del pacchetto personalizzato Bernini: ComfyUI-RH-Bernini.
LoraLoaderModelOnly (#11) Applica il LightX2V high_noise LoRA al backbone HIGH. Aumentare la sua strength_model aumenta l'aderenza al riferimento nella fase strutturale, utile quando la silhouette del soggetto o le caratteristiche grossolane non corrispondono al video sorgente. Abbassalo se la modifica diventa troppo rigida o sopprime il movimento naturale. Usa insieme al LoRA di fase LOW per bilanciare fedeltà e fluidità.
LoraLoaderModelOnly (#29) Applica il LightX2V low_noise LoRA al backbone LOW. Questo LoRA affina texture come capelli, pelle e abbigliamento mantenendo il movimento impostato dalla fase HIGH. Se i dettagli dell'identità si spostano tra i fotogrammi, aumenta leggermente la forza; se le texture si affinano troppo o sembrano sovra-adattate, riducila. Insieme al LoRA di fase HIGH forma una coppia complementare.
SplitSigmas (#17) Divide il programma di denoising in intervalli HIGH e LOW. Spostare la divisione prima produce modifiche più lievi che mantengono di più il video originale, mentre spostarla più tardi concede alla fase HIGH più influenza per sostituzioni più forti. Regola la divisione quando cambi i prompt o le forze LoRA in modo che entrambe le fasi rimangano bilanciate. Questo controllo è particolarmente utile per modifiche che preservano il movimento bloccato dalla fotocamera.
KSamplerSelect (#27) Seleziona l'algoritmo del campionatore utilizzato da entrambe le fasi di denoising. Alcuni campionatori favoriscono la stabilità e la fluidità temporale mentre altri enfatizzano i dettagli o la velocità. Se vedi sfarfallio, prova un campionatore noto per la consistenza; se hai bisogno di ulteriore nitidezza, prova un algoritmo che inietta più varianza. Mantieni la stessa scelta per entrambe le fasi per mantenere un comportamento prevedibile.
VHS_VideoCombine (#87) Codifica i fotogrammi decodificati in un MP4 finale ereditando il frame rate riportato da VHS_VideoInfo in modo che la velocità di riproduzione corrisponda al clip sorgente. Usa i controlli del nome file per organizzare le esecuzioni e abilita il salvataggio dei metadati se intendi verificare le impostazioni. Una seconda istanza (#96) produce un rendering affiancato per un rapido confronto visivo. Fornito da ComfyUI-VideoHelperSuite.
Extra opzionali#
- Per compiti critici per l'identità, fornisci due o tre immagini di riferimento di alta qualità che mostrano capelli, illuminazione ed espressioni coerenti. Usa l'input batch per alimentarli insieme.
- Mantieni il rapporto d'aspetto target vicino al video sorgente. Grandi disallineamenti possono allungare i volti e destabilizzare il movimento.
- Se lo sfondo o la fotocamera si spostano, rafforza il linguaggio nelle tue istruzioni che blocca la posizione della fotocamera e della scena, e rinforza con un prompt negativo conciso.
- Usa l'export affiancato quando regoli le forze LoRA o la divisione sigma. Accorcia il tempo di iterazione rendendo ovvie le differenze.
- Per prove più veloci, limita il numero di fotogrammi che carichi, quindi aumenta una volta che sei soddisfatto della corrispondenza dell'identità e della qualità del movimento.
Questo flusso di lavoro per la generazione e modifica di video multimodali Bernini è progettato per essere modificato in sicurezza: inizia con i valori predefiniti, itera sulle istruzioni e sui riferimenti, quindi affina le forze LoRA e la divisione sigma per il tuo soggetto e scena.
Ringraziamenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine ByteDance per Bernini, RH-RunningHub per ComfyUI-RH-Bernini, e Kosinkadink per ComfyUI-VideoHelperSuite per i loro contributi e manutenzione. Per dettagli autorevoli, fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- RunningHub/Bernini Multimodal Video Generation and Editing (ComfyUI Workflow)
- Documenti / Note di Rilascio: RunningHub workflow reference
- RunComfy/Cloud Save workflow
- Documenti / Note di Rilascio: RunComfy Cloud Save workflow
- ByteDance/Bernini-R
- GitHub: bytedance/Bernini
- Hugging Face: ByteDance/Bernini-R
- arXiv: arXiv:2605.22344
- Documenti / Note di Rilascio: Fonte del modello ByteDance Bernini
- Kijai/WanVideo_comfy_fp8_scaled (Bernini assets)
- Hugging Face: Kijai/WanVideo_comfy_fp8_scaled
- Documenti / Note di Rilascio: Asset del modello Kijai Bernini ComfyUI fp8
- RH-RunningHub/ComfyUI-RH-Bernini
- GitHub: RH-RunningHub/ComfyUI-RH-Bernini
- Documenti / Note di Rilascio: Nodi personalizzati RunComfy Bernini
- Kosinkadink/ComfyUI-VideoHelperSuite
- GitHub: Kosinkadink/ComfyUI-VideoHelperSuite
- Documenti / Note di Rilascio: Suite di aiuto video ComfyUI
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.
