
ACE-Step 1.5XL Turbo Text-to-Music ComfyUI Workflow#
Trasforma prompt compatti in musica MP3 raffinata con questo workflow comfyui incentrato su velocità e ripetibilità. Abbina il generatore ACE-Step 1.5XL Turbo al suo VAE ufficiale e ai doppi encoder di testo Qwen, quindi esporta direttamente in MP3 per una facile anteprima e riutilizzo. Produttori, sound designer e artisti di prompt possono iterare rapidamente mantenendo i risultati coerenti tra le esecuzioni.
Modelli chiave in questo workflow comfyui#
- ACE-Step 1.5XL Turbo (bf16). Il modello di diffusione principale che sintetizza musica dal condizionamento del testo, ottimizzato per una rapida denoising e latenti audio di alta qualità. Model file
- ACE-Step 1.5 VAE. Il decodificatore che trasforma i latenti audio in un'onda finale mantenendo il timbro e le dinamiche attese dalla famiglia ACE-Step. Model file
- Qwen 0.6B ACE 1.5 text encoder. Encoder leggero che converte il tuo prompt descrittivo in vettori di condizionamento utilizzati dal generatore. Model file
- Qwen 4B ACE 1.5 text encoder. Encoder compagno più grande che arricchisce la semantica, i suggerimenti di stile, gli strumenti e gli accenni vocali per rendering più fedeli. Model file
Come utilizzare questo workflow comfyui#
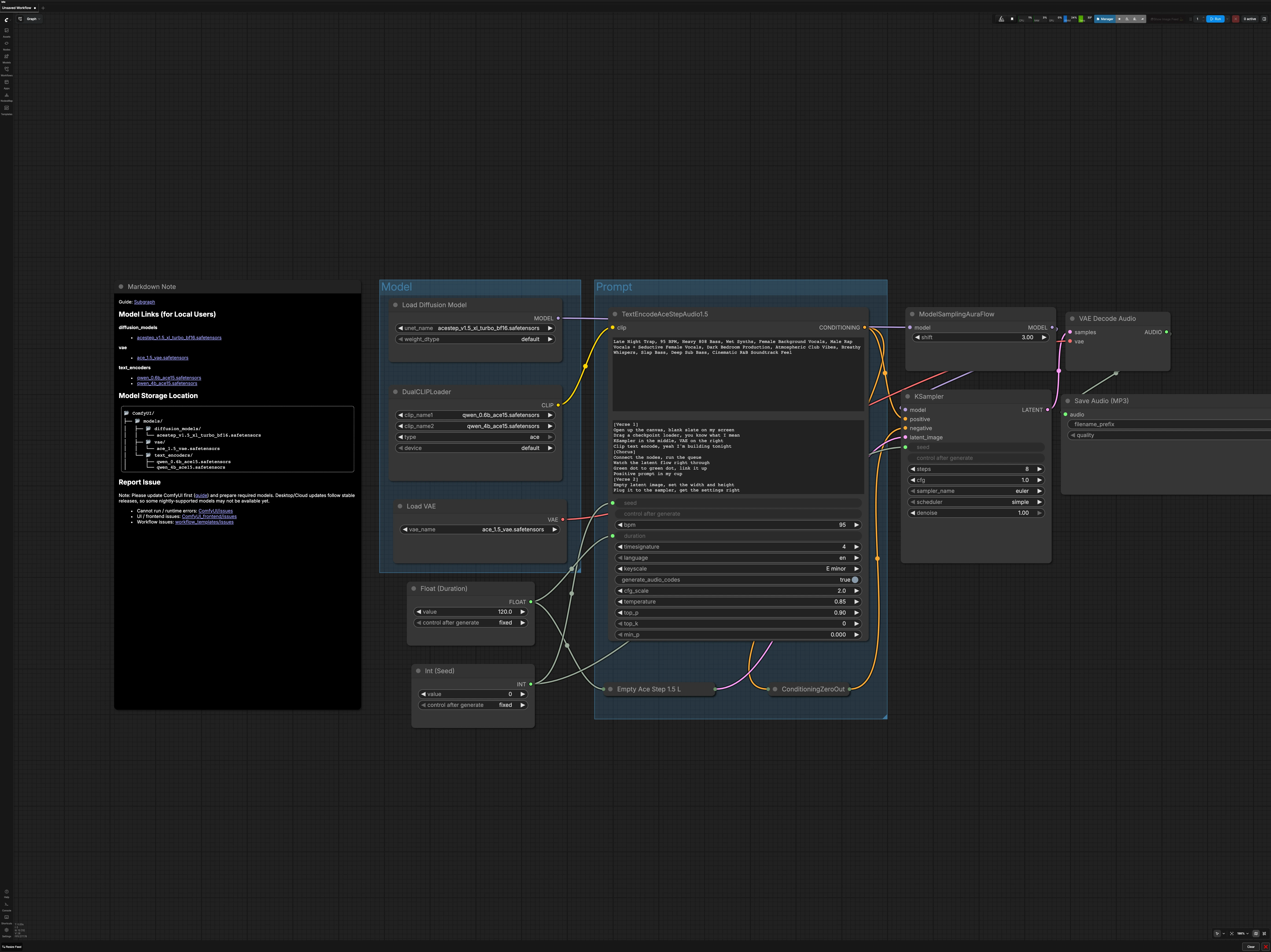
Il grafico è organizzato in due gruppi principali più controlli globali. Carichi lo stack del modello ACE-Step, descrivi la musica che desideri, imposti la durata del brano e il seed, quindi campioni, decodifichi ed esporti in MP3.
Gruppo modello#
Questa sezione inizializza lo stack del modello che il generatore si aspetta. UNETLoader (#104) carica ACE-Step 1.5XL Turbo, e VAELoader (#106) porta il corrispondente ACE-Step 1.5 VAE per mantenere la decodifica fedele. DualCLIPLoader (#105) abbina gli encoder di testo Qwen 0.6B e 4B per preparare gli embedding dei prompt. Il UNet è instradato attraverso ModelSamplingAuraFlow (#78), che applica la configurazione del campionatore richiesta dal modello prima che inizi il denoising.
Gruppo prompt#
Scrivi una descrizione concisa di genere, umore, strumenti, voci, tempo e stile di produzione in TextEncodeAceStepAudio1.5 (#94). Se usi testi o note strutturali, fornisci questi nel secondo riquadro di testo in modo che gli encoder possano condizionare la frase e le dinamiche. Il condizionamento negativo è intenzionalmente disabilitato tramite ConditioningZeroOut (#47) per mantenere i risultati focalizzati e semplificare le prime iterazioni. Il nodo accetta anche la duration e il seed globali, assicurando che il condizionamento rimanga allineato con la lunghezza del brano e le impostazioni di riproducibilità.
Durata e seed#
Imposta la lunghezza del brano in secondi usando Float (Duration) (#99). Scegli un seed in Int (Seed) (#109) per rendere le esecuzioni riproducibili sia con l'encoder che con il campionatore. Mantenere lo stesso seed mentre si cambia solo il prompt è un modo affidabile per testare direzioni creative A/B. Per un'esplorazione ampia, varia il seed dopo che sei soddisfatto del prompt.
Configurazione audio latente#
EmptyAceStep1.5LatentAudio (#98) costruisce un audio latente vuoto che corrisponde alla durata scelta. Questo funge da tela che il campionatore riempirà durante il denoising. Durate più lunghe richiedono più calcolo, quindi considera di iniziare con durate più brevi per convalidare un prompt prima di espandere. Il workflow collega la durata a livello globale in modo che il tuo latente e il condizionamento rimangano sempre sincronizzati.
Denoising e campionamento#
KSampler (#3) esegue il processo di diffusione utilizzando il modello ACE-Step 1.5XL Turbo e il condizionamento del tuo prompt. Il percorso del campionatore passa attraverso ModelSamplingAuraFlow (#78) per abbinare le impostazioni dello scheduler attese dal modello per una convergenza stabile e veloce. Usa lo stesso seed per confrontare i cambiamenti nel testo o nello stile, e regola le impostazioni del campionatore solo quando il tuo prompt è a punto. Quando il campionatore termina, avrai un audio latente pronto per la decodifica.
Decodifica ed esportazione#
VAEDecodeAudio (#18) converte il latente in un'onda sonora con l'ACE-Step 1.5 VAE per preservare il timbro previsto. SaveAudioMP3 (#107) scrive un MP3 con un nome di file base e un tag di versione opzionale per mantenere le riprese organizzate. L'MP3 è ideale per una rapida revisione e condivisione, e puoi sempre ri-renderizzare o ri-esportare in un formato diverso in seguito. Il risultato appare nella tua posizione di output standard di ComfyUI.
Nodi chiave in questo workflow comfyui#
TextEncodeAceStepAudio1.5 (#94)#
Questo nodo traduce la tua descrizione musicale e i testi opzionali in condizionamenti per il generatore utilizzando gli encoder Qwen abbinati. Mantieni i prompt specifici riguardo a genere, strumentazione, presenza vocale, tempo, umore e carattere del mix. Assicurati che la duration del nodo corrisponda alla lunghezza globale del brano in modo che struttura e fraseggio siano allineati. Usa un seed fisso mentre iteri sul testo per capire come i termini influenzano l'arrangiamento e il timbro.
EmptyAceStep1.5LatentAudio (#98)#
Controlla la tela temporale che il modello riempirà. Aumentare la durata aumenta la memoria e il tempo di rendering, quindi itera su bozze più brevi prima di impegnarti in pezzi più lunghi. Mantieni deliberati i cambiamenti di durata perché possono alterare il tempo percepito e il ritmo della sezione anche con lo stesso prompt e seed.
KSampler (#3)#
Guida qualità, velocità e texture complessiva controllando come il rumore viene rimosso dal latente. Inizia con il percorso dello scheduler fornito e regola le impostazioni del campionatore solo dopo che il prompt sembra giusto. Per bozze rapide, riduci lo sforzo di campionamento; per una maggiore fedeltà, aumentalo gradualmente mantenendo costante il seed per rendere le differenze facili da ascoltare. Vedi il comportamento del campionatore principale nel repository ComfyUI per una guida generale. ComfyUI on GitHub
SaveAudioMP3 (#107)#
Gestisce l'esportazione e la denominazione dei file in modo da poter catalogare le riprese. Imposta un nome base chiaro e un tag di versione per tracciare le iterazioni. Se intendi masterizzare o modificare ulteriormente, mantieni il seed del progetto e il prompt nelle tue note in modo da poter ri-renderizzare con impostazioni di esportazione alternative quando necessario.
Extra opzionali#
- Scrivi i prompt come frasi brevi e ordinate: genere, umore, sensazione principale, tempo, strumenti, tipo di voce, stile di produzione.
- Mantieni i testi concisi e allineati alla durata scelta per evitare frasi affrettate verso la fine.
- Blocca il seed mentre affini il prompt, quindi varia il seed per esplorare arrangiamenti alternativi con lo stesso brief.
- Inizia con durate più brevi per convalidare la direzione, quindi espandi una volta che il suono principale funziona.
- Il condizionamento negativo è disabilitato per design; abilita e regola un vero prompt negativo solo se hai bisogno di escludere strettamente dopo l'esplorazione iniziale.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo calorosamente Comfy.org per il workflow Audio ACE Step 1.5 XL Turbo, e Comfy-Org per il modello di diffusione ACE-Step 1.5XL Turbo, ACE-Step 1.5 VAE, encoder di testo ACE-Step 1.5 0.6B e encoder di testo ACE-Step 1.5 4B per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Comfy.org/Audio ACE Step 1.5 XL Turbo workflow
- Docs / Note di Rilascio: Workflow page
- Comfy-Org/ACE-Step 1.5XL Turbo diffusion model
- Hugging Face: acestep_v1.5_xl_turbo_bf16.safetensors
- Comfy-Org/ACE-Step 1.5 VAE
- Hugging Face: ace_1.5_vae.safetensors
- Comfy-Org/ACE-Step 1.5 text encoder 0.6B
- Hugging Face: qwen_0.6b_ace15.safetensors
- Comfy-Org/ACE-Step 1.5 text encoder 4B
- Hugging Face: qwen_4b_ace15.safetensors
Nota: L'uso dei modelli, dei dataset e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.