
ACE-Step 1.5XL Base testo in musica: Workflow da prompt a canzone per ComfyUI#
Questo workflow trasforma descrizioni in linguaggio naturale in audio finito utilizzando la famiglia di diffusione ACE-Step 1.5XL Base. Abbina il modello base con il suo ACE Step VAE e doppi encoder di testo Qwen per mantenere i risultati saldamente nel campo musicale piuttosto che TTS o parlato. Se desideri musica AI guidata da prompt con struttura, tempi e strumentazione prevedibili, questa pipeline ACE-Step 1.5XL Base testo in musica è un setup focalizzato e minimale che ti porta dall'idea a MP3 rapidamente.
Progettato per produttori, sound designer e creatori, il grafico enfatizza la chiarezza: scegli i modelli, imposta una durata, scrivi un prompt musicale, quindi genera e salva. Il workflow ACE-Step 1.5XL Base testo in musica è abbastanza compatto per iterazioni rapide pur rimanendo espressivo per arrangiamenti dettagliati, chiavi e tempi.
Modelli chiave nel workflow Comfyui ACE-Step 1.5XL Base testo in musica#
- Modello di diffusione ACE-Step 1.5 XL Base (bf16). La spina dorsale generativa che denoisa latenti audio in frasi e texture musicali coerenti. Model file
- ACE Step 1.5 VAE. L'autoencoder variazionale abbinato che codifica/decodifica tra lo spazio latente e il dominio delle forme d'onda, preservando timbro e bilanci di mix. Model file
- Encoder di testo Qwen 4B ACE15. Un grande encoder di testo adattato per ACE che cattura ricche semantiche musicali, struttura e suggerimenti di arrangiamento dal prompt. Model file
- Encoder di testo Qwen 0.6B ACE15. Un encoder ACE adattato più leggero che dà priorità alla velocità e all'efficienza delle risorse mantenendo una forte comprensione del prompt. Model file
Come usare il workflow Comfyui ACE-Step 1.5XL Base testo in musica#
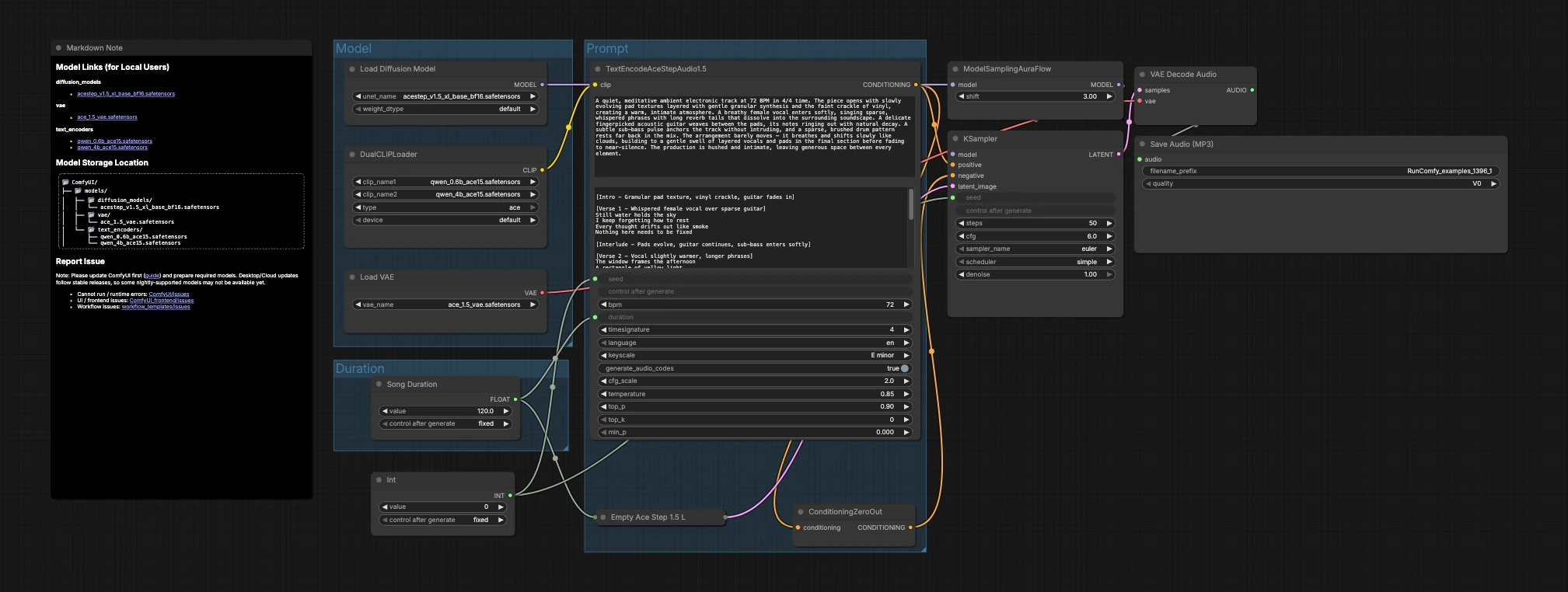
Il grafico è organizzato in tre gruppi che fluiscono verso la generazione e l'esportazione: Modello, Durata e Prompt. Carichi i modelli, scegli una lunghezza target, descrivi la musica, quindi il sampler crea latenti che il VAE decodifica in audio.
Modello#
Questo gruppo carica le risorse principali. UNETLoader (#104) seleziona il checkpoint di diffusione ACE-Step 1.5 XL Base, e VAELoader (#106) carica il VAE ACE Step 1.5 corrispondente in modo che la qualità di decodifica sia allineata con l'addestramento. DualCLIPLoader (#105) integra entrambi gli encoder Qwen ACE15; il workflow li utilizza congiuntamente in modo che i ricchi prompt di testo si traducano in un forte condizionamento musicale.
Durata#
Qui decidi quanto dovrebbe durare il pezzo. Song Duration (#99) imposta la lunghezza target in secondi e la trasmette avanti in modo che la tela latente e il condizionamento del testo concordino. PrimitiveInt (#109) fornisce un seed, permettendoti di bloccare risultati esatti per la riproducibilità o variarlo per esplorare alternative.
Prompt#
Qui il linguaggio diventa musica. Scrivi la tua descrizione in TextEncodeAceStepAudio1.5 (#94), includendo metadati musicali utili come tempo (BPM), metro, chiave, strumentazione, arrangiamento, presenza vocale e note di mix. Il nodo emette il condizionamento positivo; ConditioningZeroOut (#47) fornisce un percorso negativo neutro in modo che la generazione rimanga focalizzata sulla tua descrizione. EmptyAceStep1.5LatentAudio (#98) inizializza una timeline audio latente per la durata scelta. ModelSamplingAuraFlow (#78) adatta il modello base a un scheduler adatto per l'audio ACE-Step. KSampler (#3) combina modello, condizionamento, latente e seed per generare il latente musicale. VAEDecodeAudio (#18) converte il latente in forma d'onda e SaveAudioMP3 (#107) salva il risultato in un file MP3 pronto per essere condiviso.
Nodi chiave nel workflow Comfyui ACE-Step 1.5XL Base testo in musica#
TextEncodeAceStepAudio1.5 (#94)#
Trasforma il tuo prompt in un condizionamento che il modello di diffusione può seguire. Accetta dettagli musicali come tempo, firma del tempo, chiave, note di arrangiamento, strumentazione, lingua e intento vocale opzionale. Per risultati migliori, sii concreto su genere, feeling e posizionamento nel mix, e mantieni i suggerimenti strutturali concisi in modo che il modello possa mantenere la coerenza sulla durata richiesta.
EmptyAceStep1.5LatentAudio (#98)#
Crea la "tela" audio latente per il pezzo. Abbina i suoi secondi a quelli impostati in Song Duration (#99) e referenziati nell'encoder di testo per evitare troncamenti o padding non intenzionali. Le tele più lunghe invitano a uno sviluppo più graduale, mentre quelle più corte si adattano a loop, cue e stinger.
ModelSamplingAuraFlow (#78)#
Configura la strategia di campionamento su misura per l'audio ACE-Step. Usalo come fornito per risultati stabili; regola solo se hai una preferenza specifica per lo scheduler, poiché interagisce con il conteggio dei passaggi e la guida in KSampler (#3).
KSampler (#3)#
Esegue il denoising che trasforma il condizionamento in latenti audio. Le leve chiave qui sono il tipo di sampler, il conteggio dei passaggi e il seed. Aumenta i passaggi per affinare i dettagli a costo di tempo e mantieni fisso il seed quando confronti i prompt in modo da poter attribuire i cambiamenti al testo piuttosto che alla casualità.
DualCLIPLoader (#105)#
Carica entrambi gli encoder di testo Qwen ACE15. Se hai accesso a entrambi, inizia con l'encoder 4B attivo per una comprensione linguistica più ricca; passa alla variante 0.6B quando hai bisogno di iterazioni più rapide o un uso di memoria inferiore. Mantieni la scelta dell'encoder coerente tra i take quando valuti modifiche sottili ai prompt.
ConditioningZeroOut (#47)#
Fornisce un percorso negativo neutro. Se vuoi sopprimere specifici artefatti o allontanarti da contenuti parlati, puoi sostituirlo con un nodo di prompt negativo effettivo; altrimenti il negativo azzerato mantiene la generazione ACE-Step 1.5XL Base testo in musica focalizzata sulla tua descrizione positiva.
Extra opzionali#
- Inizia i prompt con una ricetta compatta: genere + mood + tempo + metro + chiave + strumentazione + arrangiamento + note di mix.
- Usa verbi musicali espliciti e ruoli (lead, pad, basso, percussioni) in modo che il modello allochi spazio nel mix ed eviti contenuti simili a discorsi.
- Fissa il seed quando esegui test A/B sui prompt, quindi varia il seed per esplorare esecuzioni alternative di un'idea vincente.
- Mantieni la durata allineata tra
Song Duration(#99),TextEncodeAceStepAudio1.5(#94) eEmptyAceStep1.5LatentAudio(#98) per una fraseologia prevedibile. - Scegli Qwen 4B per una comprensione più ricca del prompt o 0.6B per velocità; mantieni la tua scelta costante mentre iteri per rendere i confronti equi.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine Comfy.org per il workflow audio_ace_step1_5_xl_base, Comfy-Org per il modello di diffusione ACE Step 1.5 XL Base e ACE Step 1.5 VAE, e il team Qwen per gli encoder di testo ACE15 0.6B e 4B per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Comfy.org/Pagina sorgente del workflow
- Documenti / Note di rilascio: pagina del workflow audio_ace_step1_5_xl_base
- Comfy-Org/Modello di diffusione ACE Step 1.5 XL Base
- Hugging Face: acestep_v1.5_xl_base_bf16.safetensors
- Comfy-Org/ACE Step 1.5 VAE
- Hugging Face: ace_1.5_vae.safetensors
- Comfy-Org/Encoder di testo Qwen 0.6B ACE15
- Hugging Face: qwen_0.6b_ace15.safetensors
- Comfy-Org/Encoder di testo Qwen 4B ACE15
- Hugging Face: qwen_4b_ace15.safetensors
Nota: L'uso dei modelli, dei dataset e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.

