
Inférence Z-Image De-Turbo LoRA : génération minimale d'étapes correspondant à l'entraînement dans ComfyUI#
L'inférence Z-Image De-Turbo LoRA est un workflow RunComfy pour exécuter des adaptateurs LoRA formés par AI Toolkit sur Z-Image De-Turbo dans ComfyUI avec un comportement correspondant à l'entraînement. Il utilise RC Z-Image De-Turbo (RCZimageDeturbo)—un nœud personnalisé open-source RunComfy qui aligne l'inférence au niveau du pipeline (pas un graphe d'échantillonneur générique) tout en appliquant votre adaptateur via lora_path et lora_scale (source).
La plupart des problèmes de “prévisualisation de l'entraînement contre inférence ComfyUI” sont des incompatibilités de pipeline. RCZimageDeturbo y remédie en dirigeant Z-Image De-Turbo à travers un pipeline d'inférence aligné avec la prévisualisation et en appliquant votre unique LoRA à l'intérieur—donc lorsque vous avez besoin d'une base correspondant à l'entraînement, commencez avec ce workflow et reflétez vos valeurs d'échantillonnage de prévisualisation. Implémentation de référence : `src/pipelines/flex1_alpha.py`.
Ce que fait le nœud personnalisé RCZimageDeturbo#
RCZimageDeturbo charge le transformateur De-Turbo depuis ostris/Z-Image-De-Turbo, l'associe avec le tokenizer/encodeur de texte/VAE de Tongyi-MAI/Z-Image-Turbo, et assemble explicitement le pipeline pour éviter les problèmes d'échange de méta-tensor—puis applique votre adaptateur via lora_path / lora_scale. Référence : `src/pipelines/flex1_alpha.py`
Comment utiliser le workflow d'inférence Z-Image De-Turbo LoRA#
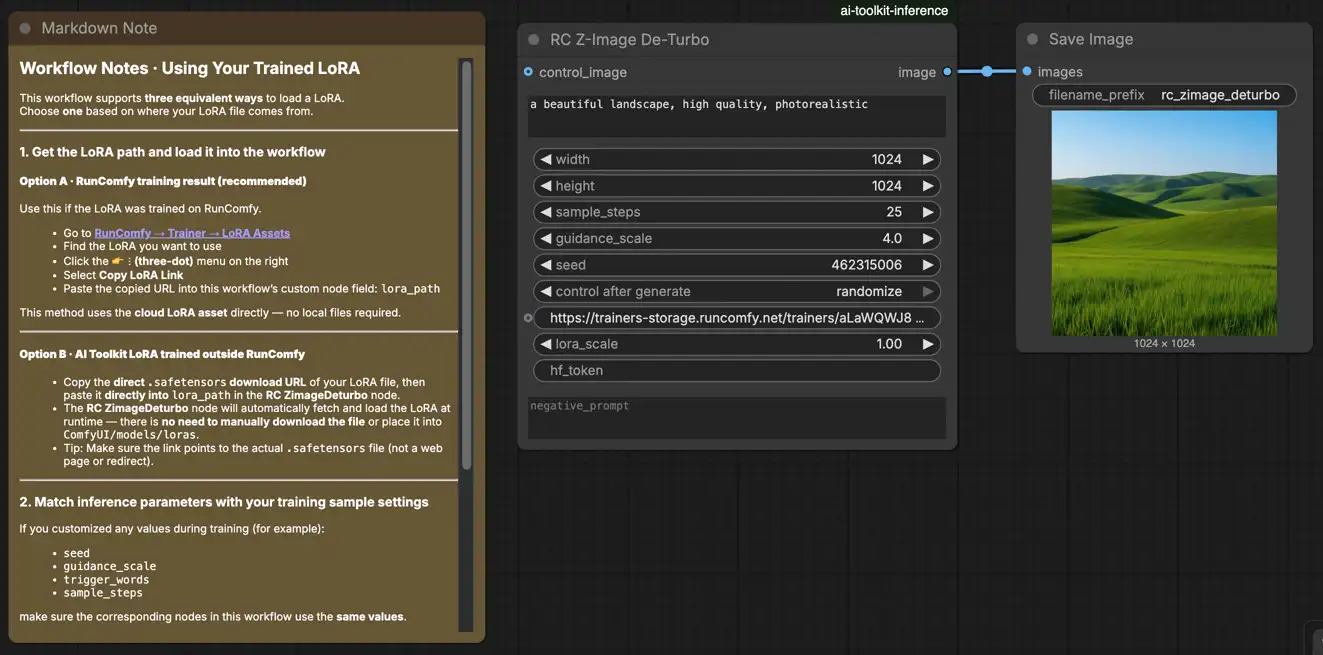
Étape 1 : Importez votre LoRA (2 options)#
- Option A (résultat d'entraînement RunComfy) : RunComfy → Trainer → LoRA Assets → trouvez votre LoRA → ⋮ → Copier le lien LoRA

- Option B (LoRA formé par AI Toolkit en dehors de RunComfy) : Copiez un lien de téléchargement direct
.safetensorspour votre LoRA et collez cette URL danslora_path(pas besoin de télécharger dansComfyUI/models/loras).
Étape 2 : Configurez le nœud personnalisé RCZimageDeturbo pour l'inférence Z-Image De-Turbo LoRA#
Configurez le reste des paramètres pour Z-Image De-Turbo LoRA Inference (tout dans l'interface du nœud) :
prompt: votre texte de prompt (incluez les tokens de déclenchement que vous avez utilisés pendant l'entraînement, le cas échéant)negative_prompt: facultatif ; laissez-le vide si votre échantillonnage de prévisualisation n'utilisait pas de négatifswidth/height: résolution de sortie (pour des comparaisons propres, correspondez à votre taille de prévisualisation ; des multiples de 32 sont recommandés)sample_steps: étapes d'inférence (De-Turbo nécessite généralement plus d'étapes que les graphes de style “Turbo”; commencez avec le même nombre d'étapes que vous avez prévisualisé pendant l'entraînement)guidance_scale: force de la guidance/CFG (correspondez d'abord à votre valeur de prévisualisation, puis ajustez par petits incréments)seed: définissez une graine fixe pour reproduire ; changez-la pour explorer des variationslora_scale: force du LoRA (commencez près de votre force de prévisualisation, puis ajustez)
Conseil d'alignement de l'entraînement : reflétez les valeurs d'échantillonnage du YAML d'entraînement AI Toolkit que vous avez utilisé pour les prévisualisations—en particulier width, height, sample_steps, guidance_scale, seed. Si vous vous êtes entraîné sur RunComfy, ouvrez Trainer → LoRA Assets → Config et copiez les paramètres de prévisualisation dans le nœud.

Étape 3 : Exécutez l'inférence Z-Image De-Turbo LoRA#
- Cliquez Queue/Run → SaveImage écrit automatiquement les résultats dans votre dossier de sortie ComfyUI
Résolution des problèmes d'inférence Z-Image De-Turbo LoRA#
La plupart des problèmes rencontrés après avoir formé un Z-Image De‑Turbo LoRA dans AI Toolkit proviennent d'une incompatibilité de pipeline—l'échantillonneur de prévisualisation AI Toolkit n'est pas le même qu'un graphe d'échantillonneur générique ComfyUI.
Le nœud personnalisé RC Z-Image De‑Turbo (RCZimageDeturbo) de RunComfy est conçu pour maintenir l'inférence alignée au pipeline avec l'échantillonnage de prévisualisation de style AI Toolkit (enveloppe spécifique au modèle + injection LoRA cohérente). Lors du dépannage, testez votre LoRA à travers RCZimageDeturbo d'abord, puis ajustez les paramètres.
(1)Pourquoi l'aperçu de l'échantillon dans aitoolkit est-il excellent, mais les mêmes mots de prompt semblent bien pires dans ComfyUI ? Comment puis-je reproduire cela dans ComfyUI ?#
Pourquoi cela se produit
Même si vous copiez le même prompt / étapes / guidance / graine, la sortie peut dériver lorsque ComfyUI exécute un pipeline différent de celui de l'aperçu AI Toolkit (différents paramètres par défaut, comportement de conditionnement et chemin d'injection LoRA).
Comment corriger (approche correspondant à l'entraînement)
- Exécutez l'inférence via RCZimageDeturbo afin que le modèle exécute un pipeline d'inférence spécifique à Z‑Image De‑Turbo et applique votre LoRA via
lora_path/lora_scaleà l'intérieur de ce pipeline. - Reflétez les valeurs d'échantillonnage de prévisualisation que vous avez utilisées pendant l'échantillonnage AI Toolkit lors de la comparaison :
width,height,sample_steps,guidance_scale,seed. - Maintenez le même format de prompt et les tokens de déclenchement avec lesquels vous vous êtes entraîné.
(2)Lors de l'utilisation de Z-Image LoRA avec ComfyUI, le message "lora key not loaded" apparaît.#
Pourquoi cela se produit
Cela signifie généralement que le LoRA est injecté via un chemin qui ne correspond pas aux modules Z‑Image (De‑Turbo) contre lesquels vous vous êtes entraîné—le plus souvent parce que :
- la variante de modèle de base ne correspond pas à ce que le LoRA attend, ou
- le format / mappage de clé LoRA ne correspond pas au chargeur/pipeline que vous utilisez.
Comment corriger (options fiables)
- Utilisez l'injection LoRA au niveau du pipeline : chargez l'adaptateur uniquement via
lora_pathsur RCZimageDeturbo (évitez d'empiler un chemin de chargeur LoRA supplémentaire par-dessus). - Privilégiez les actifs au format Diffusers pour l'inférence de pipeline : si vous mélangez les formats, essayez d'abord la version Diffusers pour l'utilisation formation/pipeline.
- Si les formats ne correspondent pas, convertissez les poids LoRA : utilisez un itinéraire de conversion connu pour les poids Z‑Image LoRA afin qu'ils correspondent au format attendu par votre pile d'inférence (Diffusers/pipeline contre chargeur natif Comfy).
(3)Impossible de charger la config pour ‘"XXXXX"#
Pourquoi cela se produit
Cela est généralement causé par des téléchargements de modèles incomplets (vous verrez souvent des blobs .incomplete dans le cache Hugging Face) ou un système de fichiers/runtime qui empêche la mise en cache correcte, ce qui fait échouer le chargement du transformateur/config.
Comment corriger (téléchargement vérifié par l'utilisateur + construction de dossier) Une approche fonctionnelle rapportée par les utilisateurs est de télécharger une base Turbo propre + le transformateur De‑Turbo, puis d'assembler un dossier complet localement :
- Téléchargez les deux dépôts avec
huggingface-cli download ... --local-dir-use-symlinks False - Remplacez
Z-Image-Turbo/transformerpar le dossierZ-Image-De-Turbo/transformer - Pointez votre chemin de modèle (ou l'environnement qui charge la base) vers le répertoire complété résultant
Après que la base se charge proprement, exécutez l'inférence via RCZimageDeturbo et correspondez les valeurs d'échantillonnage de prévisualisation pour comparer avec les prévisualisations AI Toolkit.
Exécutez l'inférence Z-Image De-Turbo LoRA maintenant#
Ouvrez le workflow Z-Image De-Turbo LoRA Inference de RunComfy, définissez lora_path, et exécutez RCZimageDeturbo pour maintenir les résultats ComfyUI alignés avec vos prévisualisations d'entraînement AI Toolkit.

