
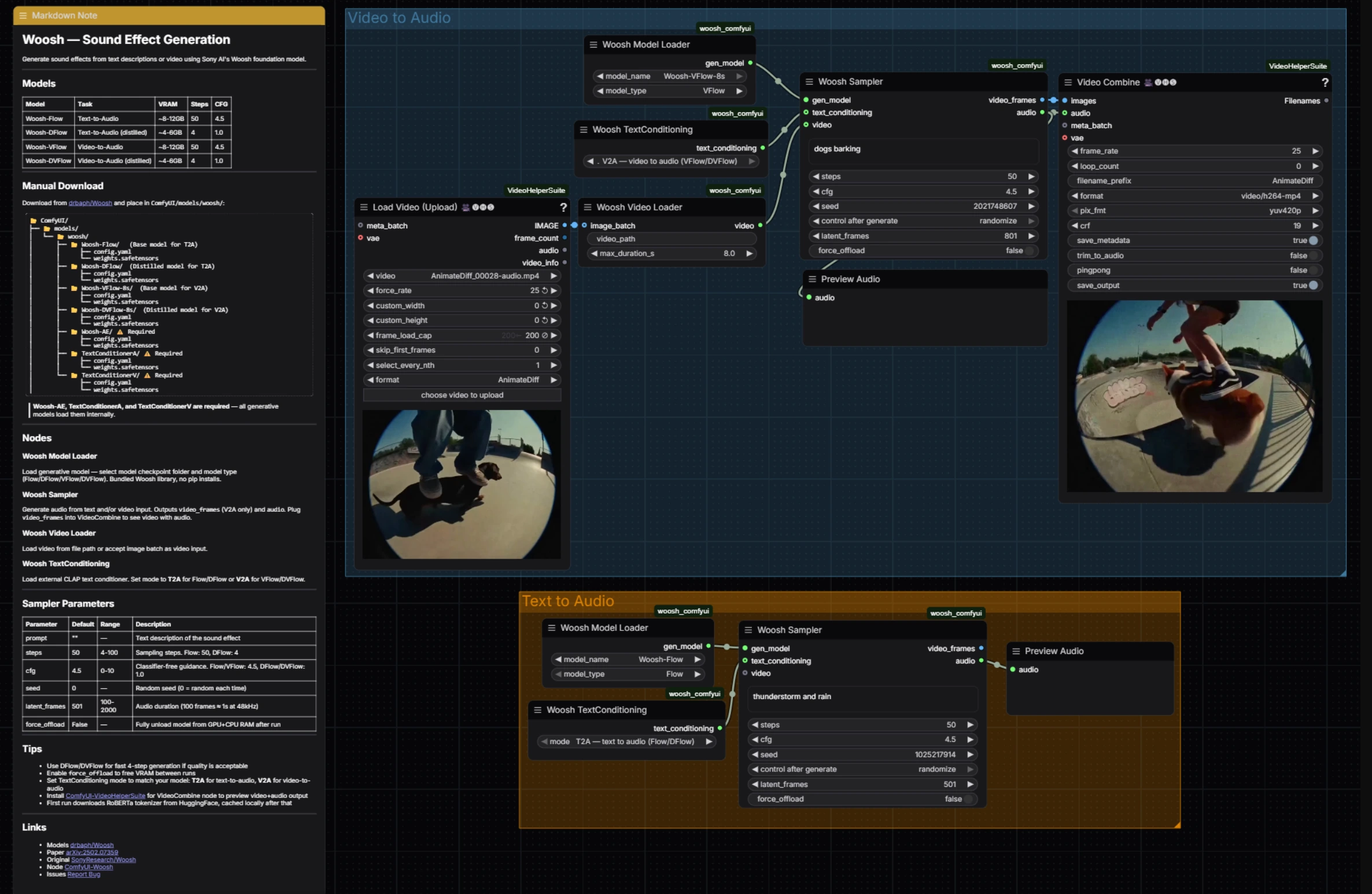
Génération d'effets sonores Woosh : audio conditionné par invite et vidéo dans ComfyUI#
La génération d'effets sonores Woosh est un flux de travail ComfyUI qui transforme soit des invites textuelles soit des clips vidéo en effets sonores raffinés en utilisant le modèle fondamental Woosh de Sony Research. Il est conçu pour les créateurs qui ont besoin d'un lieu unique pour le Foley basé sur des invites, une conception sonore étroitement appariée à la vidéo, et un passage rapide entre des variantes distillées de haute qualité et rapides.
Le flux de travail expose les deux familles de modèles Woosh : Flow/DFlow pour le texte-à-audio et VFlow/DVFlow pour la vidéo-à-audio. Un échantillonneur partagé conduit la génération dans les deux chemins, produisant de l'audio pour un aperçu immédiat et, dans le chemin vidéo, des aperçus d'images qui sont recombinés pour des quotidiens rapides. Sous le capot, il repose sur les nœuds officiels ComfyUI Woosh et VideoHelperSuite pour une IO vidéo transparente, de sorte que la génération d'effets sonores Woosh reste rapide et simple tout en restant flexible. Références : SonyResearch/Woosh, drbaph/Woosh on Hugging Face, paper, ComfyUI-Woosh, ComfyUI-VideoHelperSuite.
Modèles clés dans le flux de travail de génération d'effets sonores Woosh dans ComfyUI#
- Sony Research Woosh — Flow : générateur de texte-à-audio principal utilisé pour le Foley et l'ambiance de haute fidélité, entraîné avec des objectifs d'appariement de flux. Voir SonyResearch/Woosh et le paper.
- Sony Research Woosh — DFlow : modèle de texte-à-audio distillé optimisé pour la vitesse avec beaucoup moins d'étapes d'échantillonnage, idéal pour une itération rapide. Les poids sont disponibles via drbaph/Woosh.
- Sony Research Woosh — VFlow‑8s : générateur conditionné par vidéo qui synchronise les débuts et les textures audio aux signaux de mouvement visuel pour la vidéo-à-audio. Voir SonyResearch/Woosh.
- Sony Research Woosh — DVFlow‑8s : modèle de vidéo-à-audio distillé pour des flux de travail légers en temps réel et des aperçus rapides. Poids : drbaph/Woosh.
- Woosh‑AE : l'autoencodeur audio utilisé pour reconstruire les formes d'onde à partir des latents du modèle ; requis par tous les générateurs. Poids : drbaph/Woosh.
- TextConditionerA et TextConditionerV : modules de conditionnement textuel qui intègrent les invites de manière appropriée pour les exécutions de texte-à-audio ou de vidéo-à-audio. Les détails et l'utilisation sont documentés dans ComfyUI-Woosh et le paper.
Comment utiliser le flux de travail de génération d'effets sonores Woosh dans ComfyUI#
Ce flux de travail a deux groupes parallèles que vous pouvez exécuter indépendamment : Vidéo à Audio pour une conception sonore appariée visuellement et Texte à Audio pour un Foley purement basé sur des invites. Les deux convergent sur la même logique d'échantillonneur et un aperçu audio rapide, rendant la génération d'effets sonores Woosh cohérente à opérer quel que soit l'entrée.
Vidéo à Audio#
Le groupe Vidéo à Audio charge un clip, aligne les images et le conditionnement, puis génère un son synchronisé. Commencez par alimenter votre clip dans VHS_LoadVideo (#34) ; il extrait les images à votre rythme choisi pour que les nœuds en aval voient une séquence propre et délimitée. Ces images sont emballées comme un flux de conditionnement vidéo par WooshLoadVideo (#37), qui standardise la durée pour que le générateur reçoive des fenêtres stables.
Choisissez un modèle conditionné par vidéo dans WooshLoadFlow (#7), généralement VFlow pour la fidélité ou DVFlow pour la vitesse. Fournissez une courte invite descriptive dans l'échantillonneur (pour le style ou l'intention) et réglez WooshTextEncode (#19) sur V2A pour que le texte soit intégré avec la branche de conditionnement correcte. Exécutez WooshSample (#38) pour synthétiser l'audio ; il produit à la fois audio pour PreviewAudio (#9) et video_frames qui s'écoulent dans VHS_VideoCombine (#33) pour un aperçu cousu rapide, gardant la génération d'effets sonores Woosh serrée pour une révision éditoriale.
Texte à Audio#
Le groupe Texte à Audio se concentre sur une génération propre basée sur les invites. Sélectionnez un modèle dans WooshLoadFlow (#40), en utilisant Flow lorsque vous voulez une qualité maximale et DFlow lorsque vous avez besoin de passes très rapides et itératives. Réglez WooshTextEncode (#41) sur T2A pour que votre invite soit intégrée pour une génération uniquement textuelle. Entrez votre description dans WooshSample (#39) et exécutez ; le résultat est envoyé à PreviewAudio (#43) pour une écoute instantanée. Ce chemin garde la génération d'effets sonores Woosh légère lorsque vous créez des bibliothèques ou superposez des effets sans image.
Nœuds clés dans le flux de travail de génération d'effets sonores Woosh dans ComfyUI#
WooshSample (#38)#
Échantillonneur central pour la génération conditionnée par vidéo. Ajustez l'invite pour orienter le style et les débuts, puis réglez steps pour le compromis qualité-vitesse (utilisez moins d'étapes lors de l'exécution de DVFlow). cfg contrôle l'adhérence à l'invite, et latent_frames détermine la longueur de sortie pour qu'elle corresponde ou délibérément décale le clip. Réglez seed pour reproduire les prises, et activez force_offload lorsque vous devez vider la mémoire entre les longues exécutions. L'implémentation et le comportement du nœud suivent le ComfyUI-Woosh officiel.
WooshSample (#39)#
Échantillonneur pour le texte-à-audio avec les mêmes contrôles et comportements, moins le flux vidéo. Pour une idéation rapide, choisissez DFlow et un faible nombre de steps; pour les finales, passez à Flow et augmentez steps pour plus de détails. Gardez cfg modéré pour des textures naturelles, poussez plus haut pour des résultats stylisés et verrouillés sur l'invite. Utilisez latent_frames pour définir précisément la durée lors de la création d'actifs pour des bibliothèques ou des timelines DAW.
WooshLoadFlow (#7)#
Sélecteur de modèle pour le chemin Vidéo à Audio. Choisissez VFlow pour un alignement de la plus haute fidélité avec le mouvement, ou DVFlow lorsque vous avez besoin d'aperçus presque en temps réel. Assurez-vous que WooshTextEncode est réglé sur V2A pour que les intégrations correspondent à la famille de modèles choisie. Voir drbaph/Woosh pour les variantes de modèles.
WooshLoadFlow (#40)#
Sélecteur de modèle pour le chemin Texte à Audio. Choisissez Flow pour des détails riches et une variété de textures plus large, ou DFlow pour une itération rapide avec un minimum d'étapes. Associez-le à WooshTextEncode en mode T2A pour éviter les incompatibilités de conditionnement. Le comportement et les options du nœud suivent le ComfyUI-Woosh officiel.
VHS_VideoCombine (#33)#
Utilitaire pour assembler l'audio généré avec l'aperçu video_frames de l'échantillonneur pour produire un clip révisable. Utilisez-le pour repérer la synchronisation, évaluer les transitions et partager des quotidiens sans quitter ComfyUI. Partie de ComfyUI-VideoHelperSuite.
Extras optionnels#
- Utilisez DVFlow/DFlow pour des passages d'exploration rapides, puis passez à VFlow/Flow pour les finales lorsque la génération d'effets sonores Woosh doit briller.
- Gardez votre clip d'entrée dans la fenêtre du modèle sélectionné (par exemple, les variantes VFlow de 8 secondes) et traitez des scènes plus longues en morceaux qui se chevauchent et que vous pouvez fondre enchaîner.
- Maintenez un taux de trame constant de
VHS_LoadVideoàVHS_VideoCombinepour réduire la dérive entre l'audio et l'image. - Pour les invites, associez des mots d'action avec le contexte de texture et acoustique (par exemple, "whoosh métallique rapide dans une cage d'escalier en béton") pour obtenir des résultats prévisibles.
- Activez
force_offloaddans l'échantillonneur entre les exécutions lourdes si la mémoire GPU est limitée.
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Sony Research pour Woosh (projet et article), Saganaki22 pour ComfyUI-Woosh (nœud ComfyUI), et Kosinkadink pour ComfyUI-VideoHelperSuite pour leurs contributions et leur maintenance. Pour des détails autorisés, veuillez vous référer à la documentation originale et aux référentiels liés ci-dessous.
Ressources#
- Saganaki22/ComfyUI-Woosh
- GitHub: Saganaki22/ComfyUI-Woosh
- drbaph/Woosh
- Hugging Face: drbaph/Woosh
- SonyResearch/Woosh
- GitHub: SonyResearch/Woosh
- Sony Research/Woosh (paper)
- arXiv: 2502.07359
- Kosinkadink/ComfyUI-VideoHelperSuite
Note: L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.