
VOID Video Inpainting ComfyUI: suppression d'objets sensible à l'interaction pour une vidéo propre et cohérente#
Ce flux de travail VOID Video Inpainting ComfyUI supprime les objets et leurs interactions visuelles d'un clip avec une cohérence temporelle. Il combine la segmentation textuelle SAM3 de Meta pour définir le masque avec le remplissage vidéo en deux passes de Netflix VOID pour combler le vide au fil du temps, donnant des résultats qui semblent comme si l'objet indésirable et ses effets proches n'étaient jamais là.
Les créateurs, éditeurs et équipes VFX peuvent compter sur VOID Video Inpainting ComfyUI lorsque le nettoyage image par image scintille ou casse à travers le mouvement. Le flux de travail génère deux clips : Pass 1 comme un intermédiaire rapide et Pass 2 comme un résultat raffiné avec une stabilité temporelle renforcée. Fournissez une vidéo source, une courte phrase SAM3 décrivant l'objet à supprimer, et une invite de remplissage décrivant la scène que vous souhaitez conserver.
Modèles clés dans le flux de travail ComfyUI VOID Video Inpainting ComfyUI#
- VOID: Suppression d'Objets et d'Interactions Vidéo. Diffusion en deux passes pour la suppression d'objets vidéo avec raisonnement temporel; l'implémentation de référence et les checkpoints sont fournis par Netflix. GitHub et Hugging Face
- Segment Anything Model 3.1 Multiplex (SAM3.1). Segmentation d'image textuelle et prompte utilisée pour générer le masque d'objet qui guide le remplissage. Hugging Face
- RAFT: Recurrent All-Pairs Field Transforms. Flux optique utilisé pour déformer le bruit de Pass 1 en Pass 2 afin que le mouvement reste cohérent à travers les images. arXiv et poids dans le pack modèle VOID sur Hugging Face
- CogVideoX VAE. Codec latent pour l'encodage et le décodage des images vidéo pendant le remplissage. Hugging Face
- T5-XXL encodeur de texte (fp16). Épine dorsale linguistique qui transforme les invites positives et négatives en conditionnement pour le modèle de diffusion. Hugging Face
Comment utiliser le flux de travail ComfyUI VOID Video Inpainting ComfyUI#
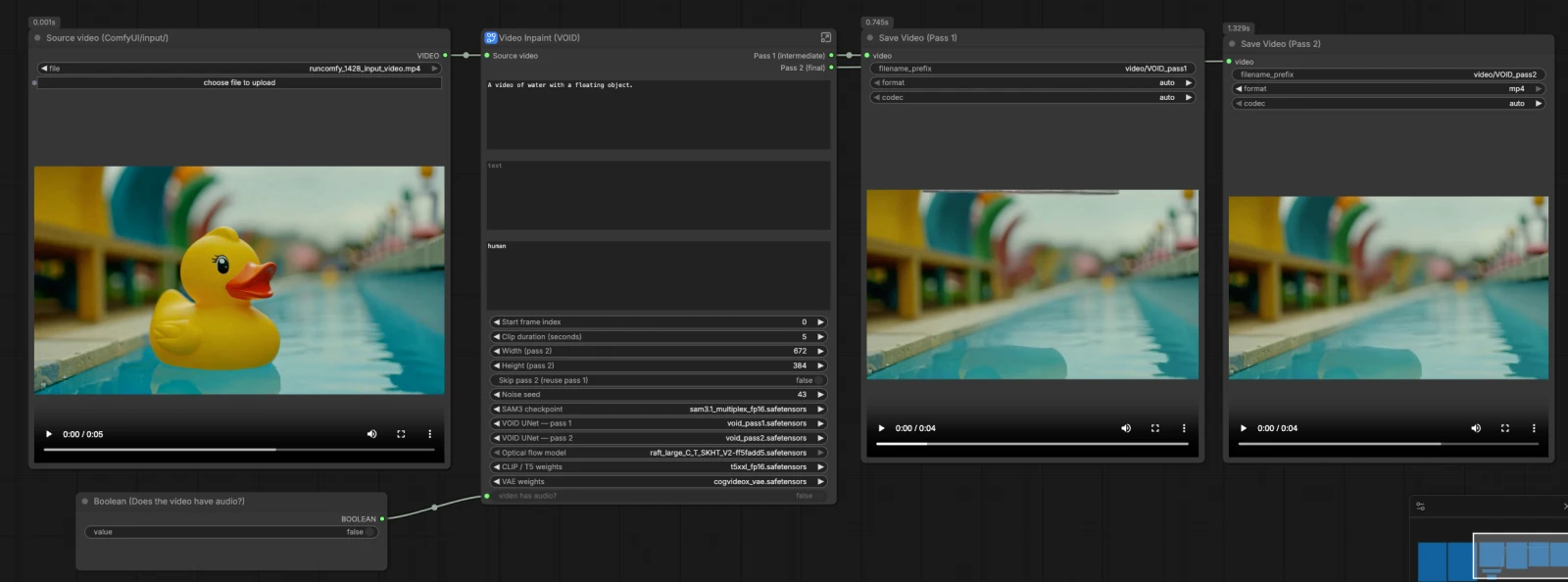
Ce graphique VOID Video Inpainting ComfyUI suit un chemin clair : charger les modèles et le clip source, créer un masque d'objet avec SAM3, construire un conditionnement partagé à partir de vos invites et du masque, exécuter Pass 1 pour établir le contenu, puis exécuter Pass 2 avec un bruit déformé pour un mouvement stable. L'audio est éventuellement ajusté pour correspondre au segment traité. Le flux de travail sauvegarde les vidéos Pass 1 et Pass 2 afin que vous puissiez comparer ou avancer rapidement.
Modèles#
Ce groupe charge tous les composants nécessaires pour VOID Video Inpainting ComfyUI. CLIPLoader (#2) apporte l'encodeur de texte T5-XXL, et VAELoader (#3) fournit le CogVideoX VAE. UNETLoader (#144) initialise le VOID UNet pour Pass 1 et UNETLoader (#143) configure le VOID UNet pour Pass 2. OpticalFlowLoader (#142) charge le modèle RAFT qui pilote ensuite la déformation du bruit entre les passes.
Vidéos d'entrée (placer les fichiers dans ComfyUI/input/)#
Pointez le chargeur Source video (ComfyUI/input/) vers votre clip, puis GetVideoComponents (#166) le divise en images, audio et fps. ImageFromBatch (#145) sélectionne une image représentative pour prévisualiser le masque. GetImageSize (#43) et des noeuds mathématiques simples calculent la longueur du clip et les index pour un découpage cohérent. Fournissez l'image de départ et la durée pour cibler uniquement la section que vous souhaitez traiter.
Créer un masque#
Le sous-graphique Image Segmentation (SAM3) génère un masque d'objet par image pour VOID Video Inpainting ComfyUI. SAM3_Detect (#75) utilise votre invite textuelle SAM3 pour segmenter l'objet sur l'image sélectionnée, avec CLIPTextEncode (#78) encodant la phrase. Le masque est prévisualisé dans MaskPreview (#132) afin que vous puissiez vérifier la couverture et affiner le libellé si nécessaire. Une phrase claire et spécifique comme "tasse rouge sur la table" ou "personne en veste bleue" aide SAM3 à isoler le bon sujet.
Partagé : Conditionnement Texte & Masque#
Positive Prompt (CLIPTextEncode (#6)) doit décrire la scène telle qu'elle devrait apparaître après la suppression, pas l'acte de suppression. Negative Prompt (CLIPTextEncode (#7)) liste éventuellement les artefacts que vous ne voulez pas. VOIDInpaintConditioning (#10) fusionne les invites, le VAE, les images entrantes, votre masque SAM3, et les dimensions cibles en un paquet de conditionnement latent utilisé par les deux passes. Considérez cela comme disant à VOID ce qu'il faut conserver et comment le mouvement et l'apparence devraient se sentir une fois l'objet disparu.
Pass 1: Échantillon (Bruit aléatoire → DDIM)#
Pass 1 dans VOID Video Inpainting ComfyUI établit un remplissage plausible en utilisant du bruit aléatoire standard. RandomNoise (#141) amorce le processus, BasicScheduler (#138) et VOIDSampler (#133) définissent le calendrier de diffusion, et CFGGuider (#140) mélange vos invites dans le modèle. SamplerCustomAdvanced (#49) synthétise le clip latent, et VAEDecode (#45) le transforme à nouveau en images. CreateVideo (#46) attache éventuellement l'audio et écrit une vidéo intermédiaire Pass 1 que vous pouvez inspecter avant le raffinement.
Pass 2: Échantillon (Bruit déformé → DDIM)#
Pass 2 améliore la stabilité temporelle en commençant par un bruit déformé à partir des images de Pass 1 plutôt que par un nouvel aléatoire. VOIDWarpedNoise (#31) utilise le flux optique RAFT avec les images de Pass 1 pour créer un bruit aligné dans le temps, puis VOIDWarpedNoiseSource (#32) l'intègre dans l'échantillonnage. CFGGuider (#136), BasicScheduler (#137), et VOIDSampler (#134) configurent le deuxième échantillonneur, et SamplerCustomAdvanced (#35) affine le contenu rempli. VAEDecode (#36) produit les images finales. Si vous activez le saut, ComfySwitchNode (#150) dirige les images de Pass 1 directement vers la sortie pour des prévisualisations rapides.
Taille de la vidéo de sortie#
Les contrôles de largeur et de hauteur déterminent la résolution latente pour Pass 2 et le générateur de bruit déformé. Ces valeurs influencent la netteté, la stabilité et la charge de calcul dans VOID Video Inpainting ComfyUI. Choisissez des dimensions qui correspondent à vos objectifs de contenu et à la mémoire disponible. La même taille est utilisée de manière cohérente dans tout le pipeline pour garder le mouvement et les masques alignés.
Sauter Pass 2#
Lorsque vous avez besoin d'une vérification rapide, utilisez le contrôle de saut pour que VOID Video Inpainting ComfyUI réutilise Pass 1 sans exécuter Pass 2. ComfySwitchNode (#150) sélectionne automatiquement entre les images de Pass 1 et Pass 2. Cela est utile pour les coupes brutes ou lorsque vous ajustez les phrases de masque ou les invites. Reactivez Pass 2 pour verrouiller la cohérence temporelle pour le rendu final.
Couper l'audio#
Si votre clip contient de l'audio, VOID Video Inpainting ComfyUI coupe et rattache l'audio pour que la longueur de sortie corresponde au segment traité. TrimAudioDuration (#158) maintient le son synchronisé, et ComfySwitchNode (#174) gère les clips silencieux en toute sécurité. Les fps de GetVideoComponents (#166) pilotent les nœuds CreateVideo de Pass 1 et Pass 2 pour éviter les dérives. Réglez correctement le commutateur "la vidéo a-t-elle de l'audio ?" pour obtenir le résultat attendu.
Nœuds clés dans le flux de travail ComfyUI VOID Video Inpainting ComfyUI#
SAM3_Detect (#75)#
Génère le masque d'objet à partir d'une courte phrase SAM3. Si le masque est trop lâche ou trop serré, affinez le libellé pour mieux décrire la cible et son contexte. Vous pouvez également ajuster les commandes de raffinement interne pour affiner les bords si nécessaire. Des masques solides rendent le remplissage ultérieur plus stable.
VOIDInpaintConditioning (#10)#
Construit le paquet de conditionnement à partir de votre invite positive, de votre invite négative, du VAE, des images et du masque SAM3. L'invite positive doit décrire la scène qui reste; évitez les formulations comme "supprimer X". Utilisez l'invite négative uniquement lorsque des artefacts cohérents apparaissent. Les signaux latents et de conditionnement résultants alimentent les deux passes.
SamplerCustomAdvanced (#49) - Pass 1#
Exécute l'échantillonnage VOID pour la première passe avec du bruit aléatoire. La graine de bruit contrôle la répétabilité; changez-la lorsque vous voulez un motif de remplissage différent. Gardez l'échantillonneur et le planificateur appariés avec le UNet de Pass 1. Inspectez cette passe pour valider la composition et le mouvement de base avant le raffinement.
VOIDWarpedNoise (#31)#
Crée un bruit aligné temporellement en utilisant le flux optique RAFT calculé à partir des images de Pass 1. Cela préserve les indices de mouvement dans Pass 2 et réduit le scintillement. Si le mouvement semble instable, revisitez la qualité du masque ou essayez une graine différente dans Pass 1 pour générer une meilleure base pour la déformation.
SamplerCustomAdvanced (#35) - Pass 2#
Affine la région remplie en commençant par le bruit déformé. Utilisez-le pour verrouiller les textures et stabiliser les détails fins au fil du temps. Lorsque les sorties sont déjà stables, vous pouvez sauter Pass 2 pour gagner du temps; sinon, gardez-le activé pour la livraison finale.
ComfySwitchNode (#150) - Contrôle de saut#
Basculer entre les images de Pass 1 et Pass 2 pour la sortie finale. Utilisez ceci pour vérifier la qualité ou accélérer les itérations pendant que vous ajustez les invites et le masque SAM3. Éteignez-le pour le résultat définitif VOID Video Inpainting ComfyUI.
Extras optionnels#
- Écrivez des invites positives pour le monde que vous souhaitez voir après la suppression, par exemple "comptoir de cuisine vide, lumière du jour, carreaux propres" plutôt que "supprimer la tasse".
- Gardez les phrases SAM3 spécifiques, comme "personne en veste bleue" ou "tasse rouge sur la table," et relancez après de petites modifications pour confirmer la couverture dans l'aperçu du masque.
- Utilisez l'image de départ et la durée pour limiter le traitement à la section pertinente; les longs clips sont mieux traités par segments.
- Sautez Pass 2 pour les brouillons, puis activez-le pour la stabilisation finale dans VOID Video Inpainting ComfyUI.
- Ajustez la largeur et la hauteur pour équilibrer les détails avec la mémoire GPU; des résolutions plus élevées sont plus nettes mais coûtent plus de calcul.
Remerciements#
Ce flux de travail implémente et s'appuie sur les travaux et ressources suivants. Nous remercions sincèrement Netflix pour le modèle VOID, Comfy-Org pour les fichiers modèles VOID et SAM3.1, et RunComfy pour la source du flux de travail Cloud Save pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation et aux référentiels originaux liés ci-dessous.
Ressources#
- Netflix/void-model
- GitHub: netflix/void-model
- Comfy-Org/void-model
- Hugging Face: Comfy-Org/void-model
- Comfy-Org/sam3.1
- Hugging Face: Comfy-Org/sam3.1
- RunComfy/Cloud Save source
- Docs / Release Notes: Cloud Save source
Note: L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.