

Stable Diffusion 3.5 VS FLUX.1#
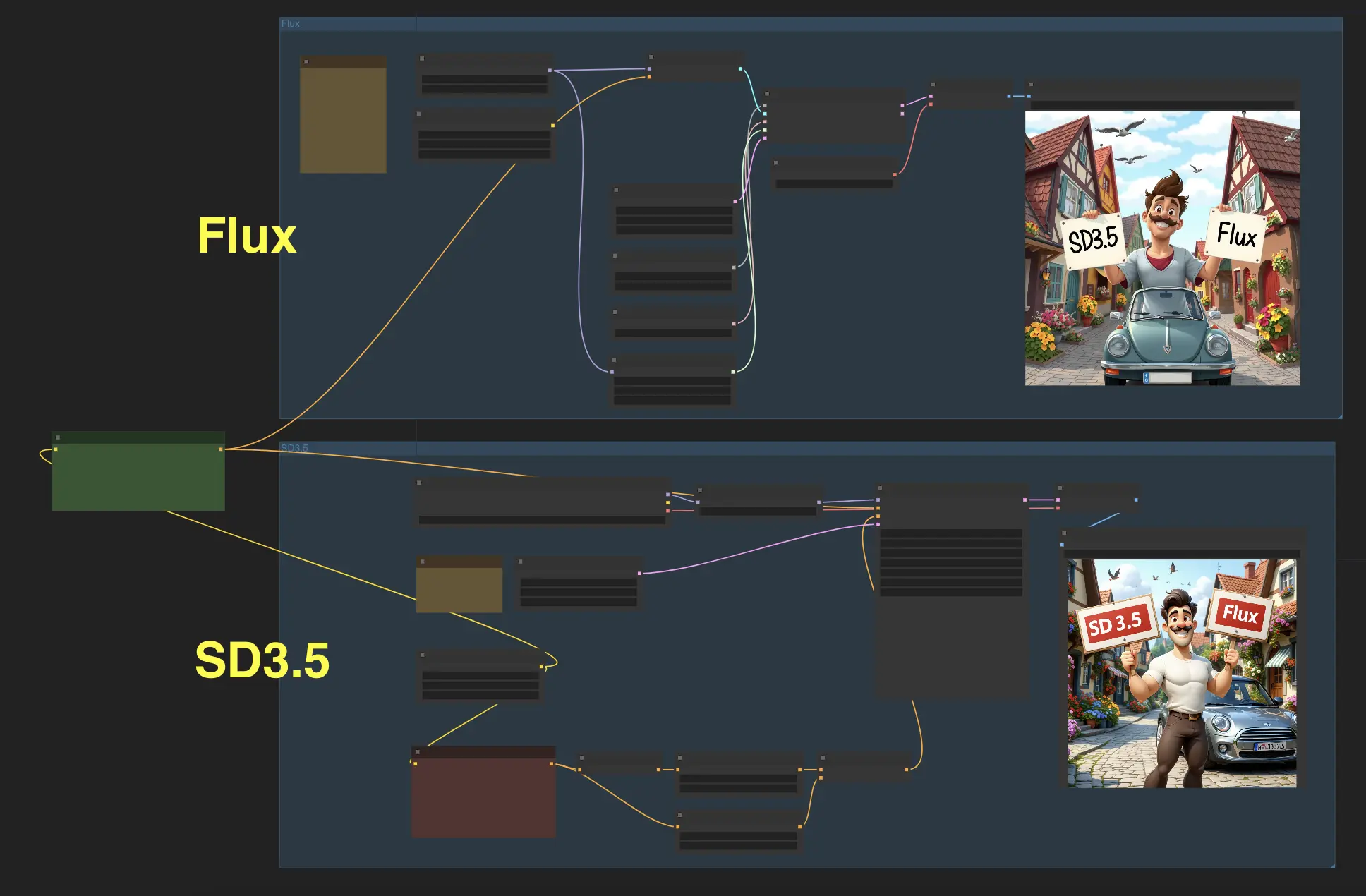
Préparez-vous à découvrir les capacités impressionnantes de deux modèles de pointe : Stable Diffusion 3.5 (SD3.5) et FLUX.1. Avec ce flux de travail ComfyUI, vous pouvez maintenant saisir une invite textuelle et générer des images avec ces deux modèles simultanément, vous permettant de comparer les résultats et de choisir celui que vous préférez.
Nous avons testé quelques cas en utilisant SD3.5-large et Flux.1-schnell, et les résultats révèlent que Stable Diffusion 3.5 (SD3.5) et FLUX.1 excellent chacun dans différents domaines. Alors que FLUX.1 a un avantage dans la production d'images photoréalistes, SD3.5 démontre une plus grande compétence dans la génération d'œuvres d'art de style anime sans nécessiter de réglages supplémentaires ou de modifications.
Ne vous fiez pas seulement à notre parole – découvrez la magie par vous-même!








