
Stable Audio Open 1.0 Workflow Texte-à-Musique#
Ce workflow transforme le texte brut en musique originale et paysages sonores en utilisant Stable Audio Open 1.0. Il est conçu pour les compositeurs, designers sonores et créateurs qui souhaitent une génération audio rapide et contrôlable sans quitter ComfyUI. Vous écrivez un prompt, définissez une durée cible, et le graphique rend un MP3 qui reflète votre style, humeur, tempo et instrumentation.
Sous le capot, le workflow encode votre texte avec un encodeur de texte basé sur T5, exécute le processus de diffusion de Stable Audio dans l'espace audio latent, puis décode en une forme d'onde et enregistre le résultat. Avec des conseils de prompt clairs et un contrôle de longueur simple, la génération Stable Audio devient prévisible et répétable pour des pistes cinématiques, ambiantes ou expérimentales.
Modèles clés dans le workflow Stable Audio de ComfyUI#
- Stable Audio Open 1.0. Modèle de diffusion latent open-weight pour la musique et la conception sonore texte-à-musique par Stability AI. Il mappe l'intention textuelle aux latents audio et prend en charge des styles et structures musicales variés. Repository • Weights
- T5-Base Text Encoder. Modèle de texte à usage général utilisé ici pour intégrer les prompts pour le conditionnement de la génération Stable Audio. Des entrées claires et descriptives mènent à une musique plus cohérente. Model card
Comment utiliser le workflow Stable Audio de ComfyUI#
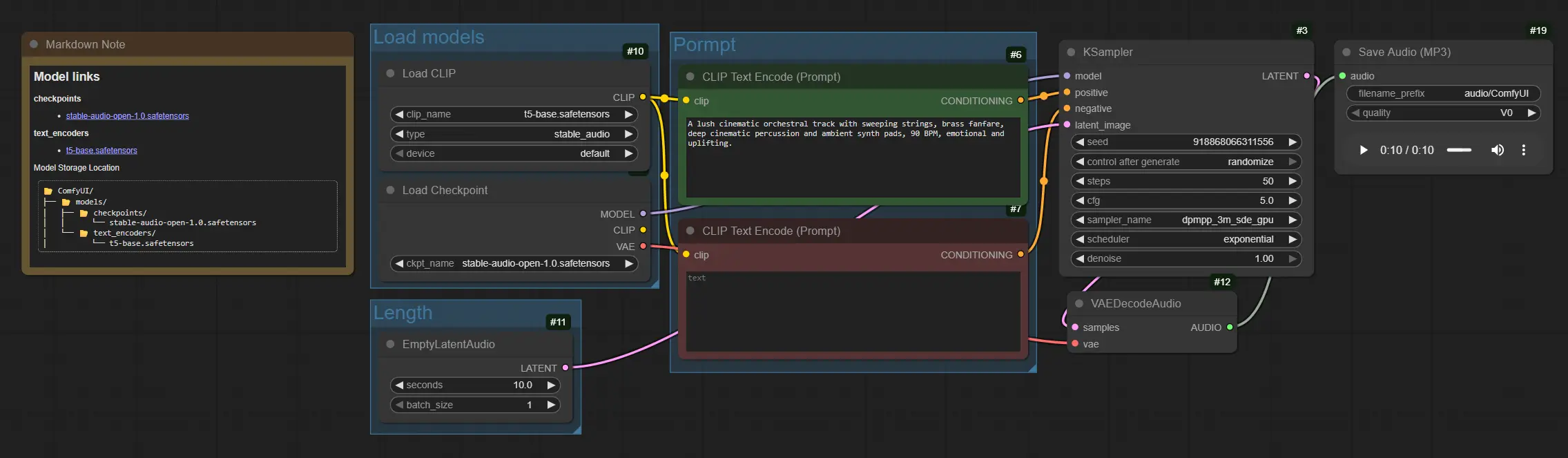
Le graphique s'écoule du chargement du modèle au conditionnement du prompt, puis à l'échantillonnage, au décodage et à l'enregistrement. Les groupes sont organisés pour que vous puissiez définir les modèles une fois, ajuster la longueur, écrire votre prompt, et rendre.
Charger les modèles#
Ce groupe initialise les ressources principales. CheckpointLoaderSimple (#4) charge le checkpoint Stable Audio Open 1.0, qui comprend le modèle de diffusion et son audio VAE. CLIPLoader (#10) charge l'encodeur de texte basé sur T5 utilisé pour le conditionnement. Une fois chargés, ces modèles fournissent l'épine dorsale pour la génération Stable Audio et restent résidents pour les exécutions ultérieures.
Longueur#
Ce groupe définit la durée de votre audio. EmptyLatentAudio (#11) crée une piste latente vierge avec la durée choisie afin que l'échantillonneur sache combien d'images générer. Les clips plus longs consomment plus de temps et de mémoire, donc commencez modestement, puis augmentez. Vous pouvez également produire plusieurs variations en augmentant la dimension de lot lors de l'exploration des idées.
Prompt#
Ce groupe transforme le texte en signaux de guidage pour le processus de diffusion. Utilisez CLIPTextEncode (#6) pour écrire un prompt positif avec des instruments, genre, humeur, tempo et indices de production, par exemple : "orchestre cinématique luxuriant, cordes et cuivres balayant, percussions profondes, pads ambiants, 90 BPM, exaltant." Utilisez CLIPTextEncode (#7) pour un prompt négatif afin de supprimer les artefacts tels que "bruit dur, coupure, distorsion." Ensemble, ils orientent Stable Audio vers les textures et structures que vous souhaitez.
Générer et exporter#
KSampler (#3) effectue les étapes de diffusion qui transforment le latent vide en un latent musical guidé par vos encodages textuels. VAEDecodeAudio (#12) reconvertit l'audio latent en une forme d'onde. Enfin, SaveAudioMP3 (#19) écrit un fichier MP3 pour que vous puissiez le revoir ou le déposer directement dans votre chronologie. Pour un travail itératif, ajustez le préfixe du nom de fichier pour garder les prises organisées.
Nœuds clés dans le workflow Stable Audio de ComfyUI#
CLIPTextEncode(#6) Ce nœud encode votre prompt positif en un conditionnement que Stable Audio suit. Priorisez des listes claires d'instruments, genre, humeur, tempo ou BPM, et termes de production comme "chaleureux," "lo-fi," "cinématique," ou "ambiant." Des changements subtils dans la formulation peuvent modifier significativement la composition. Voir les nœuds de base de ComfyUI pour le comportement général. ComfyUICLIPTextEncode(#7) Le prompt négatif aide à éviter les timbres indésirables ou les problèmes de mixage. Ajoutez des termes décrivant ce à quoi renoncer, par exemple "criard, sonnerie métallique, pops de glitch, sifflement radio." Garder ceci concis produit souvent des rendus Stable Audio plus propres. ComfyUIEmptyLatentAudio(#11) Contrôle la durée du clip en secondes et éventuellement le nombre de lots pour plusieurs variations. Augmentez les secondes pour des morceaux plus longs, en notant que le calcul évolue avec la longueur. Utilisez la génération par lots pour auditionner plusieurs prises Stable Audio à partir d'un seul prompt. ComfyUIKSampler(#3) Conduit le processus de diffusion pour les latents audio. Les contrôles les plus influents sontsteps,sampler,cfg, etseed. Augmentezstepspour plus de détails raffinés, ajustezcfgpour équilibrer l'adhérence au prompt avec la créativité, et fixez unseedpour reproduire une prise ou la varier pour de nouvelles idées. Reportez-vous aux notes de l'échantillonneur de ComfyUI pour des conseils généraux. ComfyUISaveAudioMP3(#19) Exporte la forme d'onde finale en un MP3. Utilisez lefilename_prefixpour étiqueter les versions et garder les itérations ordonnées. Lors de la comparaison de prompts ou de seeds, enregistrer plusieurs prises côte à côte rend la sélection Stable Audio plus rapide. ComfyUI
Extras optionnels#
- Écrivez des prompts comme un brief de session : instruments, genre, humeur, tempo ou BPM, et adjectifs de mixage.
- Utilisez des prompts négatifs courts et ciblés pour réduire le sifflement, la dureté ou les instruments indésirables.
- Verrouillez
seedtout en itérant le texte, puis changezseedpour explorer de nouvelles variations Stable Audio. - Commencez avec des durées plus courtes pour peaufiner le style, puis allongez une fois que le son est correct.
- Gardez un préfixe de nom de fichier cohérent par concept pour pouvoir comparer les prises Stable Audio plus tard.
Ressources pour une lecture approfondie : détails et exemples du modèle Stable Audio ici, noyau et comportement des nœuds de ComfyUI ici, et la carte du modèle T5-Base ici.
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Stability AI pour Stable Audio Open, comfyanonymous (ComfyUI) pour les nœuds ComfyUI et les références de workflow, et Comfy-Org et ComfyUI-Wiki pour le checkpoint Stable Audio Open 1.0 et l'encodeur de texte T5-Base pour leurs contributions et maintenance. Pour des détails d'autorité, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Comfy-Org/Stable Audio Open 1.0 workflow
- GitHub: Stability-AI/stable-audio-open
Note: L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.
