
SkyReels V3 ComfyUI : création d'images, vidéos et audio fidèles à l'identité#
SkyReels V3 ComfyUI est un workflow prêt pour la production qui intègre le modèle vidéo multimodal SkyReels V3 dans ComfyUI afin que vous puissiez animer des images fixes, étendre des plans existants et créer des avatars parlants pilotés par audio avec une synchronisation labiale précise. Il est conçu pour les créateurs qui souhaitent un mouvement cinématographique, une identité de sujet forte et une cohérence temporelle tout en restant dans un graphique de nœuds flexible.
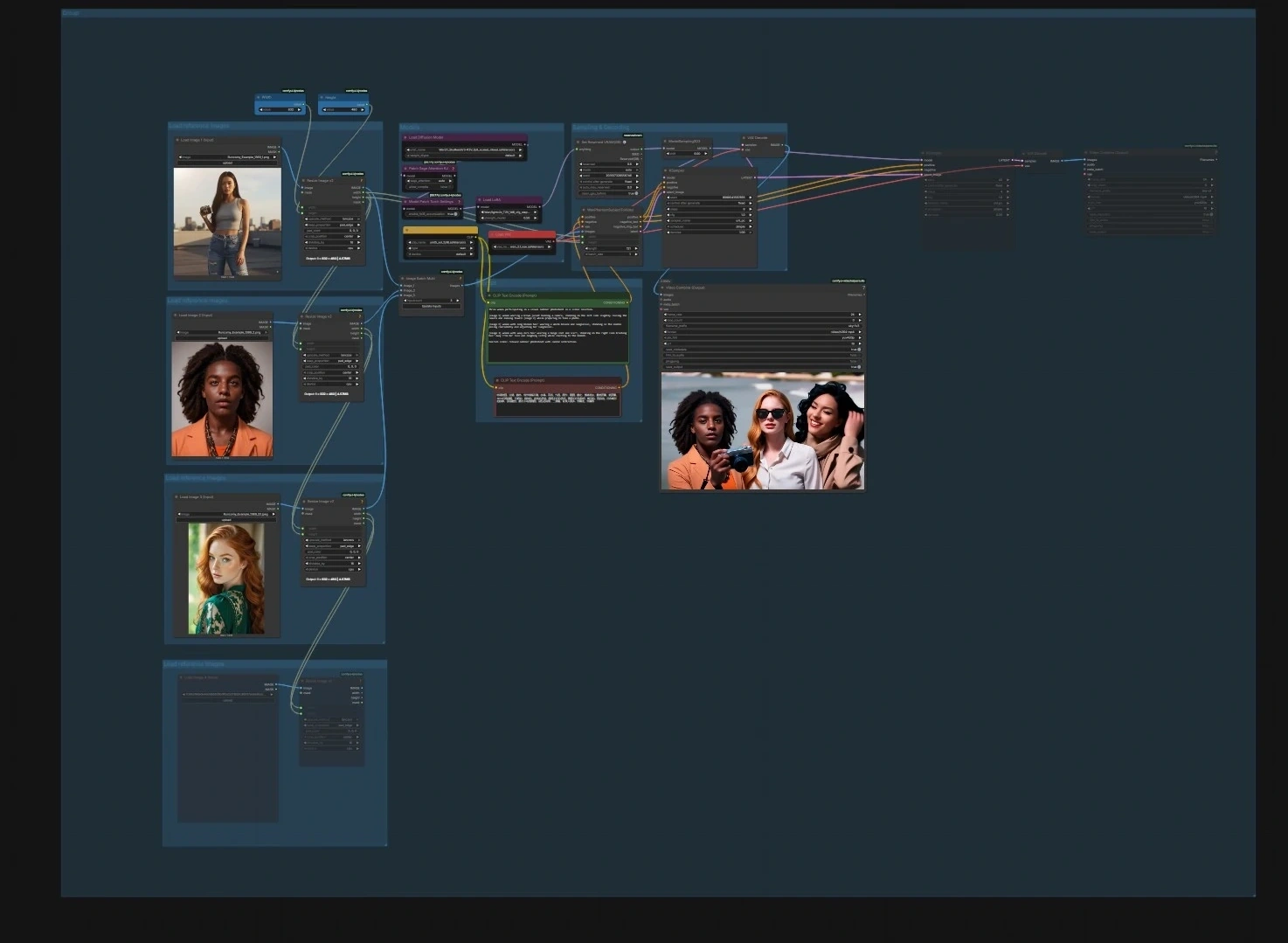
Le workflow est livré avec quatre pipelines ciblés qui peuvent être exécutés de manière indépendante ou enchaînés : animation de personnage d'image à vidéo, continuation de vidéo à vidéo, avatars parlants d'audio à vidéo, et génération de plan suivant pour le flux narratif. Chaque chemin comprend des points d'entrée clairs et des valeurs par défaut judicieuses afin que vous puissiez insérer vos ressources et rendre rapidement des résultats SkyReels V3 de haute qualité.
Note pour les machines 2X Large et plus grandes (workflow R2V) : Réglez
Patch Sage Attention KJ(#240)sage_attentionsurdisabledavant de lancer. Le laisser activé peut déclencher des erreursSM90 kernel is not available.
Modèles clés dans le workflow Comfyui SkyReels V3 ComfyUI#
- SkyReels V3 video backbones (R2V, V2V Shot, A2V) du pack WanVideo FP8. Ce sont les générateurs principaux qui gèrent le mouvement conscient de l'identité, la continuation vidéo et la synchronisation labiale conditionnée par l'audio. Voir les poids SkyReels V3 dans le pack WanVideo sur Hugging Face ici.
- Modèles OpenCLIP Vision ViT pour l'orientation d'image et l'intégration de référence. Ils fournissent des fonctionnalités visuelles robustes qui aident à préserver l'apparence et le style à travers les images. Page du projet : open_clip.
- Encodeur de texte UMT5 pour la compréhension des invites. Il fournit un conditionnement linguistique riche pour orienter le style, la scène et les actions. Repo : umt5.
- Fonctionnalités de parole Wav2Vec2 pour la synchronisation labiale et l'analyse audio. La variante de base chinoise est prise en charge dès le départ et des variantes similaires en anglais fonctionnent également. Carte du modèle : TencentGameMate/chinese-wav2vec2-base.
- Qwen3-ASR-1.7B pour la conversion de la parole en texte. Utilisé pour transcrire l'audio de référence et amorcer les invites TTS clonées par la voix. Carte du modèle : Qwen/Qwen3-ASR-1.7B.
- MelBandRoFormer pour la séparation vocale. Utile lorsque vous avez besoin de pistes vocales propres avant l'intégration de la synchronisation labiale. Carte du modèle : Kijai/MelBandRoFormer_comfy.
- MiniCPM-V pour la génération d'invites conscientes des plans. Il analyse les séquences précédentes et propose le plan suivant pour la continuité de l'histoire. Hub de modèle : OpenBMB/MiniCPM-V.
Comment utiliser le workflow Comfyui SkyReels V3 ComfyUI#
Le graphique est organisé en quatre pipelines. Vous pouvez en exécuter un seul ou en séquence pour créer des montages plus longs.
Animation de personnage d'image à vidéo#
- Modèles. Chargez le UNet, CLIP, et VAE dans le groupe Modèles en utilisant
UNETLoader(#241),CLIPLoader(#242), etVAELoader(#194). Les nœuds de patch modèlePathchSageAttentionKJ(#240) etModelPatchTorchSettings(#239) optimisent les paramètres d'attention et de mathématiques, tandis queLoraLoaderModelOnly(#250) vous permet de mélanger facultativement un style ou un mouvement LoRA dans le modèle SkyReels. - Charger des images de référence. Utilisez les trois groupes "Charger des images de référence" pour importer 1 à 3 portraits ou poses. Les aides au redimensionnement
ImageResizeKJv2(#291, #298, #299, #304) alignent le ratio d'aspect et les regroupent ; des photos d'identité plus propres donnent des résultats plus stables. - Invite. Entrez le texte de scène et d'action dans le groupe Invite avec
CLIPTextEncode(#6) et un encodeur de texte négatif optionnelCLIPTextEncode(#7) pour éloigner les traits indésirables. Gardez le langage concis et spécifique au mouvement et au cadrage. - Échantillonnage et décodage.
WanPhantomSubjectToVideo(#249) fusionne vos références et invites en un latent conscient de l'identité qui alimenteKSampler(#149) viaModelSamplingSD3(#48). Les images décodées deVAEDecode(#264) sont emballées dans un film avecVHS_VideoCombine(#280) ; définissez votre taux de trame cible et le format de fichier là-bas.
Boucle d'extension de vidéo à vidéo#
- Vidéo d'entrée et paramètres. Apportez votre clip source avec
VHS_LoadVideo(#329). Définissez combien de segments supplémentaires générer et combien de chevauchement entre les segments en utilisant les aides entières "Nombre d'Extension" (#342) et "Images Chevauchantes" (#341).ImageResizeKJv2(#327) standardise la résolution pour l'échantillonneur. - Boucle d'échantillonnage vidéo d'extension. La paire de boucles
easy forLoopStart(#331) eteasy forLoopEnd(#332) parcourt le clip dans des fenêtres pour stabiliser les transitions. Chaque fenêtre est encodée avecWanVideoEncode(#326), reçoit des intégrations neutres ou de contrôle viaWanVideoEmptyEmbeds(#328), et est débruitée parWanVideoSampler(#320) deWanVideoModelLoader(#319). Les images sont décodées avecWanVideoDecode(#321) et prévisualisées ou enregistrées avecVHS_VideoCombine(#322, #335). - Aides à la performance.
WanVideoTorchCompileSettings(#323) etWanVideoBlockSwap(#325) activent des astuces de compilation et de mémoire pour des exécutions plus longues ou plus haute résolution.
Avatar parlant d'audio à vidéo#
- 1 – Créer de l'audio. Vous pouvez générer une piste de parole clonée par la voix avec
FB_Qwen3TTSVoiceClonePrompt(#416) etFB_Qwen3TTSVoiceClone(#412), ou charger toute voix préenregistrée avecLoadAudio(#417).Qwen3ASRLoader(#414) etQwen3ASRTranscribe(#413) vous aident à extraire du texte à partir d'un clip de référence pour amorcer l'invite TTS si désiré. - 2 – Fonctionnalités audio.
DownloadAndLoadWav2VecModel(#348) alimenteMultiTalkWav2VecEmbeds(#350) pour créer des intégrations de mouvement labial à partir de votre discours ; la longueur est alignée sur l'audio et prévisualisable avecPreviewAudio(#422). UtilisezAny Switch (rgthree)(#435) pour choisir la sortie TTS ou votre fichier importé comme piste de conduite. - 3 – Image d'entrée. Chargez le visage parlant dans le groupe "3 - Image d'entrée" et dimensionnez-le avec
ImageResizeKJv2(#370). Les portraits propres, de face avec un éclairage cohérent fonctionnent le mieux. - Génération de vidéo de référence. Tout d'abord, créez une courte ancre visuelle à partir de l'image fixe en utilisant
WanVideoImageToVideoEncode(#392). Les fonctionnalités CLIP-Vision deCLIPVisionLoader(#352) etWanVideoClipVisionEncode(#351) stabilisent l'identité à travers l'étape suivante ; un planificateurWanVideoSchedulerv2(#385) est préparé dans le groupe Paramètre d'échantillonnage. - Générer la synchronisation labiale audio.
WanVideoImageToVideoSkyreelsv3_audio(#383) combine l'image de départ, les images de référence optionnelles et les intégrations CLIP-Vision en conditionnement d'image.WanVideoSamplerv2(#384) débruite ensuite avec le modèle SkyReels A2V tandis queWanVideoSamplerExtraArgs(#386) injecte les intégrations de synchronisation labialeMultiTalkpour des formes de bouche précises.WanVideoPassImagesFromSamples(#381) diffuse les images décodées àVHS_VideoCombine(#346) où la vidéo finale est multiplexée avec votre audio.
Génération de plan suivant de vidéo à vidéo#
- Prétraitement des images vidéo. Importez le plan précédent avec
VHS_LoadVideo(#443) et redimensionnez-le viaImageResizeKJv2(#441).GetImageRangeFromBatch(#445) sélectionne une tranche de contexte queWanVideoEncode(#440) transforme en latents ;WanVideoEmptyEmbeds(#442) prépare la fenêtre de conditionnement. - Invite vidéo automatique.
CreateVideo(#450) assemble un clip proxy compact à partir des images de contexte queAILab_MiniCPM_V_Advanced(#449) analyse pour rédiger une invite de plan suivant. Inspectez ou affinez le brouillon dansShowText|pysssss(#447) et intégrez-le avecWanVideoTextEncodeCached(#444) avant l'échantillonnage. - Modèles et échantillonnage. Chargez le modèle V2V Shot avec
WanVideoModelLoader(#436) etWanVideoVAELoader(#438) ;WanVideoBlockSwap(#439) gère facultativement la VRAM. LeWanVideoSampler(#451) génère la continuation,WanVideoDecode(#437) rend les images, etVHS_VideoCombine(#446) produit le plan final. Ce chemin SkyReels V3 ComfyUI est idéal pour les storyboards et les prévisualisations où chaque nouvelle coupe doit respecter la précédente.
Nœuds clés dans le workflow Comfyui SkyReels V3 ComfyUI#
WanPhantomSubjectToVideo(#249). Construit un latent conscient de l'identité à partir de vos images de référence groupées plus des invites textuelles, qui pilotent ensuite l'échantillonneur. Ajustez le nombre et la diversité des références pour équilibrer le verrouillage de la ressemblance contre le mouvement créatif ; gardez les nœuds de redimensionnement qui l'alimentent cohérents pour éviter la dérive. Référence : WanVideo Wrapper sur GitHub contient des notes d'implémentation et des entrées attendues ComfyUI-WanVideoWrapper.WanVideoImageToVideoEncode(#392). Encode une image fixe en une graine de plan stable et mélange facultativement l'orientation CLIP-Vision pour la pose et le cadrage. Utilisez-le pour créer des images d'ancrage avant l'étape pilotée par audio afin que l'identité et la configuration de la caméra restent cohérentes à travers les pipelines. Docs Wrapper : ComfyUI-WanVideoWrapper.WanVideoImageToVideoSkyreelsv3_audio(#383). Prépare des intégrations d'image adaptées à l'échantillonneur A2V et fusionne des images vidéo de référence optionnelles. Assurez-vous que sa largeur et sa hauteur correspondent au chemin de l'échantillonneur ; associez-le àWanVideoSamplerv2etMultiTalkWav2VecEmbedspour une synchronisation labiale précise.WanVideoSamplerv2(#384, #387). Le principal débruiteur pour SkyReels V3 qui accepte des intégrations d'image et de texte ainsi que des paramètres de planificateur. Les nœudsWanVideoSamplerExtraArgs(#386, #409) sont là où la synchronisation labiale, la boucle ou les fonctionnalités de contexte sont injectées ; gardez-les connectés lors du passage entre les modèles A2V et I2V. Détails de l'implémentation : ComfyUI-WanVideoWrapper.MultiTalkWav2VecEmbeds(#350). Convertit la parole en intégrations alignées temporellement qui pilotent le mouvement de la bouche. Correspondre au budget d'images prévu et garantir des voix propres améliore considérablement la précision des phonèmes. Modèle de référence Wav2Vec : TencentGameMate/chinese-wav2vec2-base.AILab_MiniCPM_V_Advanced(#449). Analyse le plan précédent et rédige une invite structurée pour le personnage, l'arrière-plan, l'action, l'humeur et l'éclairage. Utilisez-le pour maintenir la continuité narrative lors de l'utilisation du chemin V2V suivant ; le texte résultant s'écoule dansWanVideoTextEncodeCached. Famille de modèles : OpenBMB/MiniCPM-V.
Extras optionnels#
- Gardez les résolutions d'image, de vidéo et d'échantillonneur cohérentes à travers les nœuds connectés pour éviter les déformations d'aspect et les scintillements d'identité.
- Pour des extensions plus longues, augmentez le chevauchement des fenêtres dans la boucle d'extension V2V pour lisser les transitions entre les segments.
- Si la mémoire GPU est limitée, laissez les nœuds de VRAM réservée (
ReservedVRAMSetter(#312, #448)) activés et utilisez les blocs de paramètres de compilation avant l'échantillonnage. - Lorsque les avatars parlants se décalent, privilégiez des discours clairs ou séparez les voix avec MelBandRoFormer avant de créer les intégrations
MultiTalk. - Les paramètres de livraison finaux tels que la fréquence d'images, le format pix et le CRF sont contrôlés dans les nœuds de sortie
VHS_VideoCombine; faites correspondre la fréquence d'images à votre source pour des montages homogènes.
Ce README couvre le graphique complet SkyReels V3 ComfyUI afin que vous puissiez choisir le chemin qui convient à votre projet, les combiner si nécessaire, et rendre des vidéos prêtes à l'histoire avec un minimum d'essais et d'erreurs.
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous reconnaissons avec gratitude @Benji’s AI Playground et SkyReels pour le workflow SkyReels V3 ComfyUI pour leurs contributions et maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- SkyReels/V3 ComfyUI Source
- Docs / Notes de version : SkyReels V3 ComfyUI Source from @Benji’s AI Playground
Note : L'utilisation des modèles, ensembles de données et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.