
Inférence Qwen Image 2512 LoRA : générations AI Toolkit alignées sur le pipeline et correspondant à l'entraînement dans ComfyUI#
Ce workflow prêt pour la production RunComfy applique un LoRA formé par AI Toolkit à Qwen Image 2512 dans ComfyUI avec un accent sur le comportement correspondant à l'entraînement. Il se concentre sur RC Qwen Image 2512 (RCQwenImage2512)—un nœud personnalisé open-source construit par RunComfy (source) qui exécute un pipeline d'inférence natif Qwen (au lieu d'un graphe d'échantillonneur générique) et charge votre adaptateur via lora_path et lora_scale.
Pourquoi l'inférence Qwen Image 2512 LoRA semble souvent différente dans ComfyUI#
Les aperçus AI Toolkit pour Qwen Image 2512 sont produits par un pipeline spécifique au modèle, y compris le comportement de guidage "true CFG" de Qwen et les paramètres par défaut que ce pipeline utilise pour le conditionnement et l'échantillonnage. Si vous reconstruisez le même travail comme un graphe d'échantillonneur ComfyUI standard, les sémantiques de guidage et le point de patch LoRA peuvent changer—donc "même prompt + même seed + mêmes étapes" peuvent toujours donner un résultat différent. En pratique, de nombreux rapports "mon LoRA ne correspond pas à l'entraînement" sont des discordances de pipeline, pas un paramètre manquant.
RCQwenImage2512 garde l'inférence alignée en enveloppant le pipeline Qwen Image 2512 à l'intérieur du nœud et en appliquant le LoRA dans ce pipeline via lora_path et lora_scale. Source du pipeline : `src/pipelines/qwen_image.py`.
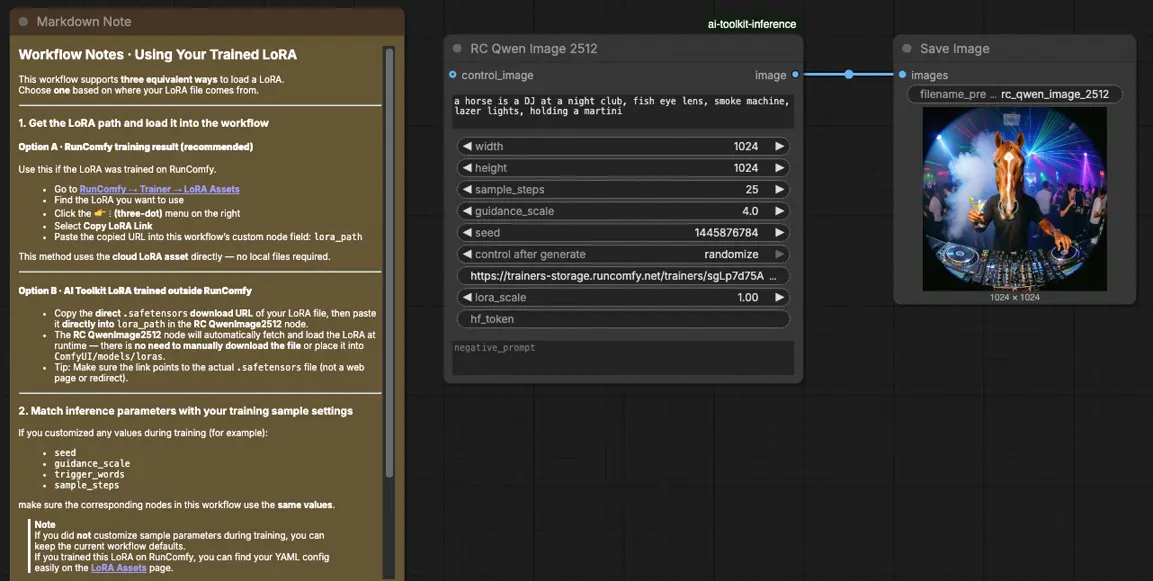
Comment utiliser le workflow d'inférence Qwen Image 2512 LoRA#
Étape 1 : Ouvrir le workflow#
Lancez le workflow cloud dans ComfyUI.
Étape 2 : Importer votre LoRA (2 options)#
- Option A (résultat d'entraînement RunComfy) : RunComfy → Trainer → LoRA Assets → trouvez votre LoRA → ⋮ → Copier le lien LoRA

- Option B (LoRA formé par AI Toolkit en dehors de RunComfy) : Copiez un lien de téléchargement direct
.safetensorspour votre LoRA et collez cette URL danslora_path(pas besoin de télécharger dansComfyUI/models/loras)
Étape 3 : Configurer le nœud personnalisé RCQwenImage2512 pour l'inférence Qwen Image 2512 LoRA#
Collez votre lien LoRA dans lora_path sur RC Qwen Image 2512 (RCQwenImage2512).

Ensuite, réglez les paramètres restants du nœud (commencez par correspondre aux valeurs que vous avez utilisées pour la génération d'aperçu/échantillon pendant l'entraînement) :
prompt: votre prompt positif (incluez tous les tokens déclencheurs que votre LoRA attend)negative_prompt: optionnel ; laissez vide si vous n'avez pas utilisé de négatifs dans vos aperçuswidth/height: résolution de sortie (les multiples de 32 sont recommandés pour cette famille de pipelines)sample_steps: étapes d'inférence ; reflétez votre nombre d'étapes d'aperçu avant d'ajuster (25 est une base commune)guidance_scale: force du guidage (Qwen utilise une échelle "true CFG", donc réutilisez d'abord votre valeur d'aperçu)seed: verrouillez le seed pendant que vous validez l'alignement en réglant le control_after_generate sur 'fixed', puis variez-le pour de nouveaux échantillonslora_scale: force du LoRA ; commencez près de votre valeur d'aperçu et ajustez par petites incréments
C'est un workflow texte-vers-image, donc vous n'avez pas besoin de fournir une image d'entrée.
Note d'alignement de l'entraînement : si vous avez personnalisé l'échantillonnage pendant l'entraînement, ouvrez votre YAML d'entraînement AI Toolkit et reflétez width, height, sample_steps, guidance_scale, seed, et lora_scale. Si vous vous êtes entraîné sur RunComfy, ouvrez Trainer → LoRA Assets → Config et copiez les valeurs d'aperçu/échantillon dans RCQwenImage2512 avant de continuer.

Étape 4 : Exécuter l'inférence Qwen Image 2512 LoRA#
Cliquez sur Queue/Run. Le nœud SaveImage enregistre l'image générée dans votre dossier de sortie standard ComfyUI.
Dépannage de l'inférence Qwen Image 2512 LoRA#
Le nœud personnalisé RC Qwen Image 2512 (RCQwenImage2512) de RunComfy est conçu pour maintenir l'inférence alignée sur le pipeline avec l'échantillonnage de style aperçu de Qwen Image 2512 en :
- exécutant un pipeline d'inférence natif Qwen à l'intérieur du nœud (pas un graphe d'échantillonneur générique), et
- injectant le LoRA via
lora_path+lora_scaleà l'intérieur de ce pipeline (point de patch cohérent).
(1)Les LoRAs Qwen-Image ne fonctionnent pas dans comfyui#
Pourquoi cela se produit
Les utilisateurs ont signalé que les LoRAs Qwen-Image formés par AI Toolkit peuvent échouer à s'appliquer dans ComfyUI car les préfixes de clé du dictionnaire d'état LoRA ne correspondent pas à ce que le chemin de chargement/inférence côté ComfyUI attend (donc l'adaptateur se charge "silencieusement" mais ne patch pas réellement les modules du transformateur Qwen).
Comment réparer (options vérifiées par les utilisateurs)
- Utilisez RCQwenImage2512 pour l'injection LoRA au niveau du pipeline : chargez l'adaptateur uniquement via
lora_path+lora_scalesur RCQwenImage2512 (évitez d'empiler des nœuds de chargeur LoRA supplémentaires par-dessus lors du débogage). Cela maintient le point de patch LoRA aligné avec le pipeline Qwen utilisé par l'échantillonnage de style aperçu. - Si vous devez utiliser un fournisseur d'inférence / chemin de chargement non-RC : une solution rapportée par les utilisateurs est de renommer les clés LoRA en remplaçant le premier segment du préfixe de clé LoRA de
diffusion_model→transformer, afin que les poids se mappent sur les modules du transformateur Qwen attendus (voir le problème pour le contexte exact et pourquoi cela est nécessaire).
(2)Patch pour crash lors de l'utilisation de inference_lora_path avec qwen image (permet de générer des échantillons avec turbo lora)#
Pourquoi cela se produit
Certains utilisateurs rencontrent un crash lorsqu'ils essaient de charger un LoRA d'inférence pour Qwen (y compris Qwen-Image-2512) via le flux inference_lora_path d'AI Toolkit. Ce n'est pas un problème de "prompt/CFG/seed"—c'est un problème de chemin de chargement d'inférence.
Comment réparer (vérifié par les utilisateurs)
- Appliquez le patch / mettez à jour vers une version qui inclut le patch décrit dans le problème. L'auteur du problème rapporte que le patch corrige le crash lors du chargement d'un LoRA d'inférence pour Qwen (voir le problème pour le changement exact et le contexte de configuration).
- Pour l'inférence ComfyUI spécifiquement : préférez RCQwenImage2512 et chargez l'adaptateur via
lora_path/lora_scaleà l'intérieur du nœud RC. Cela évite de s'appuyer sur des chemins de chargement de LoRA d'inférence externes et maintient le pipeline cohérent avec l'échantillonnage de style aperçu.
(3)utiliser sageattention 2 qwen-image dans comfyui montre des images noires en raison de NaNs (c'est-à-dire des images noires)#
Pourquoi cela se produit
Les utilisateurs ont signalé que l'exécution de Qwen Image dans ComfyUI avec SageAttention peut produire des NaNs qui se transforment en images noires. Cela peut ressembler à "mon LoRA est cassé", mais c'est en fait le backend d'attention qui produit des valeurs invalides—l'exécution du pipeline échoue avant que vous puissiez évaluer de manière significative le comportement LoRA.
Comment réparer (vérifié par les utilisateurs)
- N'utilisez pas
--use-sage-attentionpour Qwen Image lorsque cela cause des NaNs/images noires. Validez d'abord une base propre (sorties non noires), puis évaluez l'impact LoRA. - Si vous avez besoin d'accélérations SageAttention : corrigez la sortie noire de Qwen en forçant un chemin de backend CUDA. En pratique, cela signifie souvent utiliser un patch au niveau du workflow (par exemple, un nœud "Patch Sage Attention") et sélectionner une variante de backend CUDA qui évite le chemin Triton cassé pour le GPU/architecture affecté.
- Après avoir des sorties de base stables (non noires), exécutez l'inférence Qwen Image 2512 via RCQwenImage2512 afin que le pipeline + le point d'injection LoRA reste aligné sur l'aperçu pendant que vous correspondez
width/height/sample_steps/guidance_scale/seed/lora_scale.
Exécutez maintenant l'inférence Qwen Image 2512 LoRA#
Ouvrez le workflow partagé, collez votre URL LoRA dans lora_path, correspondez à vos valeurs d'échantillonnage d'aperçu, et exécutez RCQwenImage2512 pour des générations Qwen Image 2512 correspondant à l'entraînement dans ComfyUI.