
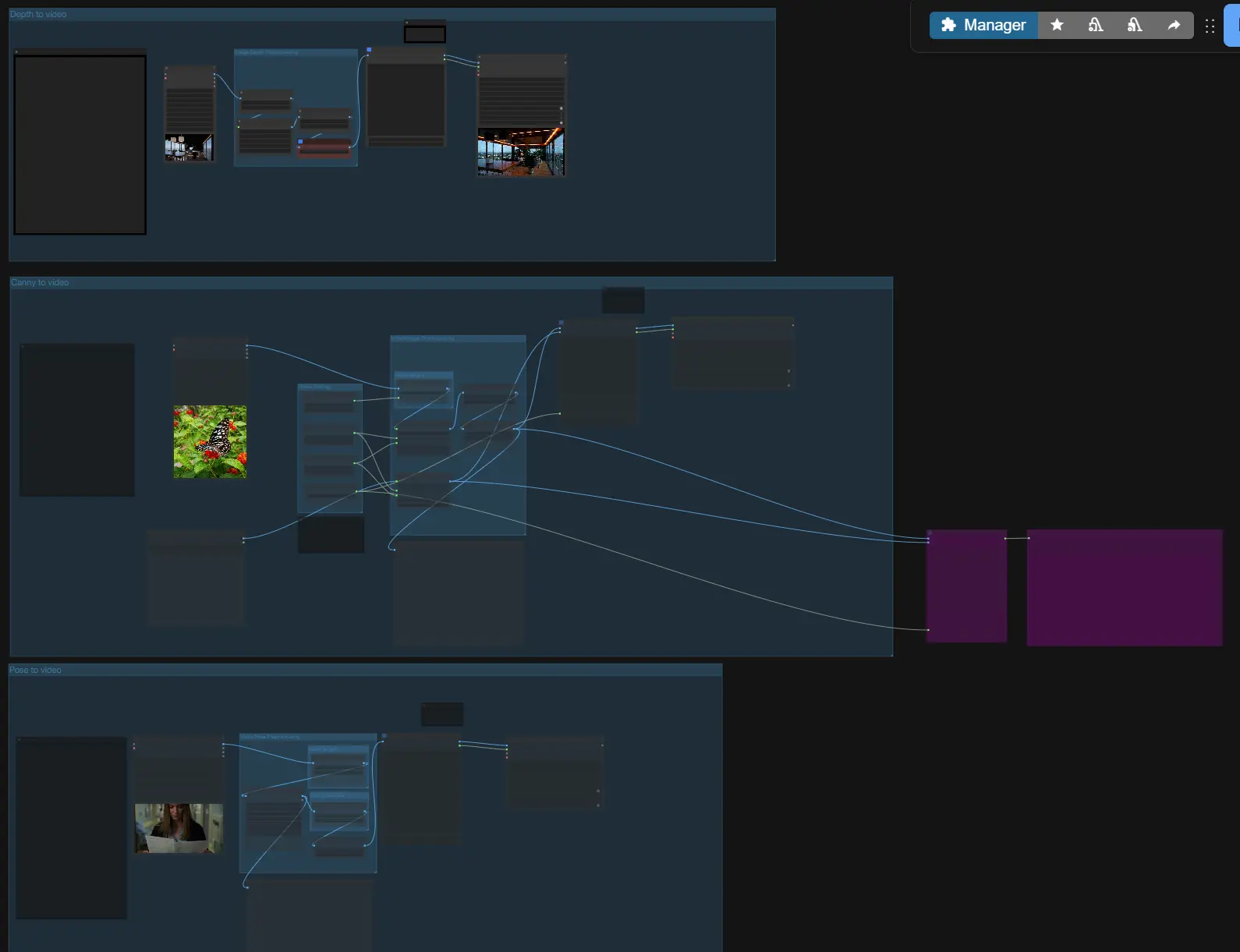
LTX-2 ControlNet : génération vidéo guidée par la structure et synchronisée audio dans ComfyUI#
LTX-2 ControlNet est un flux de travail ComfyUI piloté par le contrôle pour l'extension ComfyUI-LTXVideo qui vous permet de diriger la génération de vidéos LTX-2 avec une guidance de profondeur, de contours canny et de poses tout en gardant l'audio et les visuels synchronisés. Il fonctionne dans un espace latent audio-visuel unifié, de sorte que le discours, le foley et le mouvement sont générés ensemble et restent alignés du premier au dernier cadre.
Conçu pour le texte-à-vidéo, l'image-à-vidéo et le vidéo-à-vidéo, le flux de travail ajoute un conditionnement ControlNet basé sur IC LoRA pour un contrôle précis de la disposition et du mouvement, une initialisation du premier cadre pour la continuité de la scène, et un pipeline en deux étapes avec mise à l'échelle latente pour des résultats nets sans exploser la VRAM. LTX-2 ControlNet est entièrement ouvert, rapide à itérer, et orienté vers la production pour les créateurs qui ont besoin de sorties répétables et de haute qualité.
Modèles clés dans le flux de travail Comfyui LTX-2 ControlNet#
- LTX-2 19B (dev FP8 et distillé). Modèle génératif audio-visuel principal utilisé pour l'échantillonnage vidéo et audio dans un espace latent unique. Famille de modèles
- Gemma 3 12B IT encodeur de texte. Fournit une compréhension linguistique robuste pour les invites et les négatifs via l'encodeur intégré utilisé par LTX-2. Fichier d'encodeur
- LTX-2 Spatial Upscaler x2. Modèle de mise à l'échelle latente utilisé en deuxième étape pour affiner le détail spatial. Upscaler
- LTX-2 Audio VAE. Décodeur-encodeur audio spécialisé qui garde le son généré aligné avec les cadres. Inclus avec les checkpoints LTX-2. Checkpoints
- Famille de contrôle IC LoRA pour LTX-2. Ajoute un conditionnement de style ControlNet :
- Contrôle de profondeur LoRA : ltx-2-19b-IC-LoRA-Depth-Control
- Contrôle de contours Canny LoRA : ltx-2-19b-IC-LoRA-Canny-Control
- Contrôle de pose LoRA : ltx-2-19b-IC-LoRA-Pose-Control
- LoRA distillé pour des compromis qualité/efficacité : ltx-2-19b-distilled-lora-384
- Lotus Depth D v1.1. Estimateur de profondeur utilisé dans le chemin de contrôle de profondeur. Modèle
- SD VAE FT MSE (Stability AI). VAE d'image utilisé pour le pré-calcul de profondeur et le décodage par tuiles. VAE
- Extension ComfyUI-LTXVideo. Fournit les échantillonneurs LTX-2, les latents AV, le VAE audio et les nœuds de guidage utilisés tout au long. Dépôt
Comment utiliser le flux de travail Comfyui LTX-2 ControlNet#
À un niveau élevé, LTX-2 ControlNet prend votre invite et des références optionnelles, construit un latent audio-visuel avec une guidance de style ControlNet, échantillonne un premier passage, puis met à l'échelle le latent pour une vidéo nette et un audio synchronisé. Choisissez l'un des trois chemins guidés (Profondeur, Canny, Pose) ou utilisez-les indépendamment, puis définissez la longueur et la taille avant d'exporter.
- Prétraitement Image/Vidéo
- Si vous faites de l'image-à-vidéo ou du vidéo-à-vidéo, utilisez les chargeurs pour importer vos médias de référence.
VHS_LoadVideo(#196, #197, #198) divise les cadres pour l'analyse, tandis queLoadImage(#189) gère les images fixes. Le groupe offre un redimensionnement pratique pour que les guides en aval voient des tailles de cadre cohérentes. - Une image du "premier cadre" peut être transmise pour l'initialisation de la scène ; vous l'activerez plus tard dans le groupe de génération.
- Si vous faites de l'image-à-vidéo ou du vidéo-à-vidéo, utilisez les chargeurs pour importer vos médias de référence.
- Prétraitement de la Profondeur d'Image
- Pour la guidance de profondeur, le sous-graphe "Image to Depth Map (Lotus)" convertit votre entrée en une carte de profondeur normalisée en utilisant Lotus Depth. Cela prépare une représentation de profondeur à un ou plusieurs cadres que LTX-2 peut suivre.
- Le chemin inclut un redimensionnement optionnel et des contrôles d'intensité pour que le guide encode une structure large sans surajustement aux petits artefacts.
- Prétraitement de la Pose Vidéo
- Pour la guidance de pose,
DWPreprocessor(#158) détecte les points clés du corps entier à partir de la vidéo d'entrée et les met à l'échelle pour un conditionnement stable. Cela donne une séquence d'images de pose propre qui met l'accent sur l'orientation du squelette et des membres. - Les nœuds de prévisualisation vous aident à vérifier rapidement que les détections et les ratios d'aspect semblent corrects avant la génération.
- Pour la guidance de pose,
- Contours Canny vers vidéo
- Ce chemin de contrôle extrait les contours avec
Canny(#169), puis construit un latent AV avec la séquence d'images de contrôle. Utilisez-le lorsque vous souhaitez préserver les silhouettes, les contours majeurs ou les bords de typographie d'une référence. - Une entrée d'image de premier cadre est disponible pour une initialisation cohérente ; activez-la uniquement lorsque vous souhaitez que le cadre d'ouverture corresponde à une image fixe spécifique.
- Ce chemin de contrôle extrait les contours avec
- Profondeur vers vidéo
- Ce chemin alimente les cartes de profondeur Lotus comme images de contrôle. Le contrôle de profondeur est idéal pour appliquer la géométrie de la caméra, la disposition à grande échelle et la distance du sujet tout en laissant le générateur choisir les textures et l'éclairage.
- Vous pouvez fournir un premier cadre pour bloquer la composition initiale et laisser le mouvement évoluer guidé par les indices de profondeur.
- Pose vers vidéo
- Le chemin de la pose utilise le rendu des points clés du préprocesseur, guidant l'orientation du corps et le timing du mouvement. Il est particulièrement efficace pour le blocage des personnages, le timing de levée de main et les cycles de marche.
- Comme avec d'autres modes, vous pouvez combiner le timing des invites avec un conditionnement optionnel du premier cadre pour la continuité.
- Paramètres vidéo et longueur
- Définissez la largeur, la hauteur et le nombre de cadres de travail dans les groupes "Paramètres Vidéo" et "longueur vidéo". Le flux de travail ajuste automatiquement les valeurs invalides aux tailles compatibles les plus proches pour la grille et la foulée latentes de LTX-2 afin que vous puissiez itérer en toute sécurité.
- Gardez votre fréquence d'images cible cohérente à travers les nœuds ; les nœuds de conditionnement et le mux final respectent cela pour une synchronisation audio-visuelle fluide.
- Génération, mise à l'échelle et exportation
- Pendant l'échantillonnage,
LTXVAddGuideintègre votre conditionnement positif/négatif avec les images de contrôle choisies, puisSamplerCustomAdvancedexécute le programme deLTXVSchedulerpour les latents vidéo et audio. Le premier cadre optionnel est injecté avecLTXVImgToVideoInplaceoù activé. - La deuxième étape exécute
LTXVLatentUpsamplerpour affiner le détail avec le x2 latent upscaler. Le décodage final se fait avec leVAEDecodeTiledpour les cadres etLTXVAudioVAEDecodepour l'audio, puis la vidéo est écrite avecVHS_VideoCombineouCreateVideoselon la branche sélectionnée.
- Pendant l'échantillonnage,
Nœuds clés dans le flux de travail Comfyui LTX-2 ControlNet#
LTXVAddGuide(#132)- Fusionne le conditionnement de texte et les contrôles IC LoRA dans le latent AV, agissant comme le cœur de la guidance ControlNet LTX-2. Ajustez seulement les quelques contrôles qui comptent : choisissez le LoRA de contrôle qui correspond à votre chemin (profondeur, canny ou pose) et, lorsque disponible, la
image_strengthqui ajuste la façon dont le modèle suit les guides. L'implémentation de référence et le comportement du nœud sont fournis par l'extension LTXVideo. Docs/Code
- Fusionne le conditionnement de texte et les contrôles IC LoRA dans le latent AV, agissant comme le cœur de la guidance ControlNet LTX-2. Ajustez seulement les quelques contrôles qui comptent : choisissez le LoRA de contrôle qui correspond à votre chemin (profondeur, canny ou pose) et, lorsque disponible, la
LTXVImgToVideoInplace(#149, #155)- Injecte une image de premier cadre dans le latent AV pour une initialisation de scène cohérente. Utilisez
strengthpour équilibrer la fidélité au premier cadre par rapport à la liberté d'évolution ; gardez-le bas pour plus de mouvement et élevé pour des ancres plus serrées. Ignorez-le lorsque vous voulez des ouvertures purement textuelles ou guidées par le contrôle. Docs/Code
- Injecte une image de premier cadre dans le latent AV pour une initialisation de scène cohérente. Utilisez
LTXVScheduler(#95)- Conduit la trajectoire de débruitage pour le latent unifié afin que l'audio et la vidéo convergent ensemble. Augmentez les étapes pour des scènes complexes et des détails fins ; raccourcissez pour des brouillons et des itérations rapides. Les paramètres du programme interagissent avec la force de la guidance, évitez donc les valeurs extrêmes lorsque la guidance est forte. Docs/Code
LTXVLatentUpsampler(#112)- Effectue la mise à l'échelle latente de deuxième étape avec le spatial upscaler x2 de LTX-2, améliorant la netteté avec une croissance minimale de la VRAM. Utilisez-le après le premier passage plutôt qu'en augmentant la résolution de base pour garder les itérations réactives. Modèle d'upscaler
DWPreprocessor(#158)- Génère des points clés de pose humaine propres pour le chemin de contrôle de pose. Vérifiez les détections avec l'aperçu ; si les mains ou les petits membres sont bruyants, mettez à l'échelle les entrées à une dimension maximale modérée avant le prétraitement. Fourni par la suite auxiliaire ControlNet. Repo
VHS_VideoCombine/CreateVideo(#195, #106)- Mux des cadres décodés et de l'audio dans un MP4 avec la fréquence d'images et le format de pixel sélectionnés. Utilisez-les uniquement après avoir confirmé que votre décodage audio semble aligné dans l'aperçu. Fourni par la Suite d'Aide Vidéo. Repo
Extras optionnels#
- Incitation pour LTX-2 ControlNet
- Décrivez des actions au fil du temps, pas seulement des attributs statiques.
- Incluez les indices sonores ou dialogues nécessaires pour que l'audio soit généré en rythme.
- Utilisez une invite négative concise pour supprimer les artefacts que vous voyez de manière répétée.
- Dimensions et longueurs
- Utilisez des tailles d'image de la forme 32k + 1 pour la largeur/hauteur ; le graphe corrige automatiquement si vous manquez, mais les valeurs exactes accélèrent l'itération.
- Les comptes de cadres de la forme 8k + 1 tendent à être les plus stables pour la planification.
- Cohérence du premier cadre
- Activez le premier cadre uniquement lorsque vous avez besoin d'une composition d'ouverture verrouillée ; associez-le à une
image_strengthmodérée pour éviter une contrainte excessive.
- Activez le premier cadre uniquement lorsque vous avez besoin d'une composition d'ouverture verrouillée ; associez-le à une
- VRAM et débit
- Le flux de travail inclut des options de séquence-parallèle et de compilation torch dans le patcher LTXVideo pour des configurations multi-GPU ou à mémoire restreinte. Gardez-les activées pour les clips longs, désactivez-les lors du débogage du comportement des nœuds. Extension
Remerciements#
Ce flux de travail implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Lightricks pour ComfyUI-LTXVideo pour leurs contributions et leur maintenance. Pour des détails faisant autorité, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Dépôt GitHub ComfyUI-LTXVideo : https://github.com/Lightricks/ComfyUI-LTXVideo
- GitHub : Lightricks/ComfyUI-LTXVideo
Remarque : L'utilisation des modèles, ensembles de données et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.
