
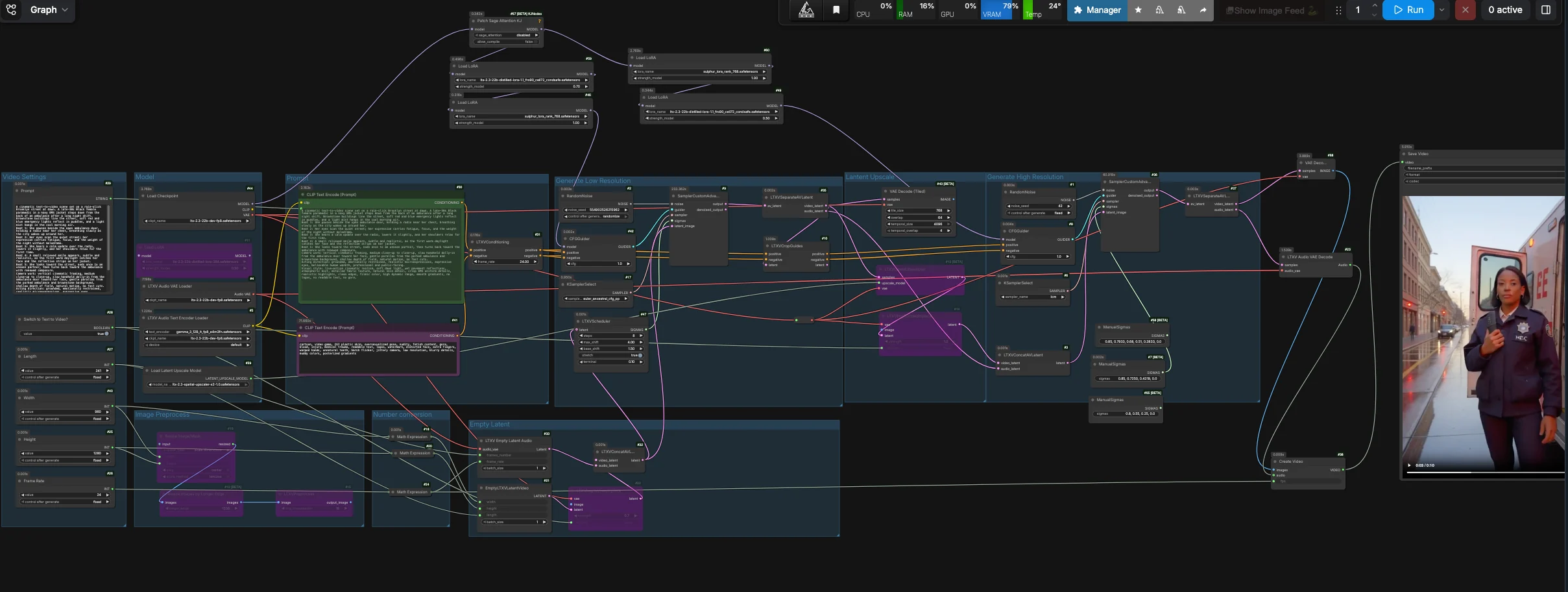
LTX 2.3 Sulphur T2V workflow : prompt-à-cinéma avec microexpressions, ambiance et caméra guidée#
Le workflow LTX 2.3 Sulphur T2V transforme des prompts bien écrits en clips cinématographiques qui mettent l'accent sur des microexpressions crédibles, des détails de scène atmosphériques et un mouvement basé sur l'histoire. Il combine un passage de génération distillé LTX 2.3 avec une orientation de style Sulphur, une orientation de contrôle de caméra optionnelle, et un chemin de décodage en mosaïque stable pour des résultats texte-à-vidéo fiables.
Conçu pour les créateurs qui souhaitent des scènes d'action ancrées et un mouvement de caméra contrôlable, cette configuration ComfyUI équilibre la fidélité narrative avec la stabilité temporelle. Vous pouvez exécuter un pur texte-à-vidéo ou commencer à partir d'une image fixe, puis décoder le latent de premier passage stable en une séquence propre et conviviale pour l'édition avec une piste audio de remplacement pour un montage facile.
Modèles clés dans le workflow Comfyui LTX 2.3 Sulphur T2V#
- Lightricks LTX‑2.3 22B FP8 checkpoint. Le modèle de base texte-à-vidéo alimentant la génération et le décodage. Dépôt du modèle
- LTX‑2.3 distillé LoRA. Un adaptateur distillé qui maintient la qualité tout en permettant un échantillonnage plus rapide et à moindre pas et un mouvement stable. Famille de modèles
- LTX‑2.3 spatial upscaler x2. Inclus dans le graphique pour l'expérimentation, tandis que le chemin d'exportation par défaut utilise le décodage de premier passage stable pour des résultats plus propres sur cette configuration. Upscaler
- LTX‑2 19B LoRA Camera Control Dolly Left. Orientation optionnelle pour un mouvement de dolly-in stable et un léger parallaxe lorsque votre scène l'exige. LoRA
- LTX text encoder (Gemma 3 12B variants). Le modèle de tokenisation et d'encodage qui interprète votre prompt et vos notes de rythme. Encodeurs de texte
- LTX audio VAE. Emballe un flux audio silencieux pour que la vidéo résultante se charge proprement dans les NLEs. Dépôt du modèle
- Sulphur LoRA (inclus). Un adaptateur de style et de rythme d'action conçu pour des microexpressions expressives mais retenues et une harmonie de couleurs cinématographique.
Comment utiliser le workflow Comfyui LTX 2.3 Sulphur T2V#
Ce workflow par défaut suit un chemin texte-à-vidéo de premier passage stable. Il génère un latent vidéo cohérent, sépare les pistes vidéo et audio, décode le latent vidéo de premier passage avec un décodage VAE en mosaïque, puis emballe les images et l'audio silencieux dans un fichier vidéo prêt à éditer. Les nœuds de mise à l'échelle et de raffinement latents restent dans le graphique pour une expérimentation avancée, mais la sortie par défaut contourne cette branche pour plus de fiabilité.
Modèle#
Le groupe Modèle charge le checkpoint LTX‑2.3 FP8, l'encodeur de texte LTX, le VAE audio et les adaptateurs utilisés tout au long. Les LoRAs distillés et Sulphur sont appliqués au modèle de base pour que la scène adhère étroitement à vos rythmes et à votre intention faciale. Si vous souhaitez un mouvement de dolly, activez le LoRA de contrôle de caméra dans les nœuds LoraLoader fournis. Le chemin par défaut alimente l'échantillonneur principal via CFGGuider (#42), tandis que la branche de raffinement est gardée disponible pour une expérimentation manuelle.
Prompt#
Écrivez votre scène dans le champ Prompt (#29) sous forme de lignes de rythme courtes plus de brèves notes de caméra. Le texte positif est encodé par CLIPTextEncode (#30), tandis qu'une liste négative organisée dans CLIPTextEncode (#41) supprime l'apparence CGI, les artefacts, le scintillement et les scintillements durs. Gardez la direction de l'action concise et spécifique aux yeux, aux épaules et à la respiration pour débloquer les microexpressions pour lesquelles ce workflow est optimisé. Un langage de caméra comme "dolly-in lent" et "parallaxe douce" se mappe bien au programmateur et au LoRA de caméra optionnel.
Paramètres Vidéo#
Choisissez la sortie Width, Height, Frame Rate, et Length dans le groupe Paramètres Vidéo (#40, #25, #26, #27). En interne, le workflow dérive un latent à demi-résolution pour le passage de génération afin d'améliorer la cohérence temporelle, puis décode directement ce latent stable. Utilisez Switch to Text to Video? (#28) pour exécuter un pur T2V, ou désactivez-le et alimentez une image de départ via le chemin de prétraitement d'image pour un I2V contrôlé. Les dimensions doivent rester des multiples communs pour un décodage rapide et compatible avec les mosaïques.
Latent Vide#
EmptyLTXVLatentVideo (#21) crée un latent vidéo vide selon vos paramètres, et LTXVEmptyLatentAudio (#33) crée un latent audio correspondant afin que le conteneur mux soit convivial pour l'éditeur. Si vous souhaitez commencer à partir d'une image, LTXVImgToVideoInplace (#22) peut l'injecter dans la chronologie latente à une strength contrôlable. Lorsque bypass est activé, le nœud fournit une init purement textuelle.
Générer Basse Résolution#
Les latents audio et vidéo sont fusionnés par LTXVConcatAVLatent (#32) et synchronisés par LTXVScheduler (#47), qui définit un programme sigma vidéo-conscient pour un mouvement fluide et un déplacement de caméra. CFGGuider (#42) combine votre conditionnement positif et négatif avec la pile de modèles, et SamplerCustomAdvanced (#9) exécute le passage principal de génération. LTXVSeparateAVLatent (#35) sépare ensuite le clip en latents vidéo et audio; la sortie par défaut utilise ce latent vidéo stable pour un décodage en mosaïque.
Mise à l'échelle Latente Optionnelle#
LTXVLatentUpsampler (#13) applique le x2 spatial upscaler LTX de LatentUpscaleModelLoader (#39) tout en maintenant la structure temporelle intacte. LTXVImgToVideoInplace (#14) réemballe le latent vidéo mis à l'échelle avec la piste audio existante. Cette branche reste disponible si vous souhaitez expérimenter un raffinement de plus haute résolution, mais elle n'est pas connectée à la sortie finale par défaut.
Raffinement Optionnel#
La branche de raffinement utilise CFGGuider (#8) et SamplerCustomAdvanced (#36) avec un programme sigma court et manuel. Elle est utile pour les utilisateurs avancés qui souhaitent tester le chemin de haute résolution, mais la sortie de workflow par défaut contourne cette branche car le décodage en mosaïque stable de premier passage donne des résultats plus propres sur la configuration fournie RunComfy.
Sortie#
VAEDecodeTiled (#43) décode le latent vidéo stable de LTXVSeparateAVLatent (#35), et LTXVAudioVAEDecode (#23) produit une piste silencieuse qui satisfait les éditeurs. CreateVideo (#38) assemble la séquence à votre fps choisi, et SaveVideo (#45) l'écrit sur le disque. Vous obtenez une vidéo prête à partager avec un mouvement stable, des gradients propres et un flux de caméra contrôlé.
Nœuds clés dans le workflow Comfyui LTX 2.3 Sulphur T2V#
LTXVScheduler (#47)#
Orchestre la séquence sigma vidéo-consciente pour le premier passage. Ses contrôles de décalage influencent la force avec laquelle le mouvement s'accumule entre les cadres; des décalages plus élevés accentuent le déplacement de la caméra et le mouvement du sujet plus rapide, tandis que des valeurs plus basses favorisent un cadrage plus stable. Si vous activez un LoRA de contrôle de caméra, des décalages modestes s'associent mieux pour éviter une dérive exagérée.
LTXVCropGuides (#10)#
Génère des canaux de conditionnement conscients des cultures à partir de votre texte afin que les régions importantes, en particulier les visages, se résolvent avec une plus grande fidélité. Utilisez-le pour diriger les microexpressions et les détails des yeux sans surenchérir sur l'échantillonneur global. Si les gros plans semblent doux, resserrez vos rythmes d'action et laissez Crop Guides faire le réglage fin.
LTXVImgToVideoInplace (#22, #14)#
Transforme une image fixe en un latent temporellement cohérent ou réemballe un latent mis à l'échelle pour un raffinement optionnel. Le contrôle de strength définit combien de l'image source est préservée à travers la chronologie; des valeurs plus basses permettent plus d'adaptation générative, des valeurs plus élevées maintiennent le cadrage et l'identité verrouillés. Activez bypass pour basculer proprement entre I2V et pur T2V.
LTXVLatentUpsampler (#13)#
Applique le x2 spatial upscaler LTX en-latent pour améliorer la texture et les bords pour des expériences de raffinement optionnelles. Le chemin d'exportation par défaut ne dépend pas de ce nœud, vous pouvez donc comparer la sortie stable de premier passage contre la branche de raffinement sans changer la chaîne de sortie principale.
CFGGuider (#42, #8) et KSamplerSelect (#17, #6)#
Ces appariements définissent à quel point le modèle suit votre texte et à quel point il échantillonne agressivement. Gardez les directives conservatrices pour le réalisme vidéo; les augmenter peut améliorer l'adhérence au prompt mais peut raidir le mouvement ou ajouter des scintillements. L'exportation par défaut repose sur l'échantillonneur principal pour un mouvement stable, tandis que l'échantillonneur secondaire est réservé pour des tests de raffinement optionnels.
Extras optionnels#
- Écrivez 3 à 6 rythmes qui décrivent l'intention et le langage corporel plutôt que l'intrigue; les microexpressions émergent d'indices spécifiques comme "les yeux s'adoucissent" ou "les épaules se relâchent."
- Gardez le langage de la caméra compact : un verbe de mouvement plus un sujet, par exemple "dolly-in lent sur son visage" ou "parallaxe douce à partir de voitures garées."
- Si vous voulez un cadrage statique, désactivez le LoRA de contrôle de caméra et réduisez légèrement les décalages du planificateur ; pour plus de déplacement, activez le LoRA et augmentez légèrement le décalage.
- Utilisez une largeur et une hauteur qui sont des multiples propres de 32 pour un découpage et un décodage prévisibles.
- Pour la reproductibilité, verrouillez les graines dans
RandomNoise(#2, #1); changez une seule graine lorsque vous explorez des variations. - Le prompt négatif supprime déjà les artefacts CGI et le scintillement; gardez-le focalisé et laissez votre texte positif porter le style et l'intention.
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement RunningHub pour la référence de workflow, Lightricks pour le modèle LTX 2.3, le LoRA distillé et l'upscaler spatial, et le LoRA de contrôle de caméra, et Comfy-Org pour l'encodeur de texte LTX pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts ci-dessous.
Ressources#
- RunningHub/Workflow Reference
- Docs / Release Notes: Post
- Lightricks/LTX-2.3-fp8
- Hugging Face: Lightricks/LTX-2.3-fp8
- Lightricks/LTX-2.3
- Hugging Face: Lightricks/LTX-2.3
- Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Hugging Face: Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Comfy-Org/ltx-2
- Hugging Face: Comfy-Org/ltx-2
Note: L'utilisation des modèles, ensembles de données et code référencés est soumise aux licences et termes respectifs fournis par leurs auteurs et mainteneurs.