
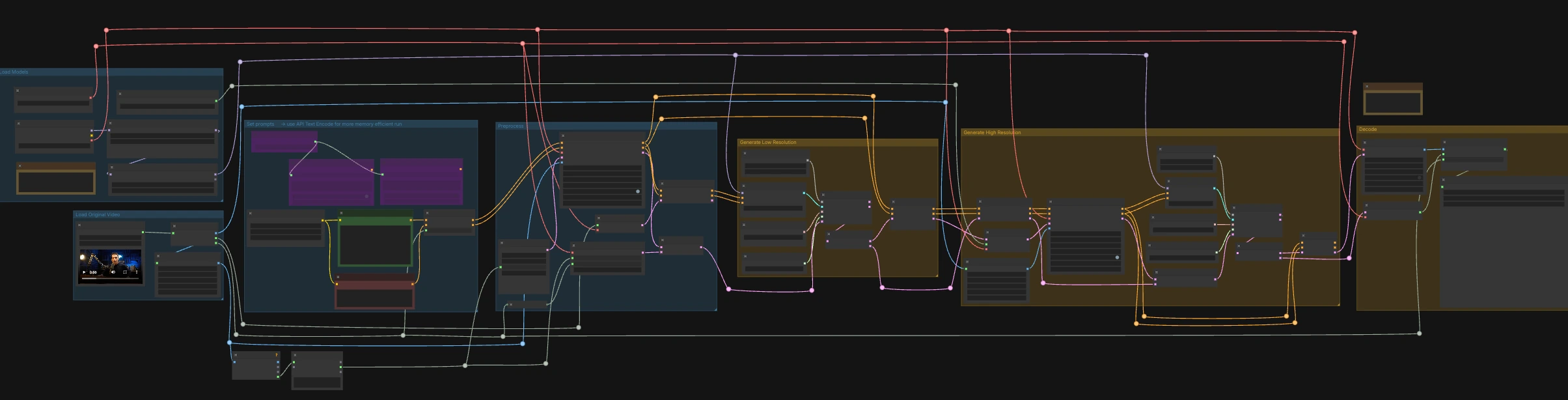
LTX-2.3 ICLoRA LipDub pour ComfyUI#
LTX-2.3 ICLoRA LipDub est un flux de travail ComfyUI contrôlé par vidéo et audio en deux étapes qui double une personne parlant tout en gardant l'identité et le mouvement cohérents. Il combine la conditionnement de texte et vidéo Lightricks LTX-2.3 avec le LipDub IC-LoRA pour aligner précisément le mouvement de la bouche sur le discours fourni, puis affine le résultat à une résolution plus élevée pour un détail net. Le graphe est préparé pour RunComfy avec des noms d'entrée/sortie standardisés afin que vous puissiez échanger des médias et répéter les exécutions de façon fiable.
Ce flux de travail ComfyUI LTX-2.3 ICLoRA LipDub est idéal pour les créateurs ayant besoin de doublage multilingue, de reformulation ou de corrections de type ADR tout en préservant la performance originale. Fournissez une vidéo source qui inclut déjà le discours cible, décrivez la scène et ce que la personne doit dire, et le flux de travail synthétisera des visuels et de l'audio synchronisés en un clip finalisé.
Modèles clés dans le flux de travail Comfyui LTX-2.3 ICLoRA LipDub#
- Modèle vidéo de base LTX-2.3 22B. Le modèle de diffusion fondamental qui génère la vidéo et régit comment les invites dirigent l'apparence, le mouvement et le style.
- LTX-2.3 IC-LoRA LipDub. Un LoRA spécialisé pour le doublage des lèvres qui conditionne le modèle à suivre le discours fourni et à aligner les formes de bouche sur les phonèmes tout en préservant l'identité et le mouvement de la tête. Model card
- LTX-2.3 Audio VAE. Encode le discours d'entrée en un latent audio qui peut être injecté dans le conditionnement de texte et ensuite décodé en forme d'onde, garantissant que le timing reste verrouillé sur les images.
- LTX-2.3 Spatial Upscaler x2. Met à l'échelle les latents vidéo à une résolution spatiale plus élevée avant le passage d'affinement haute résolution, améliorant la texture sans changer le mouvement.
- LTX-2.3 Distilled LoRA (384). Un LoRA de renforcement utilisé avec le point de contrôle de base pour améliorer les détails et la stabilité temporelle sans surajuster à la trame de référence.
Comment utiliser le flux de travail Comfyui LTX-2.3 ICLoRA LipDub#
Ce flux de travail s'exécute en deux étapes coordonnées : un passage à basse résolution pour verrouiller le timing et les formes des lèvres à l'audio, suivi d'un passage à haute résolution qui met à l'échelle et affine les détails tout en préservant la synchronisation. Commencez par charger une vidéo source qui contient déjà le discours que vous souhaitez, puis écrivez la ligne de texte que vous voulez que la personne dise.
Charger la Vidéo Originale#
Le nœud LoadVideo (#5002) importe votre clip source avec audio intégré. GetVideoComponents (#5010) extrait les images, l'audio et le taux de trame; le taux de trame est partagé dans tout le graphe afin que la vidéo et l'audio restent alignés. Deux redimensionneurs, Resize Image/Mask (s1 size) (#5009) et Resize Image/Mask (s2 size) (#5003), préparent les flux d'images de travail pour les passages basse et haute résolution. Le nombre d'images est mesuré et arrondi pour des longueurs compatibles avec le décodeur afin que le décodage reste stable.
Charger les Modèles#
CheckpointLoaderSimple (#5017) charge le modèle de base LTX-2.3 22B et le VAE utilisé dans tout le graphe. Deux chargeurs, LoraLoaderModelOnly (#5018) et LTXICLoRALoaderModelOnly (#5012), ajoutent le LoRA distillé et le IC-LoRA LipDub au-dessus de la base afin que le générateur suive le discours tout en préservant l'identité. LTXVAudioVAELoader (#4010) fournit le VAE audio pour encoder/décoder la bande sonore. La sortie latent_downscale_factor du chargeur IC-LoRA est intentionnellement inutilisée ici parce que la formation LipDub suppose des trames de référence pleine résolution, correspondant à la note incluse.
Définir les invites#
Écrivez la description de votre scène et la ligne parlée exacte dans CLIP Text Encode (Positive Prompt) (#2483). Utilisez CLIP Text Encode (Negative Prompt) (#2612) pour minimiser les traits ou artefacts indésirables. Ceux-ci alimentent LTXVConditioning (#1241), qui adapte le conditionnement au domaine vidéo et porte le contexte du taux de trame vers l'avant. Pour les exécutions à faible VRAM, le graphe inclut également des encodeurs basés sur l'API (🅛🅣🅧 Gemma API Text Encode - POSITIVE (#4980) et ... - NEGATIVE (#4981)) contrôlés par la chaîne LTX API KEY (#4979) ; le câblage par défaut utilise des encodeurs locaux.
Prétraiter#
LTXVAudioVAEEncode (#5005) convertit le discours source en un latent audio, et LTXVSetAudioRefTokens (#5006) injecte ce latent dans le conditionnement de texte afin que le générateur "entende" le timing et les phonèmes. EmptyLTXVLatentVideo (#3059) prépare un latent vidéo de remplacement avec la taille spatiale correcte et un nombre d'images aligné sur l'entrée. LTXAddVideoICLoRAGuide (#5004) attache la référence IC-LoRA en utilisant les trames s1, établissant l'identité et l'attention de la région de la bouche avant l'échantillonnage.
Générer Basse Résolution#
Un boucle de diffusion standard est formée par CFGGuider (#4828), KSamplerSelect (#4831), ManualSigmas (#4984), et SamplerCustomAdvanced (#4829). L'échantillonneur fonctionne sur un latent audio+vidéo composé par LTXVConcatAVLatent (#4528), garantissant que le conditionnement audio participe à chaque étape. Après l'échantillonnage, LTXVSeparateAVLatent (#4845) divise le latent pour que LTXVSetAudioRefTokens (#5013) puisse geler la même représentation du discours pour le passage haute résolution. Cette étape verrouille les formes des lèvres sur le discours et fixe la base du mouvement à la taille s1.
Générer Haute Résolution#
LTXVLatentUpsampler (#4975) élève le latent vidéo en utilisant le Spatial Upscaler x2, préservant le mouvement tout en ajoutant la capacité pour le détail spatial. LTXAddVideoICLoRAGuide (#5014) réapplique IC-LoRA à la taille s2 en utilisant les trames de plus haute résolution pour que l'identité, la région de la bouche, et les traits fins soient renforcés. Une seconde boucle de diffusion (CFGGuider (#4964), KSamplerSelect (#4976), ManualSigmas (#4985), SamplerCustomAdvanced (#4971)) affine le latent mis à l'échelle tandis que LTXVConcatAVLatent (#4969) garde le latent de discours gelé en synchronisation. LTXVCropGuides (#5011, #5015) gère les cultures sûres et les guides de région pour que le visage reste correctement cadré à travers les deux passages.
Décoder#
LTXVTiledVAEDecode (#4995) convertit le latent vidéo final en images en utilisant des tuiles pour l'efficacité VRAM, et LTXVAudioVAEDecode (#4848) renvoie l'audio synchronisé. CreateVideo (#4849) assemble les images et l'audio au taux de trame original, et SaveVideo (#4852) écrit le fichier avec le nom prérempli RunComfy; changez cette valeur pour personnaliser vos sorties. Le résultat est un clip LTX-2.3 ICLoRA LipDub entièrement synchronisé prêt pour révision ou livraison.
Nœuds clés dans le flux de travail Comfyui LTX-2.3 ICLoRA LipDub#
LTXICLoRALoaderModelOnly (#5012)#
Charge le LipDub IC-LoRA et l'attache au modèle de base pour que le mouvement des lèvres suive le discours d'entrée sans remplacer l'identité. Si vous avez besoin d'un contrôle des lèvres plus fort ou plus subtil, ajustez le poids LoRA ici; gardez-le coordonné avec tout autre LoRA que vous appliquez dans la pile pour éviter le surconditionnement.
LTXAddVideoICLoRAGuide (#5004)#
Applique la guidance IC-LoRA au stade basse résolution en utilisant les trames de référence réduites. C'est ici que le flux de travail verrouille d'abord l'identité et l'attention de la région de la bouche; utilisez-le pour des tests A/B en basculant le guide pour voir l'effet de la guidance de référence sur le timing et l'articulation.
LTXAddVideoICLoRAGuide (#5014)#
Réapplique la guidance IC-LoRA à haute résolution avec les trames s2 pour que le passage affiné préserve la même identité de locuteur et les formes de lèvres précises. Si vous changez la taille de trame haute résolution, revisitez ce nœud pour garder le guide de référence cohérent avec votre sortie cible.
LTXVSetAudioRefTokens (#5006)#
Lie le discours encodé à votre conditionnement de texte pour que l'échantillonneur aligne les visèmes avec les phonèmes. Utilisez le même latent audio à travers les passes pour des résultats stables; ce graphe gère cela automatiquement, mais si vous échangez l'audio en cours d'exécution, vous devriez actualiser à la fois le conditionnement et le latent concaténé.
LTXVLatentUpsampler (#4975)#
Met à l'échelle le latent vidéo avec le LTX-2.3 Spatial Upscaler x2 pour faire de la place aux détails fins avant l'échantillonneur haute résolution. Si la VRAM est limitée, associez cela à des dimensions s2 plus petites ou un tuilage plus léger dans le décodeur pour équilibrer qualité et débit.
LTXVTiledVAEDecode (#4995)#
Décode le latent final en trames en utilisant le tuilage pour adapter les sorties larges sur des GPUs limités. Réglez le nombre de tuiles et le chevauchement ici pour échanger la vitesse contre l'empreinte mémoire; moins de tuiles sont plus rapides mais nécessitent plus de VRAM, tandis que plus de tuiles réduisent la VRAM au prix du temps.
Extras optionnels#
- Incitation pour le doublage : incluez les mots exacts que vous voulez faire prononcer; le modèle ne traduit pas automatiquement. Utilisez le script natif de la langue cible, tenez-vous à un seul locuteur, et visez une longueur similaire à la ligne originale pour que le rythme reste naturel.
- Conseils de performance : si vous atteignez les limites de VRAM, réduisez la redimension s2 dans
Resize Image/Mask (s2 size)(#5003) et augmentez le tuilage dansLTXVTiledVAEDecode(#4995). Pour la répétabilité, gardez les grainesRandomNoisefixes dans les deux passes. - Paramètres par défaut du flux de travail : le nom de fichier d'entrée exemple est prérempli dans
LoadVideo(#5002), et le sauvegardeur définit un nom de sortie cohérent. Remplacez les deux pour traiter par lots plusieurs exécutions LTX-2.3 ICLoRA LipDub sans écraser les résultats. - Cadrage : si le visage dérive près des bords, ajustez
LTXVCropGuides(#5011, #5015) pour que la région de la bouche reste dans une découpe stable à travers les deux passes.
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions sincèrement Lightricks pour le modèle LTX-2.3-22b-IC-LoRA-LipDub et RunComfy pour le flux de travail ComfyUI partagé (source Cloud Save) pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- arXiv: arXiv:2601.22143
- RunComfy/Cloud Save source
- Docs / Notes de version: RunComfy shared workflow
Note : L'utilisation des modèles, ensembles de données, et code référencés est soumise aux licences respectives et aux termes fournis par leurs auteurs et mainteneurs.