
LTX 2.3 Synchronisation Labiale à Deux Personnages LoRA : vidéo synchronisée à deux personnages à partir d'une image et d'une piste audio#
Ce flux de travail ComfyUI transforme une image fixe unique et une conversation enregistrée à deux interlocuteurs en une vidéo cohérente et stable en termes d'identité, avec un discours synchronisé pour les deux personnages à l'écran. Construit autour de la base vidéo LTX-2.3 et du LTX 2.3 Synchronisation Labiale à Deux Personnages LoRA, il mappe les phonèmes et le timing de votre dialogue sur chaque visage tout en préservant les expressions, le regard et la cohérence de la scène à travers les images.
Conçu pour les interviews, les dialogues cinématographiques, les podcasts avec des animateurs vidéo et les interactions de personnages virtuels, le flux de travail associe l'incitation textuelle pour la mise en page de la scène avec le mouvement audio. Il inclut une étape de démarrage d'image pour un développement rapide de l'aspect, un échantillonnage en deux étapes LTX pour la stabilité temporelle, et un upscaler latent pour des résultats nets. Le résultat final est un MP4 avec audio intégré.
Modèles clés dans le flux de travail Comfyui LTX 2.3 Synchronisation Labiale à Deux Personnages LoRA#
- Modèle de génération vidéo LTX-2.3. Fournit la base de diffusion multimodale qui synthétise une vidéo temporellement cohérente conditionnée par le texte, l'image et l'audio. Lightricks/LTX-2.3
- LTX-2.3 VAE Vidéo et VAE Audio. Encodent et décodent les latents vidéo et audio utilisés par le modèle pour maintenir l'efficacité et la synchronisation de la génération. Livré avec la version LTX-2.3. Lightricks/LTX-2.3
- Upscaler latent spatial LTX. Affine les détails après le passage de base en suréchantillonnant dans l'espace latent pour des textures et des bords plus propres. Des variantes sont disponibles avec les actifs LTX. Lightricks/LTX-2
- LTX 2.3 Synchronisation Labiale à Deux Personnages LoRA. Injecte une formation qui encourage le mouvement de la bouche par interlocuteur et le timing pour deux visages dans le même plan tout en conservant l'identité faciale.
- Modèle de texte-à-image Turbo Z-Image. Produit rapidement une référence fixe de haute qualité qui ancre l'identité, le cadrage et l'éclairage avant la synthèse vidéo. Comfy-Org/z_image_turbo
Packs de nœuds liés utilisés par ce flux de travail : ComfyUI-KJNodes, ComfyUI-VideoHelperSuite, rgthree-comfy, et ComfyUI-PromptRelay.
Comment utiliser le flux de travail Comfyui LTX 2.3 Synchronisation Labiale à Deux Personnages LoRA#
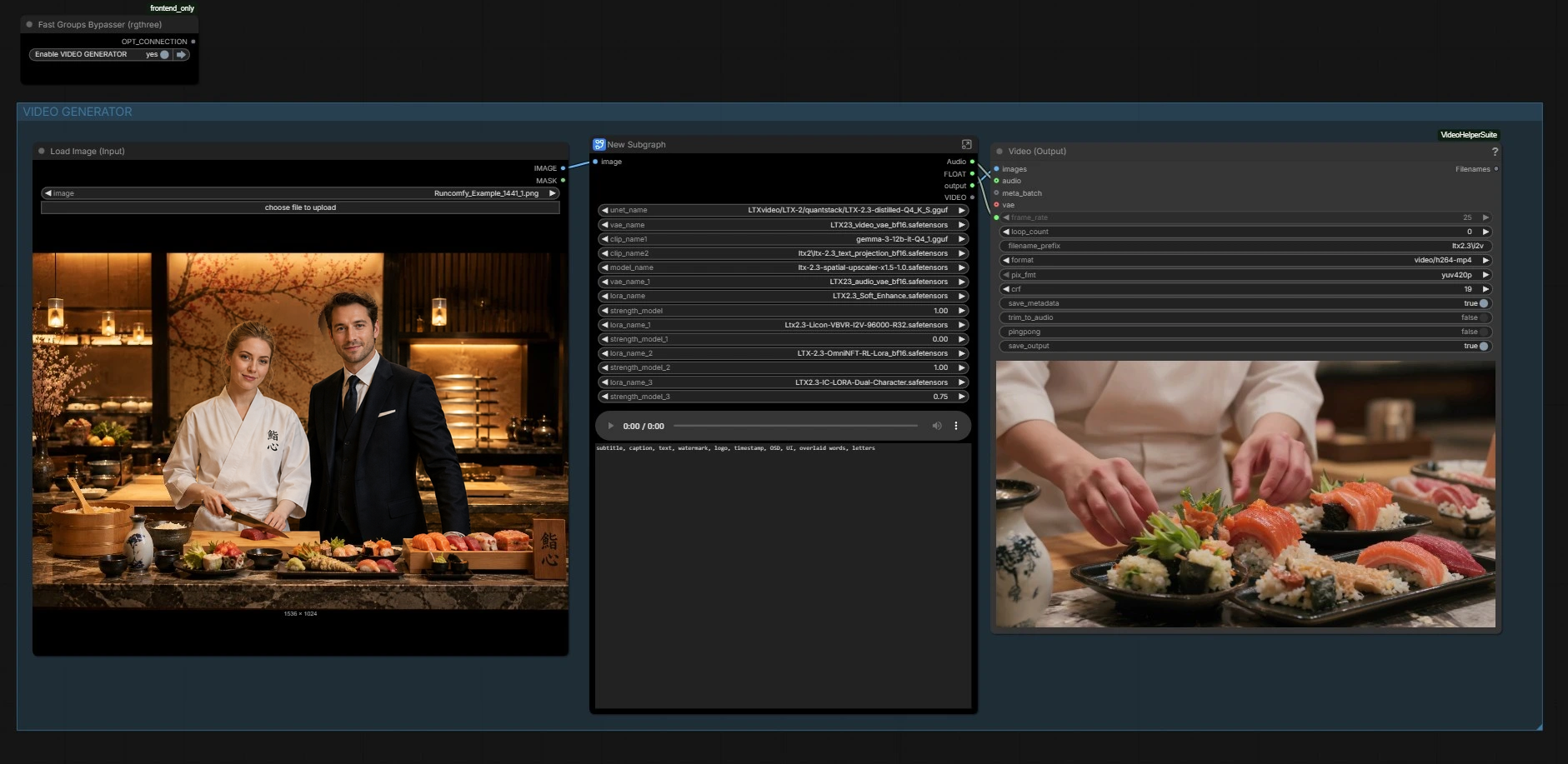
Le flux de travail a deux parties coordonnées : un générateur d'images qui crée l'image principale, et un générateur vidéo qui anime le mouvement et la synchronisation labiale à partir de l'audio tout en préservant l'apparence. Utilisez les groupes ci-dessous comme guide.
GÉNÉRATEUR D'IMAGES#
Cette section construit l'image d'ancrage. Utilisez les préréglages de scène dans la liste des invites pour rédiger rapidement des compositions, puis affinez le texte avec des descriptions de personnages pour les deux personnes. Une pile de diffusion d'images compacte (sous-graphe "Z IMG TURBO") encode votre invite et échantillonne une référence fixe propre. L'image est décodée et sauvegardée pour inspection, puis transmise pour semer l'identité et la mise en page pour la vidéo.
Entrées clés que vous touchez ici : l'invite descriptive pour la scène, la garde-robe, et deux personnages distincts ; évitez le jargon d'objectif ou de rendu qui combat le réalisme à moins que cet aspect ne soit intentionnel.
Modèles#
Ici, le graphe charge la base LTX-2.3, ses VAE vidéo et audio, les encodeurs de texte, et l'upscaler latent. Il applique également le LTX 2.3 Synchronisation Labiale à Deux Personnages LoRA, plus des LoRAs de style ou d'amélioration optionnels si vous les activez. C'est là que les capacités du modèle de base sont combinées avec le comportement de synchronisation labiale à deux interlocuteurs du LoRA pour orienter le mouvement de la bouche sans sacrifier l'identité. Aucune action n'est nécessaire à moins que vous ne souhaitiez échanger des poids ou ajuster l'influence du LoRA.
AUDIO PERSONNALISÉ#
Fournissez votre piste de conversation ici. Le fichier audio est chargé et encodé en un latent audio qui transporte le timing et les indices phonétiques à travers le pipeline. Si vous ne fournissez pas d'audio, le flux de travail peut générer du mouvement en utilisant un latent audio vide, mais le LTX 2.3 Synchronisation Labiale à Deux Personnages LoRA est conçu pour briller avec un dialogue réel. Utilisez un mixage propre à deux interlocuteurs avec une prise de parole claire pour une meilleure séparation des mouvements de la bouche.
PARAMÈTRES VIDÉO#
Définissez la durée cible et le taux de trame. Ces valeurs sont stockées et réutilisées tout au long de l'échantillonnage, de la planification, des guides de recadrage et du rendu final afin que les lèvres, les clignements d'yeux et le timing des plans restent alignés. Gardez la longueur de votre vidéo cohérente avec l'audio fourni pour éviter un délai d'entrée ou de sortie.
GÉNÉRATION LATENTE#
Votre image fixe sélectionnée est prétraitée et ses dimensions sont détectées. Le flux de travail crée un latent vidéo de la bonne longueur, puis insère l'image fixe en place pour que la première image corresponde à votre conception. Un masque de bruit pleine trame est appliqué pour contrôler à quel point l'arrière-plan peut évoluer par rapport aux visages. Le latent audio préparé est ensuite associé au latent vidéo pour que les deux modalités soient prêtes pour le conditionnement.
Nœuds notables : LTXVPreprocess met à l'échelle votre image fixe pour LTX, EmptyLTXVLatentVideo construit la chronologie, et LTXVImgToVideoInplaceKJ (#5881) verrouille l'identité en semant la première image à partir de l'image fixe.
Conditionnement#
Les invites textuelles sont encodées et attachées comme conditions positives et négatives. Utilisez la boîte d'invite globale pour décrire la mise en scène et l'intention en langage naturel ; vous pouvez inclure une courte liste de plans si utile. Un encodeur de texte négatif dédié supprime les sous-titres, les filigranes et l'interface utilisateur à l'écran pour que les visages restent propres. Les aides de guide de recadrage analysent le latent pour placer l'attention sur les deux visages, améliorant le suivi des expressions par interlocuteur avec le LTX 2.3 Synchronisation Labiale à Deux Personnages LoRA actif.
Composants représentatifs : PromptRelayEncode (#5903) fusionne votre description de scène avec le contexte latent, et LTXVConditioning attache une orientation consciente du taux de trame pour les deux modalités.
1ère Échantillonnage#
Le premier passage de débruitage génère une vidéo de base temporellement cohérente avec le mouvement des lèvres bloqué. Un planificateur et un échantillonneur légers sont sélectionnés automatiquement, avec des paramètres routés à partir des valeurs de timing stockées. La variante de modèle sortant de LTX2_NAG ajoute une orientation consciente du bruit pour les conditions vidéo et audio afin que le timing du discours reste ancré à mesure que le contenu se forme.
Chemin de l'échantillonneur principal : SamplerCustom (#5891) avec KSamplerSelect et un planificateur de base ; ajustez uniquement si vous avez des préférences d'échantillonneur spécifiques.
Étape #2 Mise à l'échelle et affinage#
La deuxième étape améliore la netteté et les micro-expressions. L'upscaler latent augmente le détail spatial, les latents audio et vidéo sont rejoints, et un échantillonneur de raffinement effectue des corrections subtiles tout en préservant le mouvement établi. Ensuite, les latents sont séparés et décodés en une séquence d'images et une forme d'onde audio.
Blocs importants : LTXVLatentUpsampler (#5927) pour la clarté, SamplerCustomAdvanced (#5929) pour le passage de raffinement, suivi de VAEDecode et LTXVAudioVAEDecode pour retourner à l'espace pixel et audio.
Sortie#
Enfin, les images et l'audio sont emballés dans un MP4 pour lecture et révision. Le taux de trame utilisé pour le conditionnement est réutilisé ici afin que la cadence visuelle et le timing des phonèmes correspondent à ce que le modèle a vu pendant la génération. Vous pouvez également prévisualiser l'audio au milieu du graphe si vous avez besoin d'une vérification rapide.
Chemin de sortie : CreateVideo (#5931) construit le clip ; un chemin auxiliaire VHS_VideoCombine (#5905) est fourni pour des exportations alternatives avec des contrôles de métadonnées.
Nœuds clés dans le flux de travail Comfyui LTX 2.3 Synchronisation Labiale à Deux Personnages LoRA#
LTXICLoRALoaderModelOnly(#5958) Charge le LTX 2.3 Synchronisation Labiale à Deux Personnages LoRA dans la base LTX-2.3. Augmentezstrength_modellorsque vous avez besoin d'une articulation de la bouche plus serrée et d'une séparation des interlocuteurs ; baissez-la lorsque vous souhaitez que le mouvement et le style du modèle de base dominent, surtout si vous empilez des LoRAs de style supplémentaires.PromptRelayEncode(#5903) Endroit central pour écrire la description de la scène et, éventuellement, un bref plan de prise de vue. Il fusionne l'invite globale avec le contexte du modèle et le latent actuel pour que l'orientation reste cohérente tout au long de la chronologie. Gardez le langage clair et décrivez distinctement les deux personnages pour aider à la séparation d'identité et de rôle.LTXVImgToVideoInplaceKJ(#5881) Sème la première image du latent vidéo directement à partir de votre image fixe générée ou chargée. Cela verrouille l'identité, la garde-robe et l'éclairage, réduisant la dérive au fil du temps. Utilisez un plan moyen ou moyen-large à deux prises avec les deux visages non obstrués pour de meilleurs résultats.LTXVAudioVAEEncode(#5851) Convertit la piste de dialogue fournie en un latent audio que le modèle peut utiliser pour le timing des phonèmes. Fournissez un mixage propre sans compression excessive ; assurez-vous que l'heure de début correspond au premier discours à l'écran pour éviter un décalage du mouvement des lèvres.SamplerCustom(#5891) etSamplerCustomAdvanced(#5929) Deux étapes de débruitage complémentaires. Gardez les familles d'échantillonneurs cohérentes entre les étapes pour maintenir la continuité du mouvement, et évitez les changements drastiques dans la planification du bruit une fois que vous avez un aspect qui vous plaît.LTXVLatentUpsampler(#5927) Applique l'upscaler latent LTX avant le raffinement pour ajouter de la netteté sans déstabiliser le mouvement établi. Choisissez une variante d'upscaler appropriée pour votre résolution cible et le réalisme des textures.
Extras optionnels#
- Utilisez un WAV à deux interlocuteurs à 24 kHz avec un bruit de fond minimal ; ajoutez de courtes pauses naturelles entre les lignes pour aider le LTX 2.3 Synchronisation Labiale à Deux Personnages LoRA à séparer les tours.
- Générez ou fournissez une image fixe où les deux sujets sont visibles, généralement face à la caméra, avec un éclairage uniforme sur les visages.
- Gardez l'invite de texte négative qui exclut "sous-titre, légende, logo, horodatage" pour éviter les éléments d'interface utilisateur intégrés pendant l'échantillonnage.
- Commencez par un court clip pour valider le timing, puis prolongez la durée ou augmentez la résolution une fois que vous aimez le comportement.
- Si vous ajoutez des LoRAs de style, équilibrez-les avec le LTX 2.3 Synchronisation Labiale à Deux Personnages LoRA pour que l'articulation reste précise tout en conservant l'esthétique choisie pour la scène.
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions sincèrement les créateurs de "LTX 2.3 Dual Character Lip Sync LoRA Workflow Source" pour le flux de travail. Pour des détails autoritaires, veuillez vous référer à la documentation et aux dépôts originaux liés ci-dessous.
Ressources#
- LTX 2.3 Dual Character Lip Sync LoRA Workflow Source/LTX 2.3 Dual Character Lip Sync LoRA Workflow Source
- Docs / Notes de version : YouTube video
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et termes respectifs fournis par leurs auteurs et mainteneurs.