
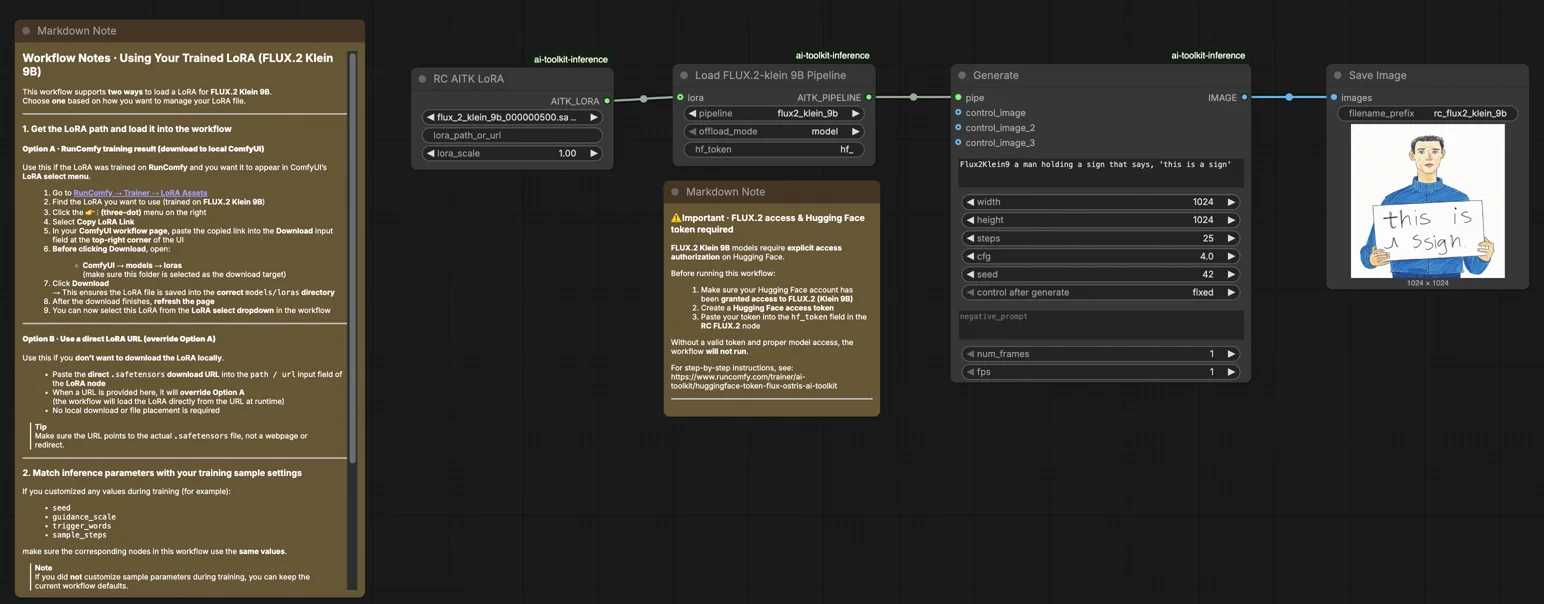
FLUX.2 Klein 9B LoRA ComfyUI Inference : génération de LoRA alignée sur l'aperçu de l'AI Toolkit dans ComfyUI#
Utilisez ce flux de travail RunComfy lorsque vous avez besoin d'une inférence ComfyUI qui reste cohérente avec les aperçus de formation de l'AI Toolkit pour les FLUX.2 Klein 9B LoRAs. La configuration dirige la génération à travers Flux2Klein9BPipeline—un wrapper de pipeline spécifique au modèle open-sourcé par RunComfy—plutôt qu'un graphe d'échantillonneur standard. Votre adaptateur est appliqué via lora_path et lora_scale à l'intérieur de ce pipeline, vous donnant un comportement LoRA conforme à l'entraînement sans reconstruction manuelle du pipeline.
Pourquoi l'inférence FLUX.2 Klein 9B LoRA ComfyUI semble souvent différente dans ComfyUI#
Lorsque l'AI Toolkit rend un aperçu de formation, il exécute le pipeline d'inférence complet FLUX.2 Klein 9B—Qwen3-8B encodage de texte, planification de correspondance de flux, et injection interne de LoRA se produisent tous comme une unité coordonnée. Un graphe ComfyUI typique réassemble ces composants de manière indépendante, ce qui introduit des différences subtiles dans le conditionnement, la planification du bruit, et l'ordre d'application de l'adaptateur. Le résultat est une dérive au niveau du pipeline, pas un seul bouton mal configuré. Flux2Klein9BPipeline comble cet écart en exécutant le pipeline propre au modèle de bout en bout et en injectant votre LoRA à l'intérieur. Référence : `src/pipelines/flux2_klein.py`.
Comment utiliser le flux de travail FLUX.2 Klein 9B LoRA ComfyUI Inference#
Étape 1 : Obtenez le chemin LoRA et chargez-le dans le flux de travail (2 options)#
Option A — Résultat d'entraînement RunComfy > téléchargement vers ComfyUI local :
- Allez à Trainer > LoRA Assets
- Trouvez le FLUX.2 Klein 9B LoRA que vous souhaitez utiliser
- Cliquez sur le menu ... (trois points) à droite > sélectionnez Copier le lien LoRA
- Dans la page de flux de travail ComfyUI, collez le lien copié dans le champ d'entrée Download en haut à droite de l'interface
- Avant de cliquer sur Télécharger, assurez-vous que le dossier cible est défini sur ComfyUI > models > loras (ce dossier doit être sélectionné comme cible de téléchargement)
- Cliquez sur Télécharger — le fichier LoRA est enregistré dans le répertoire
models/lorascorrect - Une fois le téléchargement terminé, actualisez la page
- Le LoRA apparaît maintenant dans le menu déroulant de sélection de LoRA — sélectionnez-le

Option B — URL directe LoRA (remplace l'Option A) :
- Collez l'URL de téléchargement directe
.safetensorsdans le champ d'entréepath / urldu nœud LoRA - Lorsqu'une URL est fournie ici, elle remplace l'Option A — le flux de travail récupère le LoRA directement à partir de l'URL à l'exécution
- Aucun téléchargement local ou placement de fichier n'est requis
Astuce : confirmez que l'URL résout le fichier .safetensors réel, pas une page d'atterrissage ou une redirection.

Étape 2 : Faites correspondre les paramètres d'inférence avec vos paramètres d'échantillon d'entraînement#
Réglez lora_scale sur le nœud LoRA pour contrôler la force de l'adaptateur—commencez avec la valeur que vous avez utilisée pendant les aperçus de formation et ajustez à partir de là.
Les autres paramètres se trouvent sur les nœuds Generate et Load Pipeline :
prompt— votre texte d'invite ; incluez tous les mots déclencheurs de l'entraînementwidth/height— résolution de sortie ; faites correspondre la taille de votre aperçu de formation pour une comparaison directe (multiples de 16)sample_steps— étapes d'inférence ; FLUX.2 Klein 9B par défaut à 25guidance_scale— force CFG ; par défaut à 4.0 (Klein 9B n'est pas distillé par guidance, donc cette valeur façonne directement la qualité de sortie)seed— fixez une graine pour reproduire une sortie spécifique ; changez-la pour explorer des variationsseed_mode—fixedourandomizehf_token— un token Hugging Face valide est requis car FLUX.2 Klein 9B est un modèle protégé ; collez votre token dans le champhf_tokensur le nœud Load Pipeline
Astuce d'alignement de formation : si vous avez personnalisé les valeurs d'échantillonnage pendant la formation (seed, guidance_scale, sample_steps, mots déclencheurs), copiez ces valeurs exactes dans les champs correspondants. Si vous vous êtes entraîné sur RunComfy, ouvrez Trainer > LoRA Assets > Config pour voir le YAML résolu et transférer les paramètres d'aperçu/échantillon.

Étape 3 : Exécutez FLUX.2 Klein 9B LoRA ComfyUI Inference#
Cliquez sur Queue/Run — le nœud SaveImage écrit les résultats dans votre dossier de sortie ComfyUI.
⚠️ Important · Accès FLUX.2 et token Hugging Face requis#
Les modèles FLUX.2 Klein 9B nécessitent une autorisation d'accès explicite sur Hugging Face.
Avant d'exécuter ce flux de travail :
- Assurez-vous que votre compte Hugging Face a été autorisé à accéder à FLUX.2 (Klein 9B)
- Créez un token d'accès Hugging Face
- Collez votre token dans le champ
hf_tokendans le nœud RC FLUX.2
Sans un token valide et un accès correct au modèle, le flux de travail ne s'exécutera pas.
Pour des instructions étape par étape, consultez : https://www.runcomfy.com/trainer/ai-toolkit/huggingface-token-flux-ostris-ai-toolkit
Liste de contrôle rapide :
- ✅ Le compte Hugging Face a accès à FLUX.2 Klein 9B et un token valide est dans
hf_token - ✅ LoRA est soit : téléchargé dans
ComfyUI/models/loras(Option A), soit chargé via une URL directe.safetensors(Option B) - ✅ Page actualisée après le téléchargement local (Option A uniquement)
- ✅ Les paramètres d'inférence correspondent à la configuration de l'échantillon de formation (si personnalisée)
Si tout ce qui précède est correct, les résultats d'inférence ici devraient correspondre étroitement à vos aperçus de formation.
Dépannage de l'inférence FLUX.2 Klein 9B LoRA ComfyUI#
La plupart des écarts "aperçu de formation vs inférence ComfyUI" sur FLUX.2 Klein 9B proviennent de différences au niveau du pipeline (chemin de l'encodeur de texte, planification/conditionnement, et où/comment l'adaptateur est appliqué). Le flux de travail RunComfy évite de reconstruire le pipeline manuellement en exécutant la génération à travers Flux2Klein9BPipeline et en injectant le LoRA à l'intérieur de ce pipeline via lora_path / lora_scale, ce qui est la façon la plus proche de reproduire le comportement d'aperçu de l'AI Toolkit dans ComfyUI.
(1) Erreur 401 Client.#
Pourquoi cela arrive FLUX.2 Klein 9B est un modèle protégé sur Hugging Face. Si votre compte n'a pas accès, ou si aucun token valide n'est fourni, les poids du modèle ne peuvent pas être téléchargés et l'inférence échoue avec une erreur 401.
Comment réparer
- Assurez-vous que votre compte Hugging Face a été autorisé à accéder à
black-forest-labs/FLUX.2-klein-base-9B. - Créez un token d'accès Hugging Face et collez-le dans le champ
hf_tokensur le nœud Load Pipeline. - Après confirmation de l'accès et du token, exécutez l'inférence via les nœuds de pipeline AI Toolkit RunComfy pour que l'authentification et le chargement du modèle se fassent dans un seul pipeline cohérent.
- Pour des instructions étape par étape, consultez : https://www.runcomfy.com/trainer/ai-toolkit/huggingface-token-flux-ostris-ai-toolkit
(2) Erreurs CLIPLoader des modèles Flux 2 Klein#
Pourquoi cela arrive Ces erreurs sont causées par un décalage d'encodeur de texte—par exemple, le chargement d'un encodeur incompatible ou le mélange des actifs d'encodeur Klein 4B et Klein 9B. Cela apparaît souvent comme des décalages d'embedding ou de taille de vocabulaire lors du chargement de CLIP/encodeur de texte.
Comment réparer
- Mettez à jour ComfyUI à la dernière version pour garantir le support complet de FLUX.2 Klein.
- Assurez-vous que l'encodeur de texte correct pour Klein 9B est utilisé (Klein 9B nécessite Qwen3-8B ; l'utilisation d'un encodeur 4B échouera).
- Pour une inférence LoRA alignée sur l'aperçu, préférez le wrapper de pipeline RunComfy, qui charge le bon encodeur et applique le LoRA dans le même pipeline utilisé pour les aperçus de l'AI Toolkit.
(3) Les formes de mat1 et mat2 ne peuvent pas être multipliées (512x2560 et 7680x3072)#
Pourquoi cela arrive Cette erreur indique un décalage de dimension de conditionnement, généralement causé par l'utilisation du mauvais encodeur ou d'un type de clip/conditionnement incorrect pour FLUX.2 Klein 9B. Le modèle reçoit des embeddings de la mauvaise forme, provoquant l'échec de la multiplication de matrices pendant l'échantillonnage.
Comment réparer
- Si vous construisez des graphes manuellement, vérifiez que vous utilisez l'encodeur de texte spécifique à FLUX.2 Klein et que le type de clip/conditionnement correspond aux attentes de FLUX.2 Klein.
- Pour la solution la plus fiable, exécutez l'inférence via le wrapper de pipeline FLUX.2 Klein 9B de RunComfy (
model_type = flux2_klein_9b) et injectez votre LoRA vialora_path. Cela maintient toute la pile d'inférence—encodeur, planificateur et adaptateur—alignée sur le pipeline avec les aperçus de l'AI Toolkit.
Exécutez maintenant l'inférence FLUX.2 Klein 9B LoRA ComfyUI#
Chargez le flux de travail, collez votre lora_path, entrez un hf_token valide, et laissez Flux2Klein9BPipeline garder la sortie ComfyUI alignée avec vos aperçus de formation de l'AI Toolkit.

