
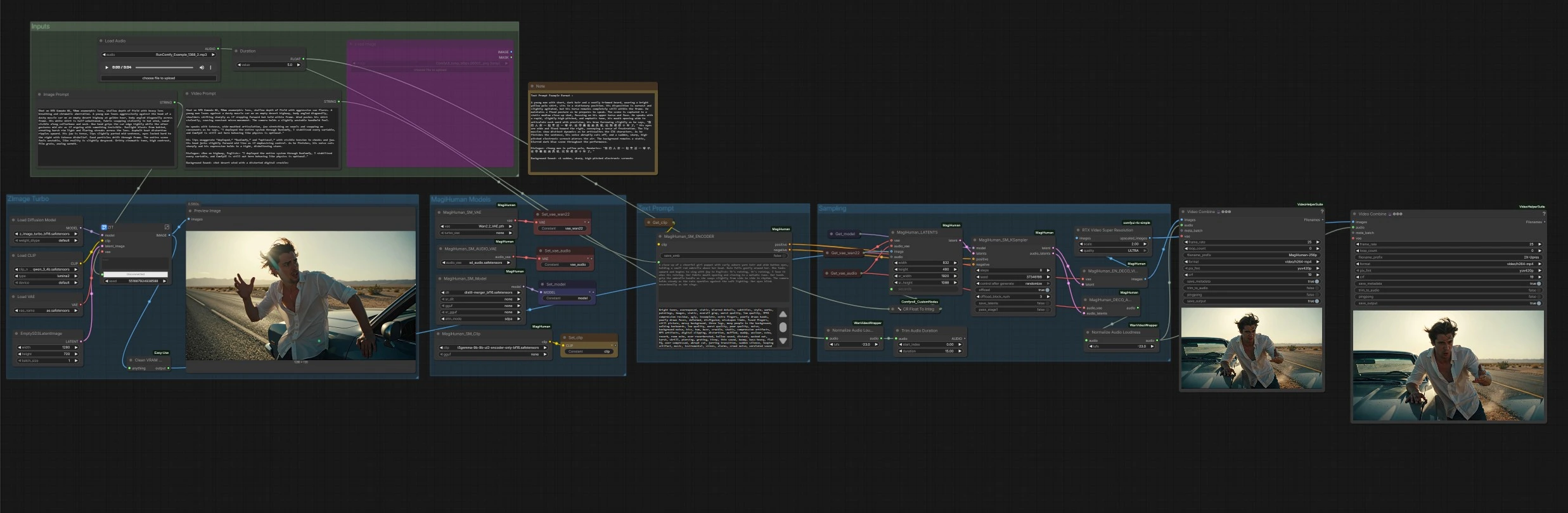
Flux de travail numérique humain parlant daVinci-MagiHuman pour ComfyUI#
Ce flux de travail ComfyUI construit un pipeline complet de texte à vidéo autour de daVinci-MagiHuman pour générer des humains numériques parlants réalistes avec un discours synchronisé, un mouvement labial, une expression et une micro-mouvement corporel. Il est conçu pour les créateurs qui veulent un chemin rapide et en un clic d'une invite descriptive à un MP4 avec un son propre. Le graphique peut animer un portrait fraîchement généré ou toute image de référence fournie, puis rendre la vidéo et le discours ensemble, en terminant par un suréchantillonnage optionnel et une normalisation automatique de la sonie audio.
Le noyau daVinci-MagiHuman utilise un Transformer à flux unique pour co-générer la vidéo et l'audio à partir d'une seule invite, ce qui aide à préserver la synchronisation temporelle et la fidélité labiale même sur des clips courts. Cette implémentation ComfyUI garde les contrôles simples : écrivez une Invite d'Image pour définir l'apparence, une Invite Vidéo pour définir la performance et le dialogue, définissez la Durée du clip, et exécutez.
Modèles clés dans le flux de travail daVinci-MagiHuman de ComfyUI#
- daVinci-MagiHuman (générateur audio-vidéo à flux unique 15B). Rôle : produit conjointement des images vidéo et du discours à partir de texte tout en maintenant la cohérence temporelle et la synchronisation labiale. Références : GitHub, arXiv, Hugging Face.
- Encodeur T5Gemma 9B (adapté UL2). Rôle : encode l'Invite Vidéo en un conditionnement riche qui guide le mouvement, la livraison et le style pour daVinci-MagiHuman. Référence : Hugging Face.
- Modèle de diffusion Turbo d'Image Z. Rôle : génère rapidement un portrait fixe de haute qualité à partir de l'Invite d'Image à utiliser comme identité/référence pour l'animation. Références : Hugging Face (z_image_turbo), Hugging Face (z_image).
- Encodeur de texte Qwen 3 4B pour Turbo d'Image Z. Rôle : analyse l'Invite d'Image pour guider la génération de portrait. Référence : Fichier Hugging Face.
- Wan 2.2 VAE. Rôle : décode les latents vidéo de MagiHuman en images RGB avec une forte cohérence temporelle. Références : GitHub, Exemple de modèle Hugging Face.
- VAE Audio (sd_audio). Rôle : décode les latents audio de MagiHuman en une forme d'onde de discours pour le multiplexage avec la vidéo finale. Référence : bundle de nœud personnalisé pour MagiHuman GitHub.
- Super Résolution Vidéo RTX (optionnel). Rôle : suréchantillonne les images décodées pour augmenter la netteté perçue et réduire les artefacts de compression avant le codage final. Référence : wrapper ComfyUI GitHub.
Comment utiliser le flux de travail daVinci-MagiHuman de ComfyUI#
Flux global : le groupe Turbo d'Image Z crée un portrait d'identité à partir de votre Invite d'Image. Le groupe de Modèles MagiHuman charge le point de contrôle daVinci-MagiHuman, le VAE vidéo et le VAE audio, et prépare l'encodeur de texte. Le groupe d'Invite de Texte transforme votre Invite Vidéo en conditionnement. Le groupe d'Échantillonnage fusionne l'image de référence et l'invite en latents conjoints vidéo et audio, puis décode les deux. Enfin, l'étape de Sorties multiplexe les images avec l'audio en MP4, avec une version suréchantillonnée optionnelle.
Entrées#
Utilisez les boîtes de texte Invite d'Image et Invite Vidéo pour décrire l'apparence et la performance. Le contrôle de Durée définit la longueur du clip en secondes. Un chargeur audio est présent pour plus de commodité si vous prévoyez d'expérimenter des variantes audio, mais ce modèle fonctionne en mode texte par défaut.
Turbo d'Image Z#
Cette étape rend un seul portrait de référence à partir de l'Invite d'Image en utilisant le Turbo d'Image Z UNet avec l'encodeur de texte Qwen 3 4B et son VAE intégré. Il est optimisé pour une génération d'identité rapide et propre avec des looks cinématographiques. Le résultat est prévisualisé, puis transmis comme image de référence pour l'animation. Si vous avez déjà un portrait, vous pouvez contourner cela en reliant directement votre image à l'étape d'animation.
Modèles MagiHuman#
Ici, le graphique charge le point de contrôle de base ou distillé de daVinci-MagiHuman avec le VAE vidéo Wan 2.2, le VAE audio et l'encodeur T5Gemma. Cela garde l'encodage texte, les latents vidéo et les latents audio alignés pour un échantillonnage à flux unique. Vous pouvez échanger les poids si vous avez des alternatives disponibles dans votre environnement.
Invite de Texte#
Votre Invite Vidéo est encodée en conditionnements positifs et négatifs. Le texte positif doit décrire la distance de la caméra, la pose, la langue, le style de livraison et le contenu exact du dialogue. Le texte négatif peut énumérer les défauts visuels ou audio à éviter. L'encodeur alimente les deux ensembles de conditionnements dans l'échantillonneur pour façonner le mouvement, la dynamique labiale et le timbre.
Échantillonnage#
L'échantillonneur construit une séquence latente initiale à partir de l'image de référence et de la Durée demandée, puis effectue un débruitage avec daVinci-MagiHuman pour produire des latents vidéo et audio synchronisés. Une utilité convertit la Durée en secondes entières pour une planification stable. Lorsque l'échantillonnage est terminé, les latents vidéo vont au décodeur vidéo et les latents audio vont au décodeur audio.
Décodage, sonie et exportation#
Les latents vidéo sont décodés avec le VAE Wan 2.2 en images. Les latents audio sont décodés en discours, puis normalisés à une sonie adaptée à la diffusion pour que le MP4 final soit lu de manière cohérente sur tous les appareils. Deux exports sont produits : un rendu de base et un rendu suréchantillonné optionnel utilisant la Super Résolution Vidéo RTX. Les deux sont multiplexés en MP4 avec l'audio et enregistrés avec des préfixes de nom de fichier clairs.
Nœuds clés dans le flux de travail daVinci-MagiHuman de ComfyUI#
MagiHuman_LATENTS(#13)
Construit la toile latente conjointe pour la vidéo et l'audio optionnel, en prenant l'image de référence et la longueur du clip. Ajustez seconds pour définir la durée et assurez-vous que votre image de référence est bien cadrée pour le mouvement que vous décrivez. Une résolution de base plus élevée aide la fidélité faciale mais augmente également la VRAM et le temps de décodage.
MagiHuman_SM_ENCODER(#95)
Encode l'Invite Vidéo en conditionnements positifs et négatifs pour l'échantillonneur. Mettez la ligne parlée exacte entre guillemets et nommez la langue pour améliorer la fermeture labiale et le timing. Utilisez le champ négatif pour supprimer les artefacts comme "sous-titres", "statique" ou "écho de pièce".
MagiHuman_SM_KSampler(#9)
Exécute le débruitage daVinci-MagiHuman pour co-générer des latents vidéo et discours. Le seed contrôle la reproductibilité, tandis que steps et le calendrier interne échangent la rapidité pour le détail et la stabilité du mouvement. Pour la variation sans perdre l'identité, changez seed ou reformulez légèrement la partie performance de votre invite.
MagiHuman_EN_DECO_VIDEO(#5)
Décode les latents vidéo avec le VAE Wan 2.2 en images RGB pour l'exportation ou le suréchantillonnage. Utilisez ce chemin pour le rendu le plus rapide de bout en bout ; les clips longs ou les résolutions plus élevées augmenteront linéairement le temps de décodage.
MagiHuman_DECO_AUDIO(#6)
Décode les latents audio en forme d'onde et les envoie à travers la normalisation de la sonie pour une lecture uniforme. Si vous passez plus tard à la génération audio, dirigez votre audio externe vers le constructeur latent et gardez ce chemin de décodage pour le multiplexage final.
RTXVideoSuperResolution(#93)
Suréchantillonneur optionnel qui affine les bords et réduit les artefacts de sonnerie. Utilisez une force modérée pour améliorer la clarté sans introduire de scintillement temporel.
Extras optionnels#
- Modèle d'invite pour une synchronisation labiale fiable : incluez une étiquette de locuteur et la langue plus une ligne citée, par exemple Dialogue : <Présentateur, Anglais> : "Bienvenue à l'émission." Ajoutez une brève note sur la livraison, la taille de la prise de vue et la stabilité de la caméra.
- Gardez le portrait de référence comme un gros plan moyen avec la tête entièrement dans le cadre. Les recadrages serrés laissent peu de place pour les dynamiques de la mâchoire et des joues.
- Si vous avez besoin d'un timing plus strict, ajustez ou prolongez votre script pour correspondre à la Durée choisie. Les phrases très longues dans les clips très courts peuvent forcer une articulation non naturelle.
- Ce modèle fonctionne en mode uniquement invite. Pour des tests audio, connectez un fichier audio externe à l'entrée audio sur
MagiHuman_LATENTS(#13) et ajustez votre Invite Vidéo pour décrire l'expression plutôt que le contenu parlé.
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions sincèrement daVinci-MagiHuman pour la Source du Flux de Travail daVinci-MagiHuman pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- daVinci-MagiHuman/Source du Flux de Travail
- Docs / Notes de version : Source du Flux de Travail daVinci-MagiHuman
Note : L'utilisation des modèles, jeux de données et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.