
ComfyUI MOSS TTS: synthèse vocale, clonage de voix, effets spéciaux, et dialogue dans un seul workflow#
Ce workflow ComfyUI MOSS TTS transforme le texte en parole vivante à 24 kHz en utilisant la famille OpenMOSS MOSS-TTS. Il couvre la synthèse rapide à un seul locuteur, le clonage de voix zéro-coup à partir d'un court extrait de référence, la conception vocale descriptive, les effets sonores procéduraux, et le dialogue multi-locuteurs avec des références optionnelles par locuteur.
Construit sur la pile de nœuds et la famille de modèles officiels MOSS-TTS, il équilibre vitesse et qualité. Le chemin Local 1.7B est la voie rapide pratique sur un seul GPU, tandis que les modèles Delay 8B plus grands échangent la vitesse pour une capacité et une expressivité plus larges. Si vous avez besoin de prompts réutilisables, de voix clonées ou de dialogues dans ComfyUI, ce workflow ComfyUI MOSS TTS est conçu pour vous.
Modèles clés dans le workflow ComfyUI MOSS TTS#
- OpenMOSS MOSS-TTS Local 1.7B. Transformateur de synthèse vocale à un seul GPU qui délivre une parole naturelle à 24 kHz pour le travail de production quotidien. Carte du modèle : MOSS-TTS-Local-Transformer.
- OpenMOSS MOSS-TTS Delay 8B. Une ligne de modèles plus grande qui met l'accent sur la qualité, la similarité des locuteurs et la prosodie au détriment de la vitesse et de la mémoire. Carte du modèle : MOSS-TTS.
- MOSS Audio Tokenizer. Le codec appris qui relie les formes d'onde et les tokens discrets pour les modèles MOSS-TTS, permettant un décodage haute fidélité. Carte du modèle : MOSS-Audio-Tokenizer.
Pour les détails de mise en œuvre et les mises à jour, consultez les dépôts officiels : OpenMOSS/MOSS-TTS et la pile de nœuds alimentant ce workflow richservo/comfyui-moss-tts.
Comment utiliser le workflow ComfyUI MOSS TTS#
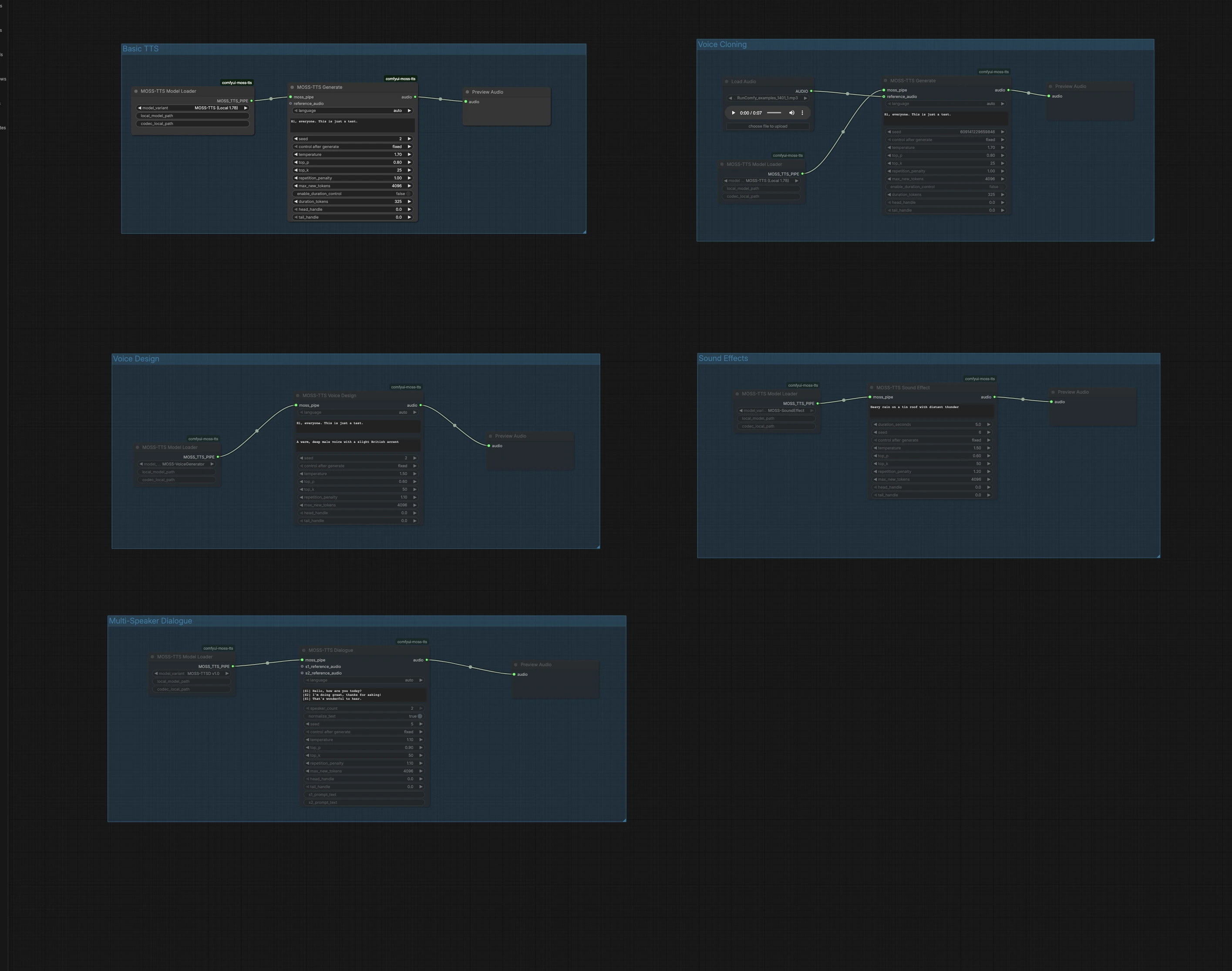
Ce graphique est organisé en cinq groupes indépendants. Choisissez le groupe qui correspond à votre objectif, exécutez-le, puis prévisualisez l'audio directement sur le canevas. Vous pouvez exécuter plusieurs groupes en parallèle pour auditionner différentes approches.
TTS de base#
Le groupe TTS de base convertit le texte brut en parole avec le chemin rapide Local 1.7B. Chargez le modèle dans MossTTSModelLoader (#1), alimentez votre texte dans MossTTSGenerate (#2), puis écoutez dans PreviewAudio (#3). Le générateur se conditionne sur votre prompt pour façonner la prononciation et la prosodie, donc écrivez naturellement avec ponctuation pour le rythme. Gardez la graine fixe lorsque vous voulez des prises répétables, ou randomisez-la lorsque vous explorez des variantes de livraison.
Clonage de voix#
Le groupe de clonage de voix effectue le clonage de voix zéro-coup à partir d'un court extrait audio de référence. Importez un échantillon de voix propre en utilisant LoadAudio (#4), connectez-le à MossTTSGenerate (#6) piloté par MossTTSModelLoader (#5), et fournissez le texte cible. Le modèle extrait le timbre et le style du locuteur à partir de la référence et rend votre nouveau script dans cette voix. Utilisez un contenu neutre et un bruit de fond minimal dans la référence pour améliorer la similarité, et gardez les durées modérées pour un retour rapide.
Conception de voix#
La conception de voix crée une nouvelle voix à partir d'une description en langage naturel plutôt que d'un extrait d'exemple. MossTTSVoiceDesign (#9) utilise une description textuelle comme "Une voix masculine chaude, profonde avec un léger accent britannique," combinée à votre script, pour synthétiser une parole à 24 kHz. Le nœud est alimenté par un chemin de générateur de voix dédié chargé via MossTTSModelLoader (#8). C'est idéal lorsque vous voulez une persona cohérente et reproductible sans source d'enregistrements réels. Affinez les descripteurs avec des traits tels que l'âge, le timbre, l'accent et l'énergie pour orienter le son.
Effets sonores#
Les effets sonores génèrent de l'audio non verbal à partir de prompts textuels, utiles pour les pistes de fond, les transitions ou les couches ambiantes. Avec MossTTSSoundEffect (#12) et son tuyau modèle de MossTTSModelLoader (#11), des prompts comme "Pluie battante sur un toit en tôle avec tonnerre lointain" produisent des textures riches et bouclables. Utilisez des noms et des actions concis pour définir la scène, puis ajoutez quelques adjectifs pour clouer l'intensité ou la distance. Prévisualisez dans PreviewAudio (#13) et itérez rapidement pour ajuster votre mixage.
Dialogue multi-locuteurs#
Le groupe de dialogue multi-locuteurs rend des conversations scriptées avec des extraits de référence optionnels par locuteur. Écrivez votre script en utilisant des balises de locuteur entre crochets, par exemple [S1] Bonjour. et [S2] Salut !, puis passez-le à MossTTSDialogue (#15) sous le tuyau modèle de MossTTSModelLoader (#14). Vous pouvez attacher des entrées audio de référence pour S1 et S2 pour cloner des voix spécifiques pour chaque rôle, ou les laisser vides pour laisser le modèle choisir des locuteurs distincts à partir du contexte textuel seul. Ce chemin est bien adapté pour les appels et réponses, la narration avec des lignes de personnages, ou les maquettes d'interface utilisateur vocale.
Nœuds clés dans le workflow ComfyUI MOSS TTS#
MossTTSModelLoader (#1)#
Charge la famille de modèles OpenMOSS sélectionnée et assemble le pipeline TTS interne. Choisissez la variante Local 1.7B pour une itération rapide sur un seul GPU, ou passez à un modèle Delay 8B plus grand lorsque vous privilégiez l'expressivité et la similarité. Gardez un chargeur par famille de tâches pour que chaque branche en aval reste autonome.
MossTTSGenerate (#2)#
Le principal synthétiseur à un seul locuteur qui consomme votre prompt textuel et un audio de référence optionnel pour produire une parole à 24 kHz. Fournissez un texte propre et bien ponctué pour un rythme plus clair, et connectez un court extrait vocal lorsque vous avez besoin d'un clonage zéro-coup. Basculer entre des semences fixes et aléatoires pour équilibrer la reproductibilité et l'exploration.
MossTTSVoiceDesign (#9)#
Génère une voix nouvelle à partir d'un prompt descriptif accompagné du texte à prononcer. Concentrez la description sur le timbre, l'âge, l'accent et l'énergie pour orienter l'identité tout en la gardant concise. C'est un choix fort lorsque le licenciement ou la source d'une voix réelle n'est pas pratique.
MossTTSSoundEffect (#12)#
Synthétise de l'audio non verbal à partir d'une courte description textuelle. Écrivez des prompts compacts qui ancrent la source, l'action et l'espace, puis itérez pour correspondre à la scène. Idéal pour l'ambiance et les one-shots dans le même graphique ComfyUI MOSS TTS que vous utilisez pour le dialogue.
MossTTSDialogue (#15)#
Analyse les balises de locuteur entre crochets et rend les conversations multi-tours comme une seule sortie audio. Utilisez [S1], [S2], etc. pour marquer chaque ligne, et connectez éventuellement des extraits de référence par locuteur pour préserver l'identité à travers les tours. Gardez les lignes concises pour les transferts les plus fiables entre les locuteurs.
Extras optionnels#
- Commencez avec le modèle Local 1.7B pour des brouillons rapides, puis passez à un point de contrôle Delay 8B lorsque vous avez besoin d'une plus forte similarité ou d'une prosodie plus riche.
- Pour le clonage zéro-coup, utilisez un extrait vocal propre de 5 à 15 s avec un minimum de réverbération et de bruit pour améliorer le transfert de timbre.
- Dans le dialogue, gardez les balises de locuteur cohérentes et sans ponctuation comme
[S1]pour éviter les erreurs d'analyse. - Concevez des prompts de conception vocale avec 3 à 6 traits tels que le timbre, l'âge, l'accent, le style et l'énergie pour des résultats prévisibles.
- Utilisez la ponctuation et les sauts de ligne dans votre texte pour contrôler les pauses et le rythme dans les sorties ComfyUI MOSS TTS.
- Ajoutez un nœud
SaveAudioaprès toute prévisualisation si vous souhaitez une exportation automatique de fichiers pour les rendus par lots.
Références : OpenMOSS/MOSS-TTS • MOSS-TTS-Local-Transformer • MOSS-TTS • MOSS-Audio-Tokenizer • comfyui-moss-tts
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement richservo pour les nœuds personnalisés ComfyUI MOSS-TTS, OpenMOSS pour le dépôt MOSS-TTS, et OpenMOSS-Team pour les modèles MOSS-TTS (Delay 8B et Local 1.7B) et le MOSS Audio Tokenizer pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation et aux dépôts originaux liés ci-dessous.
Ressources#
- richservo/comfyui-moss-tts
- GitHub: richservo/comfyui-moss-tts
- OpenMOSS/MOSS-TTS
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS (Delay 8B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS-Local-Transformer (Local 1.7B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS-Local-Transformer
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-Audio-Tokenizer
- Hugging Face: OpenMOSS-Team/MOSS-Audio-Tokenizer
- arXiv: 2602.10934
Note : L'utilisation des modèles, ensembles de données et code référencés est soumise aux licences et termes respectifs fournis par leurs auteurs et mainteneurs.