
Portrait Fantastique : Animation de portrait riche en expressions dans ComfyUI#
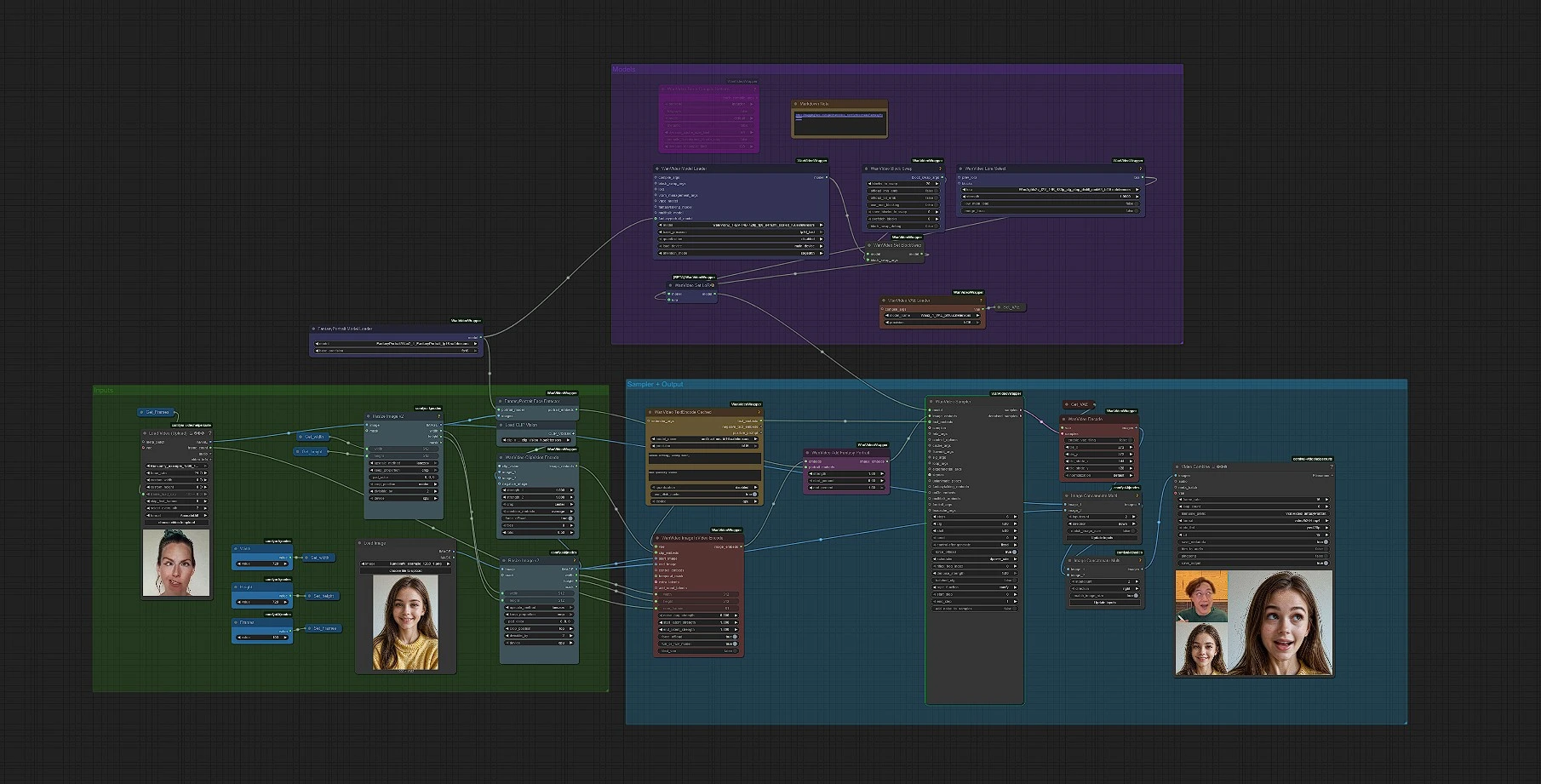
Ce workflow transforme une seule image fixe en une animation de Portrait Fantastique haute-fidélité. Il intègre le modèle FantasyPortrait de Fantasy-AMAP avec des transformateurs de diffusion augmentée par expressions et l'enveloppe dans un pipeline image-à-vidéo Wan Video 2.1, vous permettant de générer des prises de vue parlantes denses en émotions et préservant l'identité avec une configuration minimale. Il est conçu pour les créateurs qui souhaitent un mouvement cinématographique de Portrait Fantastique à partir d'une seule photo, avec des contrôles clairs pour le cadrage, la durée et le style.
Le pipeline est entièrement automatisé : déposez un portrait, choisissez votre résolution et le nombre d'images, ajoutez éventuellement une invite et un LoRA, puis rendez en MP4. Sous le capot, le graphe détecte le visage, encode les directives d'image et de texte, fusionne les embeddings d'identité de Fantasy Portrait dans le conditionneur I2V de Wan, échantillonne une vidéo et décode les images avant de sauvegarder le clip final.
Modèles clés dans le workflow ComfyUI Fantasy Portrait#
FantasyPortrait (Fantasy-AMAP)
Module d'identité et d'expression de base. Fournit des embeddings augmentés par expressions qui préservent les traits du sujet tout en permettant un mouvement facial nuancé. GitHub | Article (arXiv)
WanVideo 2.1 I2V (14B, 720p)
Épine dorsale de diffusion vidéo utilisée pour l'échantillonnage de l'animation à partir du portrait et du conditionnement texte/image. Des poids quantifiés, prêts pour Comfy, sont disponibles via le pack de modèles de Kijai. Hugging Face: Kijai/WanVideo_comfy
UMT5-XXL encoder
Encodeur de texte haute capacité utilisé pour les directives d'invite dans l'échantillonneur vidéo. Exemple de poids : umt5-xxl-enc-bf16.safetensors dans Kijai/WanVideo_comfy
Wan 2.1 VAE
VAE optimisé pour la vidéo pour l'encodage/décodage des latents. Exemple de poids : Wan2_1_VAE_bf16.safetensors dans Kijai/WanVideo_comfy
Comment utiliser le workflow ComfyUI Fantasy Portrait#
Le workflow se déroule de gauche à droite, des entrées à la vidéo finale. Vous allez principalement configurer trois éléments au départ : image, dimensions et durée. Ensuite, vous pouvez affiner avec une courte invite ou un LoRA si vous le souhaitez.
1) Entrée d'image et dimensionnement#
Chargez un seul portrait dans LoadImage, puis il est redimensionné pour le traitement. Deux étapes de redimensionnement garantissent que l'image correspond à votre largeur et hauteur choisies tout en maintenant la composition. Utilisez les commandes Width, Height et Frames pour définir la taille de sortie (par défaut 720 × 720) et la longueur de l'animation. Cela garde votre cadrage de Fantasy Portrait cohérent à travers le pipeline.
2) Détection de visage et embeddings Fantasy Portrait#
FantasyPortraitModelLoader charge les poids FantasyPortrait, et FantasyPortraitFaceDetector extrait des embeddings de portrait conscients de l'identité et de l'expression à partir de votre image. L'idée centrale est de séparer qui est le sujet de comment il exprime, donc l'animation finale préserve l'identité tout en permettant un mouvement expressif. Vous n'avez pas besoin de régler quoi que ce soit ici à moins que vous ne changiez de modèles.
3) Conditionnement d'image et de texte#
Pour les directives d'image, CLIPVisionLoader avec WanVideoClipVisionEncode produit des caractéristiques visuelles robustes à partir du portrait. Pour les directives de texte, WanVideoTextEncodeCached utilise l'encodeur UMT5-XXL pour transformer vos invites positives et négatives en embeddings de conditions vidéo. Une courte invite simple comme "gros plan naturel en studio, sourire doux" est souvent suffisante pour un look propre de Fantasy Portrait.
4) Encodage I2V avec contrôle de durée#
VHS_LoadVideo est utilisé comme compteur de trames pratique. Vous pouvez laisser le clip de remplacement ou charger une référence avec votre durée préférée ; son nombre de trames alimente WanVideoImageToVideoEncode, qui transforme votre image de départ plus les embeddings image/texte en conditionnement I2V. Si vous préférez une longueur fixe, réglez simplement Frames directement et ignorez le chargeur de référence.
5) Fusion Fantasy Portrait#
WanVideoAddFantasyPortrait fusionne le conditionnement I2V avec les embeddings de portrait de l'étape 2. C'est ce qui donne à l'animation finale de Fantasy Portrait sa forte préservation de l'identité et son détail expressif. Aucune entrée supplémentaire n'est requise une fois votre image chargée.
6) Configuration du modèle et LoRA#
WanVideoModelLoader charge Wan 2.1, puis WanVideoLoraSelect applique éventuellement un LoRA I2V léger du pack Kijai pour biaiser le mouvement ou l'esthétique sans réentraîner. C'est un bon endroit pour expérimenter si vous voulez un Fantasy Portrait légèrement plus stylisé tout en gardant l'identité intacte.
7) Échantillonnage et décodage vidéo#
WanVideoSampler génère des trames latentes en utilisant le conditionnement fusionné. Gardez les invites simples, augmentez modérément les étapes si vous avez besoin de plus de détails, et évitez de surconcerner avec de longues négatives. WanVideoDecode convertit les latents en images, et le workflow concatène les aperçus avant que VHS_VideoCombine n'écrive un MP4 (par défaut 16 fps, yuv420p). Le préfixe du nom de fichier de sortie est défini pour plus de commodité.
Nœuds clés dans le workflow ComfyUI Fantasy Portrait#
FantasyPortraitModelLoader (#138)#
Charge les poids FantasyPortrait. Échangez ici si vous testez une nouvelle version de Fantasy-AMAP. Aucun réglage n'est requis, mais gardez la précision cohérente avec votre modèle Wan et VAE.
FantasyPortraitFaceDetector (#142)#
Extrait les embeddings de portrait de l'image redimensionnée. De bons résultats proviennent de photos bien éclairées, face à l'avant avec peu d'occlusion. Si le mouvement semble décalé, vérifiez le recadrage d'entrée et essayez une source d'image plus propre.
WanVideoImageToVideoEncode (#151)#
Construit le conditionnement I2V de Wan à partir des caractéristiques d'image CLIP, de votre image de départ et de la durée. Ajustez width, height et num_frames pour contrôler l'empreinte de rendu et la longueur. Les séquences plus longues nécessitent plus de VRAM et de temps.
WanVideoAddFantasyPortrait (#150)#
Fusionne les identités/expressions de Fantasy Portrait dans le conditionneur I2V. Utilisez cela pour garder le sujet reconnaissable à travers les trames tout en permettant des changements d'expression nuancés. Aucun paramètre ne nécessite généralement d'ajustement.
WanVideoSampler (#149)#
Génère les latents vidéo. Si vous voulez des détails plus nets, augmentez légèrement les étapes. Si le mouvement dérive, réduisez la complexité de l'invite ou essayez un autre LoRA. Gardez les directives cohérentes plutôt que verbeuses.
WanVideoTextEncodeCached (#155)#
Encode les invites positives/négatives avec UMT5-XXL. Utilisez des phrases courtes et descriptives. Des invites négatives trop fortes (par exemple, des piles "mauvaise qualité" lourdes) peuvent supprimer l'expression.
Conseils#
- Commencez avec un carré de 720 × 720 et 4 à 6 secondes pour une itération rapide, puis augmentez si nécessaire.
- Utilisez un portrait propre, éclairé de face, avec des yeux visibles. Évitez les occlusions lourdes, les lunettes de soleil ou les angles extrêmes.
- Gardez les invites de Fantasy Portrait concises. Décrivez l'éclairage et l'ambiance, pas l'identité.
- Essayez un LoRA doux du pack Kijai si vous voulez une sensation de mouvement différente sans perdre l'identité.
Remerciements#
Ce workflow utilise le modèle Fantasy Portrait de l'équipe Fantasy-AMAP, intégrant des Transformateurs de Diffusion Augmentée par Expressions dans ComfyUI pour un pipeline d'animation de portrait entièrement automatisé et de haute qualité. Un merci spécial à kijai pour avoir créé et intégré le nœud Wrapper Wan Video, rendant possible l'exécution transparente de l'animation de portrait dans un cadre image-à-vidéo. Nous remercions également la communauté ComfyUI plus large pour leurs contributions continues aux outils créatifs ouverts.
Liens :
