
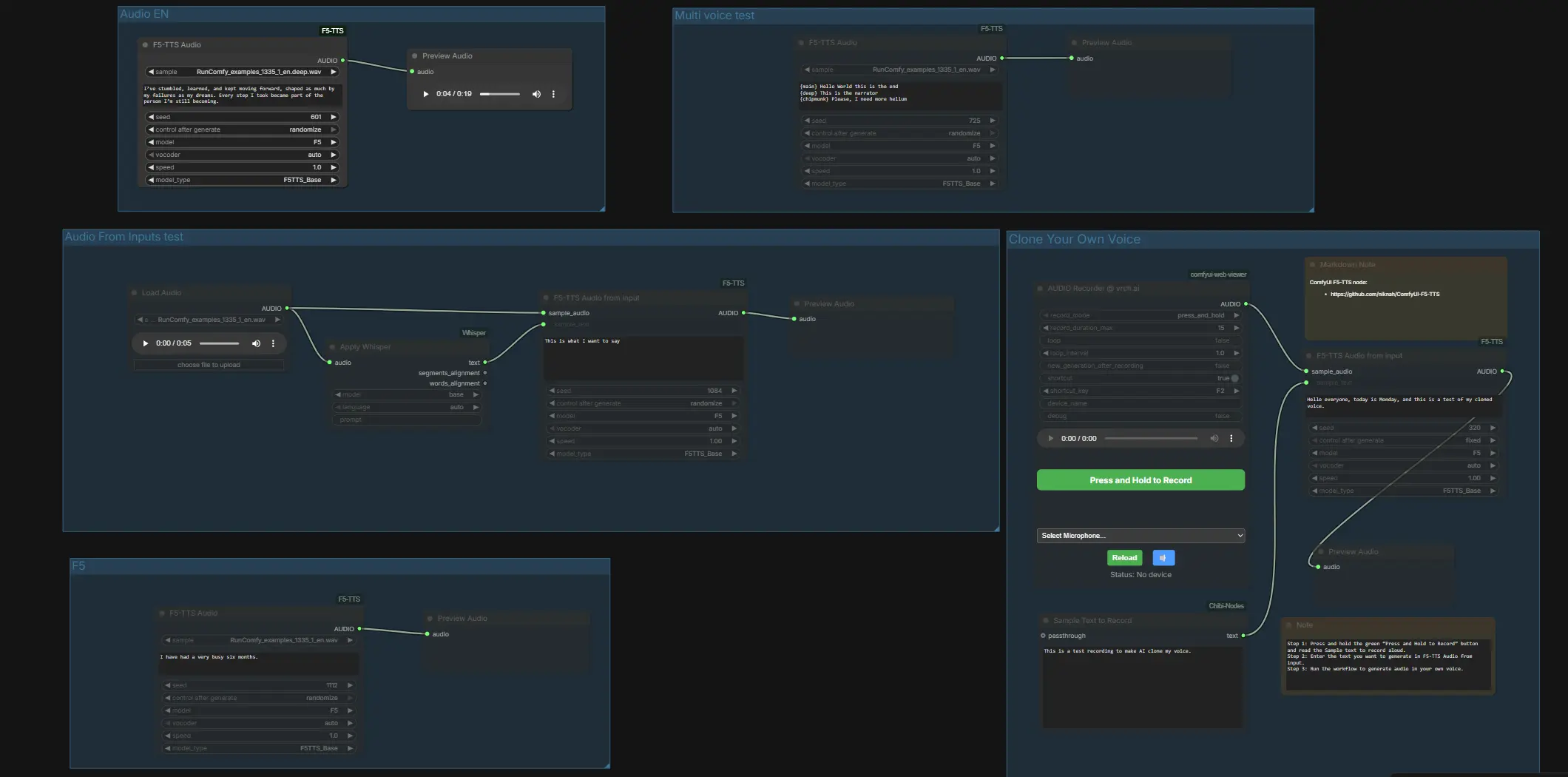
ComfyUI F5 TTS : texte-à-parole et clonage de voix en un seul flux de travail#
Ce flux de travail ComfyUI F5 TTS vous permet de générer un discours naturel à partir de texte et de cloner des voix directement à l'intérieur de ComfyUI. Il est alimenté par les nœuds personnalisés ComfyUI-F5-TTS et comprend un chemin complet pour le clonage basé sur des références : fournissez un court fichier WAV plus une transcription correspondante pour conditionner le modèle, puis synthétisez de nouvelles lignes qui suivent le timbre et le style du locuteur de référence. Le graphique est également livré avec des tests prêts à l'emploi pour plusieurs variantes de modèles, langues et vocodeurs, afin que vous puissiez comparer rapidement les sorties et décider ce qui convient le mieux aux narrations, voix off, dialogues de personnages ou démonstrations de produits.
Tout est organisé en groupes clairs pour que vous puissiez utiliser ComfyUI F5 TTS de deux manières : TTS rapide en un clic en anglais, français, allemand et japonais, ou clonage de voix via un enregistreur intégré ou des fichiers appariés. Un chemin de transcription Whisper compact est inclus pour vous aider à obtenir une transcription d'échantillon précise lorsque vous avez déjà un enregistrement propre.
Modèles clés dans le flux de travail ComfyUI F5 TTS#
- Fish Audio F5-TTS. TTS zéro-coup qui apprend les caractéristiques d'un locuteur à partir d'une courte référence et produit un discours de haute qualité dans plusieurs langues. Voir le projet pour les détails du modèle et le contexte de formation. GitHub
- OpenAI Whisper. Reconnaissance vocale utilisée ici pour transcrire automatiquement votre extrait de référence afin que le texte d'échantillon corresponde exactement, ce qui améliore la qualité du clonage. GitHub
- BigVGAN. Un vocodeur neuronal haute fidélité disponible en option de décodage pour une sortie plus nette et plus claire. GitHub
- Vocos. Une alternative de vocodeur neuronal rapide et légère axée sur la vitesse et la faible latence. GitHub
- Nœuds personnalisés ComfyUI-F5-TTS. L'intégration ComfyUI qui connecte F5-TTS et les backends compatibles en nœuds utilisés tout au long de ce graphique. GitHub
Comment utiliser le flux de travail ComfyUI F5 TTS#
À un niveau élevé, le flux de travail offre des groupes indépendants pour des comparaisons rapides de modèles et une voie de clonage dédiée. Commencez par auditionner les groupes préconfigurés pour confirmer la voix et le vocodeur que vous préférez, puis passez au clonage avec votre propre échantillon. Chaque sous-section ci-dessous explique ce que fait le groupe et les quelques entrées qui comptent.
Test Audio From Inputs#
Cette voie démontre la transcription de référence plus le conditionnement. LoadAudio (#4) importe un WAV, Apply Whisper (#13) le transcrit, et F5TTSAudioInputs (#26) utilise à la fois l'échantillon audio et le texte Whisper pour conditionner la voix avant l'aperçu. Fournissez un échantillon parlé propre et laissez Whisper remplir le port de transcription pour que la paire corresponde exactement. Si vous souhaitez fournir des fichiers directement, placez un .wav et un .txt appariés avec le même nom de fichier dans ComfyUI/input, puis redémarrez ComfyUI pour que le graphique puisse les voir.
Test multi-voix#
Ce groupe montre le changement stylistique au sein d'une ligne en utilisant un seul nœud de synthèse. F5TTSAudio (#17) lit un script avec des segments étiquetés, vous permettant d'auditionner plusieurs styles de caractères ou des changements d'emphase en un seul passage. C'est un moyen rapide d'entendre comment ComfyUI F5 TTS gère les timbres contrastés ou le rythme narrateur-versus-personnage.
Audio EN#
Utilisez F5TTSAudio (#15) pour un TTS anglais simple. Entrez votre script et prévisualisez pour évaluer la prononciation de base et le rythme avec le préréglage F5 par défaut. Cette voie est idéale pour une itération rapide avant de vous engager dans le clonage ou le mélange multi-voix.
F5v1#
Ce chemin exécute le nœud F5TTSAudio (#33) contre la variante F5 v1 afin que vous puissiez comparer le ton et la prosodie avec le préréglage principal F5. Utilisez le même texte que la voie EN pour rendre les différences faciles à juger. C'est utile lors du choix d'un modèle par défaut pour un projet plus long.
Audio FR#
Cette voie cible la synthèse française avec F5TTSAudio (#27) configuré pour un préréglage français. Fournissez un script en français et prévisualisez la sortie pour vérifier les voyelles nasales et la gestion des liaisons. Alternez avec la voie EN pour comparer la clarté et la vitesse.
Audio DE bigvgan#
Ici, F5TTSAudio (#30) utilise un préréglage allemand et le vocodeur BigVGAN pour un décodage plus brillant et plus net. Utilisez cette voie lorsque vous souhaitez plus de présence ou un éclat de type studio. Si vous préférez un rendu plus doux, comparez avec une voie Vocos.
Audio JP#
Ce chemin utilise F5TTSAudio (#25) avec un préréglage japonais. Collez un script japonais pour évaluer l'accent de hauteur et le timing des moras. C'est un bon point de départ pour des lectures de style anime ou des lignes de produits destinées à un public japonais.
Test E2#
Ce groupe utilise F5TTSAudio (#29) avec un préréglage compatible E2 et le vocodeur Vocos pour auditionner un backend alternatif. Utilisez-le pour comparer la latence et les caractéristiques de timbre avec vos exécutions F5.
Clonez votre propre voix#
Enregistrez, appariez et clonez directement dans ComfyUI. Appuyez sur le microphone dans VrchAudioRecorderNode (#43) et lisez l'invite affichée dans la boîte "Sample Text to Record" Textbox (#42). L'enregistreur dirige votre WAV vers F5TTSAudioInputs (#44) avec le texte exact que vous avez prononcé, ce qui conditionne le modèle sur votre timbre et votre style avant l'aperçu dans PreviewAudio (#45). Pour de meilleurs résultats, parlez dans une pièce calme et assurez-vous que le texte de référence correspond exactement à ce que vous avez dit ; puis tapez toutes les nouvelles lignes que vous souhaitez que la voix clonée dise et exécutez le graphique.
Nœuds clés dans le flux de travail ComfyUI F5 TTS#
F5TTSAudio (#15)#
Le nœud TTS à passage unique principal utilisé dans les groupes EN, FR, DE, JP, F5v1 et E2. Fournissez votre script et choisissez le préréglage de modèle et le vocodeur qui conviennent à votre langue et à votre diffusion. Si vous souhaitez des prises reproductibles, gardez la graine fixe ; si vous souhaitez de la variété, randomisez entre les exécutions. L'implémentation est fournie par l'extension ComfyUI-F5-TTS. GitHub GitHub - FishAudio/F5-TTS
F5TTSAudioInputs (#44)#
Le point d'entrée de clonage qui consomme un WAV de référence et sa transcription correspondante pour construire une représentation du locuteur, puis synthétise de nouvelles lignes dans cette voix. Utilisez un échantillon propre avec une intensité sonore constante et assurez-vous que la transcription est exacte pour maximiser la similarité et réduire les artefacts. Changez les préréglages de modèle ou les vocodeurs ici si vous avez besoin d'un décodage plus brillant ou plus neutre. GitHub - FishAudio/F5-TTS
Apply Whisper (#13)#
Transcription automatique pour votre échantillon de référence. Choisissez une taille de Whisper qui équilibre la vitesse et la précision pour votre matériel et votre langue, puis alimentez son texte de sortie au nœud de clonage pour que l'audio et le texte soient parfaitement alignés. Cela prévient les erreurs de conditionnement qui peuvent se produire lorsque le texte d'échantillon diffère de ce qui a été réellement dit. GitHub
VrchAudioRecorderNode (#43)#
Un enregistreur intégré au graphique qui capture une courte invite parlée pour le clonage, éliminant le besoin d'outils externes. Maintenez pour enregistrer, relâchez pour arrêter et entendez immédiatement comment ComfyUI F5 TTS sonne dans votre propre voix. Gardez le micro proche et réduisez le bruit ambiant pour un résultat le plus propre possible.
Extras optionnels#
- Utilisez de 5 à 15 secondes de discours propre pour la référence, sans musique ni effets.
- Assurez-vous que la transcription de l'échantillon correspond exactement à l'enregistrement ; même de petites discordances peuvent réduire la fidélité du clonage.
- Comparez Vocos et BigVGAN sur la même ligne pour décider entre vitesse et détail.
- Gardez une graine fixe lorsque vous avez besoin de reprises cohérentes ; randomisez lorsque vous explorez le style.
- Pour les projets multilingues, auditionnez d'abord les voies EN, FR, DE et JP, puis finalisez le clonage une fois que vous êtes satisfait de la prononciation et du rythme.
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement niknah pour le nœud ComfyUI-F5-TTS, niknah pour l'exemple de flux de travail F5TTS-test-all.json, et la communauté r/StableDiffusion pour le guide "Voice Cloning with F5-TTS in ComfyUI" pour leurs contributions et leur maintenance. Pour des détails autorisés, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- niknah/ComfyUI-F5-TTS
- GitHub: niknah/ComfyUI-F5-TTS
- niknah/ComfyUI-F5-TTS (Exemple de flux de travail : F5TTS-test-all.json)
- r/StableDiffusion/Guide Communautaire (Clonage Vocal avec F5-TTS dans ComfyUI)
Note : L'utilisation des modèles, ensembles de données et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.