
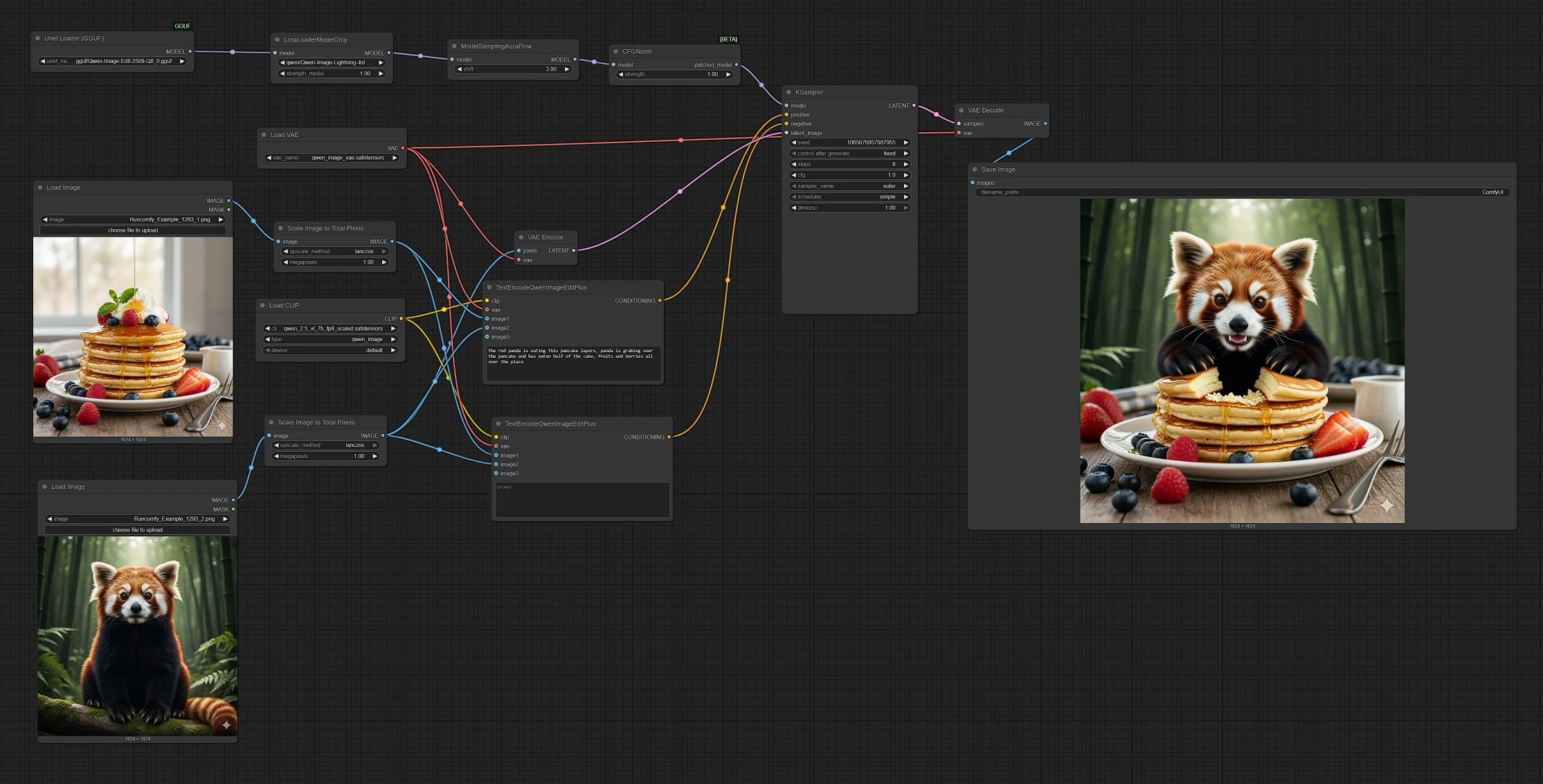






Qwen Image Edit 2509: edición y fusión de múltiples imágenes impulsada por indicaciones para ComfyUI#
Qwen Image Edit 2509 es un flujo de trabajo de edición de múltiples imágenes para ComfyUI que fusiona 2-3 imágenes de entrada bajo una sola indicación para crear ediciones precisas y fusiones sin costuras. Está diseñado para creadores que desean componer objetos, restilizar escenas, reemplazar elementos o fusionar referencias manteniendo el control intuitivo y predecible.
Este gráfico de ComfyUI combina el modelo de imagen Qwen con un codificador de texto consciente de la edición para que puedas guiar los resultados con lenguaje natural y una o más referencias visuales. De forma predeterminada, Qwen Image Edit 2509 maneja la transferencia de estilo, la inserción de objetos y los remixes de escenas, produciendo resultados coherentes incluso cuando las fuentes varían en apariencia o calidad.
Modelos clave en el flujo de trabajo ComfyUI Qwen Image Edit 2509#
- Qwen Image Edit 2509 (Diffusion Model & GGUF, Q8_0). El punto de control principal de edición de imágenes, cargado en forma cuantificada para reducir VRAM mientras se preserva el comportamiento de edición. Proporciona la columna vertebral de difusión que interpreta texto e imágenes de referencia durante el muestreo.
- Qwen Image VAE. Un VAE dedicado adaptado para Qwen Image que codifica el lienzo base en espacio latente y decodifica los resultados finales de nuevo a píxeles. Fuente del activo: Comfy-Org/Qwen-Image_ComfyUI.
- Codificador de texto Qwen 2.5 VL 7B (FP8 escalado). Un codificador de texto de visión-lenguaje empaquetado para ComfyUI que convierte tu indicación más imágenes de referencia en condiciones de edición. Fuente del activo: Comfy-Org/Qwen-Image_ComfyUI.
- Qwen-Image-Lightning-4steps-V1.0 LoRA. Un LoRA opcional que inclina el modelo hacia actualizaciones rápidas y de alto impacto, útil para iteraciones rápidas o bajos recuentos de pasos. Página del modelo: lightx2v/Qwen-Image-Lightning.
Cómo usar el flujo de trabajo ComfyUI Qwen Image Edit 2509#
Este flujo de trabajo sigue un camino claro desde las entradas hasta la salida: cargas 2-3 imágenes, escribes una indicación, el gráfico codifica tanto el texto como las referencias, el muestreo se ejecuta sobre una base latente, y el resultado se decodifica y guarda.
Etapa 1 — Cargar y dimensionar tus fuentes
- Usa
LoadImage(#103) para la Imagen 1 yLoadImage(#109) para la Imagen 2. La Imagen 2 actúa como el lienzo base que recibirá las ediciones. - Cada imagen pasa por
ImageScaleToTotalPixels(#93 y #108) para que ambas referencias compartan un presupuesto de píxeles consistente. Esto estabiliza la composición y la transferencia de estilo. - Si deseas una tercera referencia, conecta otra
LoadImagea la entradaimage3en los nodos de codificación. Qwen Image Edit 2509 acepta hasta tres imágenes para una guía más rica.
Etapa 2 — Escribir la indicación y establecer la intención
- El codificador positivo
TextEncodeQwenImageEditPlus(#104) combina tu indicación de texto con la Imagen 1 y la Imagen 2 para describir el resultado que deseas. Usa lenguaje natural para solicitar fusiones, reemplazos o indicaciones de estilo. - El codificador negativo
TextEncodeQwenImageEditPlus(#106) te permite alejarte de detalles no deseados. Déjalo vacío para mantenerte neutral o agrega frases que supriman artefactos o estilos que no deseas. - Ambos codificadores usan el codificador de texto Qwen y VAE, por lo que el modelo "ve" tus referencias como parte de la instrucción.
Etapa 3 — Preparar el modelo
UnetLoaderGGUF(#102) carga la columna vertebral de Qwen Image Edit 2509 en formato GGUF para una inferencia eficiente.LoraLoaderModelOnly(#89) aplica el LoRA Qwen-Image-Lightning. Aumenta su influencia para ediciones más impactantes o redúcela para actualizaciones más conservadoras.- Luego, el modelo se prepara para el muestreo con una configuración ajustada para la estabilidad de la edición.
Etapa 4 — Generación guiada
- El lienzo base (Imagen 2) es codificado por
VAEEncode(#88) y proporcionado aKSampler(#3) como el latente inicial. Esto hace que la ejecución sea de imagen-a-imagen en lugar de solo texto-a-imagen. KSampler(#3) fusiona las condiciones positivas y negativas con el lienzo latente para producir el resultado editado. Bloquea la semilla para reproducibilidad o varíala para explorar alternativas.- Las elecciones de guía y muestreo equilibran la fidelidad a tus fuentes con la adherencia a la indicación, dando a Qwen Image Edit 2509 su combinación de precisión y flexibilidad.
Etapa 5 — Decodificar y guardar
VAEDecode(#8) convierte el latente final en una imagen, ySaveImage(#60) la escribe en tu carpeta de salida. Los nombres de archivo reflejan la ejecución para que puedas comparar versiones fácilmente.
Nodos clave en el flujo de trabajo ComfyUI Qwen Image Edit 2509#
TextEncodeQwenImageEditPlus (#104)#
Este nodo crea la condición de edición positiva combinando tu indicación con hasta tres imágenes de referencia a través del codificador Qwen. Úsalo para especificar qué debe aparecer, qué estilo adoptar y cuán fuertemente deben influir las referencias en el resultado. Comienza con un objetivo claro de una sola oración, luego agrega descriptores de estilo o indicaciones de cámara según sea necesario. Los activos para el codificador están empaquetados en Comfy-Org/Qwen-Image_ComfyUI.
TextEncodeQwenImageEditPlus (#106)#
Este nodo forma la condición negativa para prevenir rasgos no deseados. Agrega frases cortas que bloqueen artefactos, suavizado excesivo o estilos desajustados. Manténlo minimalista para evitar contradecir la intención positiva. Utiliza el mismo codificador Qwen y pila VAE que el camino positivo.
UnetLoaderGGUF (#102)#
Carga el punto de control Qwen Image Edit 2509 en formato GGUF para una inferencia amigable con VRAM. Una cuantización más alta ahorra memoria pero puede afectar ligeramente el detalle fino; si tienes espacio, prueba una cuantización menos agresiva para maximizar la fidelidad. Referencia de implementación: city96/ComfyUI-GGUF.
LoraLoaderModelOnly (#89)#
Aplica el LoRA Qwen-Image-Lightning sobre el modelo base para acelerar la convergencia y fortalecer las ediciones. Aumenta strength_model para enfatizar el efecto de este LoRA o redúcelo para una guía más sutil. Página del modelo: lightx2v/Qwen-Image-Lightning. Referencia del nodo principal: comfyanonymous/ComfyUI.
ImageScaleToTotalPixels (#93, #108)#
Redimensiona cada entrada a un recuento total de píxeles consistente utilizando remuestreo de alta calidad. Aumentar el objetivo de megapíxeles produce resultados más nítidos a costa de tiempo y memoria; reducirlo acelera la iteración. Mantén ambas referencias a escalas similares para ayudar a Qwen Image Edit 2509 a mezclar elementos limpiamente. Referencia del nodo principal: comfyanonymous/ComfyUI.
KSampler (#3)#
Ejecuta los pasos de difusión que transforman el lienzo latente según tus condiciones. Ajusta los pasos y el muestreador para equilibrar velocidad y fidelidad, y varía la semilla para explorar múltiples composiciones desde la misma configuración. Para ediciones ajustadas que preserven la estructura de la Imagen 2, mantén los recuentos de pasos moderados y confía en la indicación y las referencias para el control. Referencia del nodo principal: comfyanonymous/ComfyUI.
Extras opcionales#
- Trata la Imagen 2 como el lienzo y la Imagen 1 como el donante; describe en la indicación qué elementos deben transferirse y cuáles deben permanecer.
- Usa negativos concisos para frenar halos, deslizamiento de textura o sobre-estilización; listas largas de negativos pueden entrar en conflicto con tu objetivo.
- Si los resultados parecen demasiado conservadores, aumenta la fuerza del LoRA o los pasos de muestreo ligeramente; si se desvían demasiado del base, redúcelos.
- Aumenta el objetivo de megapíxeles al finalizar, luego reutiliza la misma semilla para escalar exactamente la composición que te gustó.
- Mantén las indicaciones concretas: sujeto, acción, configuración y estilo. Qwen Image Edit 2509 responde mejor a una intención clara con unos pocos descriptores fuertes.
Reconocimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos sinceramente a RobbaW por el flujo de trabajo Qwen Image Edit 2509 por sus contribuciones y mantenimiento. Para obtener detalles autorizados, consulta la documentación y los repositorios originales vinculados a continuación.
Recursos#
- RobbaW/Qwen Image Edit 2509 Workflow
- Hugging Face: QuantStack/Qwen-Image-Edit-2509-GGUF
- Docs / Notas de Lanzamiento: Qwen Image Edit 2509 Workflow @RobbaW from Reddit r/comfyui
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.

