






Edición y composición de imágenes múltiples de Nunchaku Qwen Image para ComfyUI#
Nunchaku Qwen Image es un flujo de trabajo de edición y composición de imágenes múltiples impulsado por indicaciones para ComfyUI. Acepta hasta tres imágenes de referencia, te permite especificar cómo deben mezclarse o transformarse, y produce un resultado coherente guiado por lenguaje natural. Los casos de uso típicos incluyen la fusión de sujetos, el reemplazo de fondos o la transferencia de estilos y detalles de una imagen a otra.
Construido alrededor de la familia de imágenes Qwen, este flujo de trabajo brinda a artistas, diseñadores y creadores un control preciso mientras se mantiene rápido y predecible. También incluye una ruta de edición de una sola imagen y una ruta de texto a imagen pura, para que puedas generar, refinar y componer dentro de un solo pipeline de Nunchaku Qwen Image.
Nota: Por favor, selecciona tipos de máquina dentro del rango de Medium a 2XLarge. El uso de tipos de máquina 2XLarge Plus o 3XLarge no está soportado y resultará en un fallo de ejecución.
Modelos clave en el flujo de trabajo de Comfyui Nunchaku Qwen Image#
- Nunchaku Qwen Image Edit 2509. Pesos de difusión/DiT afinados para edición de imágenes guiada por indicaciones y transferencia de atributos. Fuerte en ediciones localizadas, intercambios de objetos y cambios de fondo. Model card
- Nunchaku Qwen Image (base). Generador base utilizado por la rama de texto a imagen para síntesis creativa sin una foto de origen. Model card
- Qwen2.5-VL 7B codificador de texto. Modelo de lenguaje multimodal que interpreta indicaciones y las alinea con características visuales para edición y generación. Model page
- Qwen Image VAE. Autoencoder variacional utilizado para codificar imágenes fuente en latentes y decodificar resultados finales con color y detalle fieles. Assets
Cómo usar el flujo de trabajo de Comfyui Nunchaku Qwen Image#
Este gráfico contiene tres rutas independientes que comparten el mismo lenguaje visual y lógica de muestreo. Usa una rama a la vez dependiendo de si estás editando múltiples imágenes, refinando una sola imagen o generando desde texto.
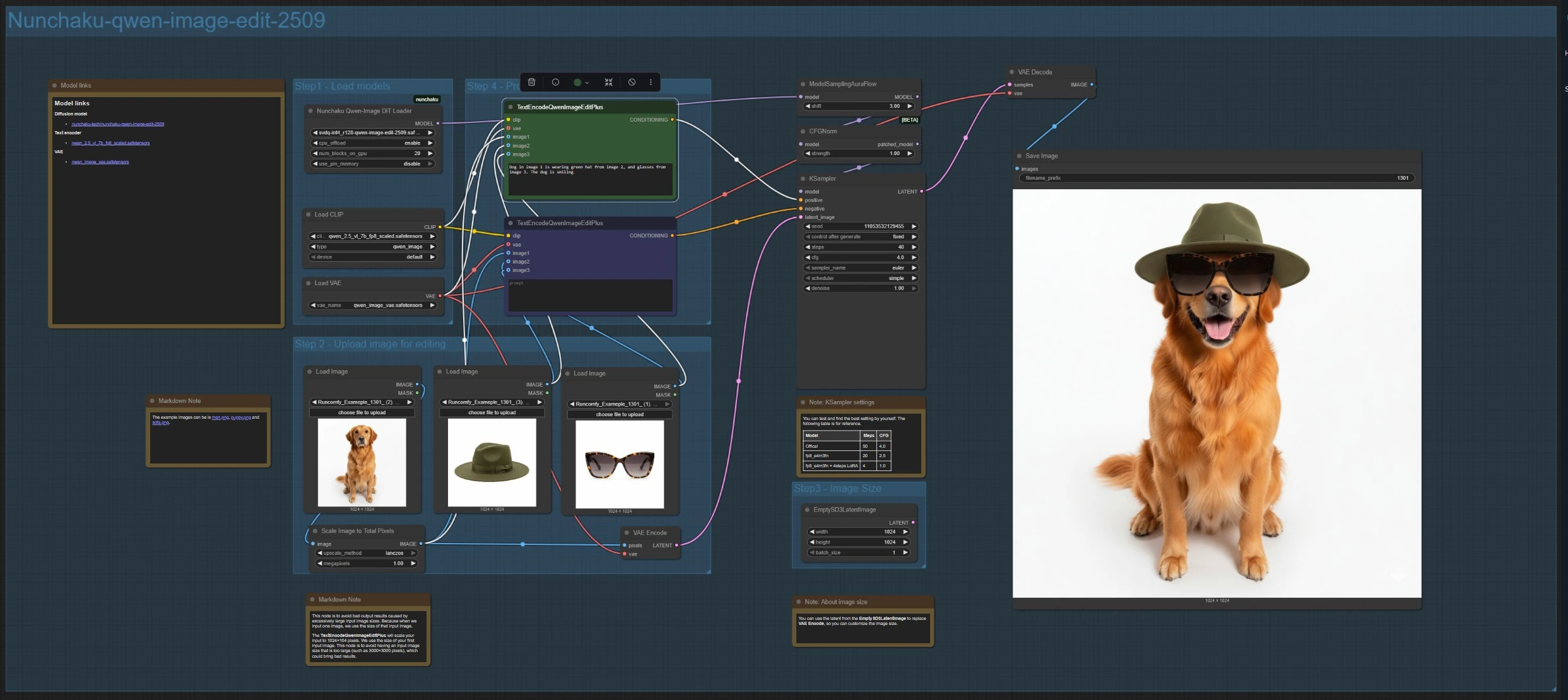
Nunchaku-qwen-image-edit-2509 (edición y composición de imágenes múltiples)#
Esta rama carga el modelo de edición con NunchakuQwenImageDiTLoader (#115), lo enruta a través de ModelSamplingAuraFlow (#66) y CFGNorm (#75), luego sintetiza con KSampler (#3). Sube hasta tres imágenes usando LoadImage (#78, #106, #108). La referencia principal se codifica con VAEEncode (#88) para establecer el lienzo, y ImageScaleToTotalPixels (#93) mantiene las entradas dentro de un rango de tamaño estable.
Escribe tu instrucción en TextEncodeQwenImageEditPlus (#111) y, si es necesario, coloca eliminaciones o restricciones en el emparejado TextEncodeQwenImageEditPlus (#110). Refiera a las fuentes explícitamente, por ejemplo: “El perro en la imagen 1 lleva el sombrero verde de la imagen 2 y las gafas de la imagen 3.” Para un tamaño de salida personalizado, puedes reemplazar el latente codificado con EmptySD3LatentImage (#112). Los resultados se decodifican con VAEDecode (#8) y se guardan con SaveImage (#60).
Nunchaku-qwen-image-edit (refinamiento de una sola imagen)#
Elige esto cuando desees limpiezas específicas, cambios de fondo o ajustes de estilo en una imagen. El modelo se carga mediante NunchakuQwenImageDiTLoader (#120), adaptado por ModelSamplingAuraFlow (#125) y CFGNorm (#123), y muestreado por KSampler (#127). Importa tu foto con LoadImage (#129); se normaliza con ImageScaleToTotalPixels (#130) y se codifica con VAEEncode (#131).
Proporciona tu instrucción en TextEncodeQwenImageEdit (#121) y una orientación contraria opcional en TextEncodeQwenImageEdit (#122) para mantener o eliminar elementos. La rama decodifica con VAEDecode (#124) y escribe archivos a través de SaveImage (#128).
Nunchaku-qwen-image (texto a imagen)#
Usa esta rama para crear nuevas imágenes desde cero con el modelo base. NunchakuQwenImageDiTLoader (#146) alimenta ModelSamplingAuraFlow (#138). Introduce tus indicaciones positivas y negativas en CLIPTextEncode (#143) y CLIPTextEncode (#137). Establece tu lienzo con EmptySD3LatentImage (#136), luego genera con KSampler (#141), decodifica usando VAEDecode (#142), y guarda con SaveImage (#147).
Nodos clave en el flujo de trabajo de Comfyui Nunchaku Qwen Image#
NunchakuQwenImageDiTLoader (#115) Carga los pesos de imagen Qwen y la variante utilizada por la rama. Selecciona el modelo de edición para ediciones guiadas por fotos o el modelo base para texto a imagen. Cuando la VRAM lo permite, las variantes de mayor precisión o resolución pueden ofrecer más detalle; las variantes más ligeras priorizan la velocidad.
TextEncodeQwenImageEditPlus (#111) Impulsa ediciones de imágenes múltiples al analizar tu instrucción y vincularla con hasta tres referencias. Mantén las directivas explícitas sobre qué imagen contribuye con qué atributo. Usa frases concisas y evita objetivos contradictorios para mantener las ediciones enfocadas.
TextEncodeQwenImageEditPlus (#110) Actúa como el codificador negativo o de restricción emparejado para la rama de imágenes múltiples. Úsalo para excluir objetos, estilos o artefactos que no deseas que aparezcan. Esto a menudo ayuda a preservar la composición mientras se eliminan superposiciones de UI o elementos no deseados.
TextEncodeQwenImageEdit (#121) Instrucción positiva para la rama de edición de una sola imagen. Describe el resultado deseado, las cualidades de la superficie y la composición en términos claros. Aspira a una a tres oraciones que especifiquen la escena y los cambios.
TextEncodeQwenImageEdit (#122) Indicación negativa o de restricción para la rama de edición de una sola imagen. Enumera elementos o características a evitar, o describe elementos a eliminar de la imagen fuente. Esto es útil para limpiar texto perdido, logotipos o elementos de interfaz.
ImageScaleToTotalPixels (#93) Evita que las entradas de gran tamaño desestabilicen los resultados al escalar a un recuento total de píxeles objetivo. Úsalo para armonizar resoluciones de origen dispares antes de componer. Si notas una nitidez inconsistente entre las fuentes, acércalas en tamaño efectivo aquí.
ModelSamplingAuraFlow (#66) Aplica un programa de muestreo DiT/flujo coincidente afinado para los modelos de imagen Qwen. Si las salidas se ven oscuras, borrosas o carecen de estructura, aumenta el desplazamiento del programa para estabilizar el tono global; si se ven planas, reduce el desplazamiento para buscar detalle adicional.
KSampler (#3) El muestreador principal donde equilibras velocidad, fidelidad y variedad estocástica. Ajusta los pasos y la escala de orientación para consistencia versus creatividad, elige un método de muestreo y bloquea una semilla cuando deseas reproducibilidad exacta a través de ejecuciones.
CFGNorm (#75) Normaliza la orientación libre de clasificador para reducir la sobresaturación o explosiones de contraste a escalas de orientación más altas. Déjalo en el camino como se proporciona; ayuda a mantener el color y la exposición constantes mientras iteras en indicaciones.
Extras opcionales#
- Para obtener los mejores resultados de imágenes múltiples, elige fuentes con perspectiva e iluminación similares; el modelo de edición de Nunchaku Qwen Image se centra entonces en el contenido en lugar de corregir la geometría.
- Refiera a las fuentes por orden (“imagen 1”, “imagen 2”, “imagen 3”) y sea explícito sobre qué atributos se transfieren a dónde.
- Cuando las salidas se desvían hacia lo oscuro o borroso, empuja el desplazamiento de
ModelSamplingAuraFlowhacia arriba; cuando desees textura adicional, prueba un desplazamiento ligeramente más bajo. - Para establecer una resolución específica, intercambia el latente codificado por
EmptySD3LatentImageen la rama que estés usando. - Usa indicaciones negativas para eliminar texto de la UI, marcas de agua u objetos no deseados antes de invertir en un estilo detallado; esto mantiene las ediciones de Nunchaku Qwen Image limpias desde el principio.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Nunchaku por el flujo de trabajo Qwen-Image (ComfyUI-nunchaku) por sus contribuciones y mantenimiento. Para detalles autorizados, por favor, consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- Nunchaku/Qwen-Image
- GitHub: nunchaku-tech/ComfyUI-nunchaku
- Hugging Face: nunchaku-tech/nunchaku-qwen-image
- arXiv: SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
- Docs / Release Notes: Nunchaku Qwen Image Source
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.



