
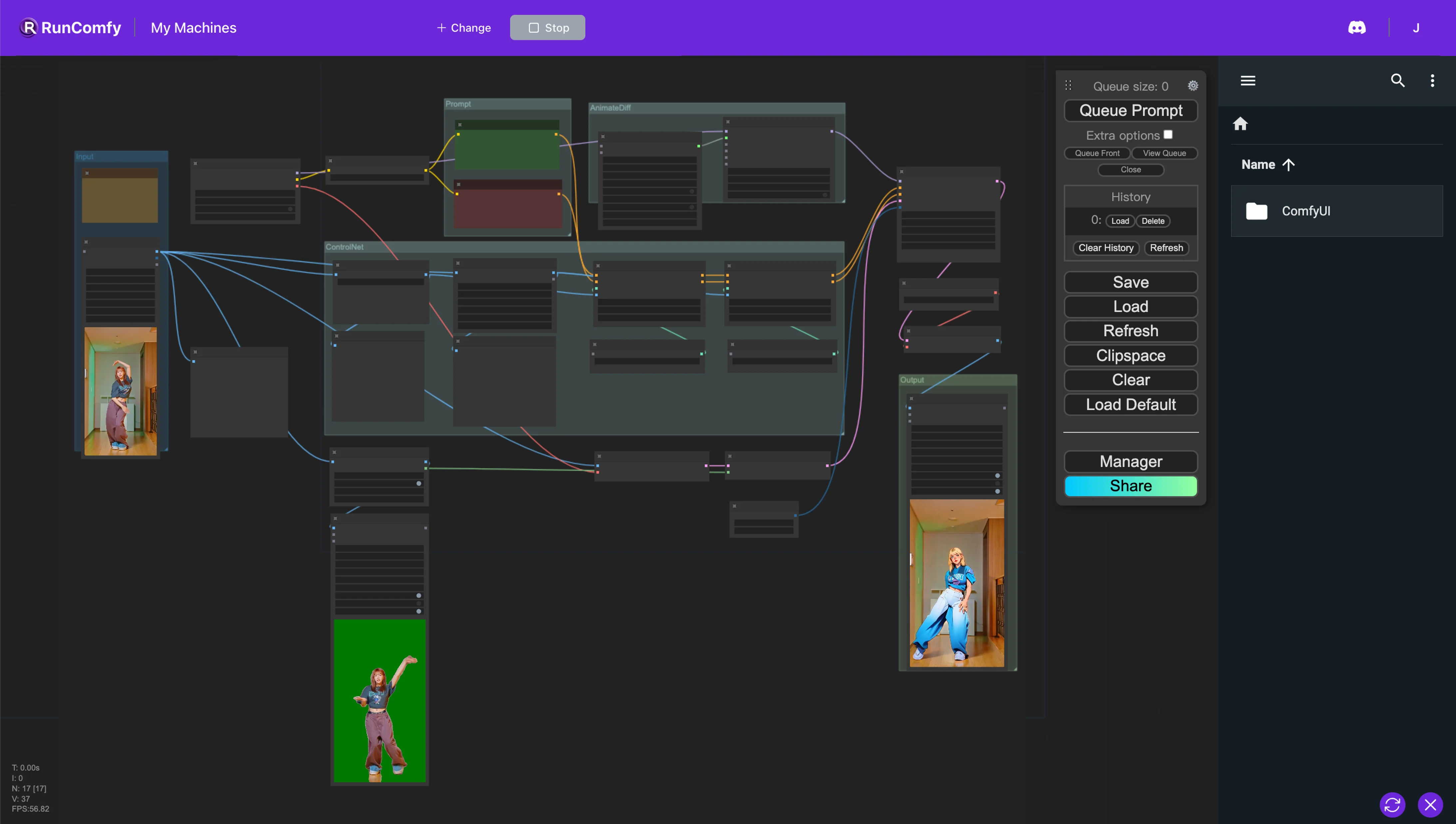
1. Flujo de trabajo ComfyUI AnimateDiff, ControlNet y Auto Mask#
Este flujo de trabajo de ComfyUI introduce un enfoque poderoso para cambiar el estilo de los videos, específicamente dirigido a transformar personajes en un estilo de anime mientras se preservan los fondos originales. Esta transformación es respaldada por varios componentes clave, incluidos AnimateDiff, ControlNet y Auto Mask.
AnimateDiff está diseñado para técnicas de animación diferencial, permitiendo el mantenimiento de un contexto consistente dentro de las animaciones. Este componente se enfoca en suavizar las transiciones y mejorar la fluidez del movimiento en el contenido de video con estilo modificado.
ControlNet desempeña un papel crítico en la replicación y manipulación precisas de la pose humana. Aprovecha la estimación avanzada de poses para capturar y controlar con precisión los matices del movimiento humano, facilitando la transformación de personajes en formas de anime mientras preserva sus poses originales.
Auto Mask está involucrado en la segmentación automática, hábil para aislar personajes de sus fondos. Esta tecnología permite el cambio de estilo selectivo de los elementos de video, asegurando que las transformaciones de los personajes se ejecuten sin alterar el entorno circundante, manteniendo la integridad de los fondos originales.
Este flujo de trabajo de ComfyUI realiza la conversión de contenido de video estándar en animaciones estilizadas, enfocándose en la eficiencia y la calidad de la generación de personajes al estilo anime.
2. Descripción general de AnimateDiff#
2.1. Introducción a AnimateDiff#
AnimateDiff surge como una herramienta de IA diseñada para animar imágenes estáticas y prompts de texto en videos dinámicos, aprovechando los modelos de Stable Diffusion y un módulo de movimiento especializado. Esta tecnología automatiza el proceso de animación al predecir transiciones sin problemas entre fotogramas, haciéndolo accesible para los usuarios sin habilidades de programación o recursos informáticos a través de una plataforma en línea gratuita.
2.2. Características clave de AnimateDiff#
2.2.1. Soporte de modelo integral: AnimateDiff es compatible con varias versiones, incluidas AnimateDiff v1, v2, v3 para Stable Diffusion V1.5 y AnimateDiff sdxl para Stable Diffusion SDXL. Permite el uso de múltiples modelos de movimiento simultáneamente, facilitando la creación de animaciones complejas y en capas.
2.2.2. El tamaño del lote de contexto determina la duración de la animación: AnimateDiff permite la creación de animaciones de longitud infinita mediante el ajuste del tamaño del lote de contexto. Esta función permite a los usuarios personalizar la duración y la transición de las animaciones para satisfacer sus requisitos específicos, proporcionando un proceso de animación altamente adaptable.
2.2.3. Longitud del contexto para transiciones suaves: El propósito de la Longitud de Contexto Uniforme en AnimateDiff es garantizar transiciones sin problemas entre diferentes segmentos de una animación. Al ajustar la Longitud de Contexto Uniforme, los usuarios pueden controlar la dinámica de transición entre escenas: longitudes más largas para transiciones más suaves y sin problemas, y longitudes más cortas para cambios más rápidos y pronunciados.
2.2.4. Dinámica de movimiento: En AnimateDiff v2, los LoRAs de movimiento especializados están disponibles para agregar movimientos de cámara cinematográficos a las animaciones. Esta característica introduce una capa dinámica a las animaciones, mejorando significativamente su atractivo visual.
2.2.5. Características de soporte avanzadas: AnimateDiff está diseñado para funcionar con una variedad de herramientas, incluidas ControlNet, SparseCtrl e IPAdapter, ofreciendo ventajas significativas para los usuarios que buscan expandir las posibilidades creativas de sus proyectos.
3. Descripción general de ControlNet#
3.1. Introducción a ControlNet#
ControlNet introduce un marco para aumentar los modelos de difusión de imágenes con entradas condicionales, con el objetivo de refinar y guiar el proceso de síntesis de imágenes. Lo logra duplicando los bloques de red neuronal dentro de un modelo de difusión dado en dos conjuntos: uno permanece "bloqueado" para preservar la funcionalidad original, y el otro se vuelve "entrenable", adaptándose a las condiciones específicas proporcionadas. Esta estructura dual permite a los desarrolladores incorporar una variedad de entradas condicionales mediante el uso de modelos como OpenPose, Tile, IP-Adapter, Canny, Depth, LineArt, MLSD, Normal Map, Scribbles, Segmentation, Shuffle y T2I Adapter, influyendo así directamente en la salida generada. A través de este mecanismo, ControlNet ofrece a los desarrolladores una poderosa herramienta para controlar y manipular el proceso de generación de imágenes, mejorando la flexibilidad del modelo de difusión y su aplicabilidad a diversas tareas creativas.
Preprocesadores e integración de modelos
3.1.1. Configuración de preprocesamiento: Iniciar con ControlNet implica seleccionar un preprocesador adecuado. Se recomienda activar la opción de vista previa para comprender visualmente el impacto del preprocesamiento. Después del preprocesamiento, el flujo de trabajo pasa a utilizar la imagen preprocesada para pasos de procesamiento adicionales.
3.1.2. Coincidencia de modelos: Simplificando el proceso de selección de modelos, ControlNet garantiza la compatibilidad alineando los modelos con sus preprocesadores correspondientes según las palabras clave compartidas, facilitando un proceso de integración sin problemas.
3.2. Características clave de ControlNet#
Exploración en profundidad de los modelos de ControlNet
3.2.1. Suite OpenPose: Diseñada para la detección precisa de poses humanas, la suite OpenPose abarca modelos para detectar poses corporales, expresiones faciales y movimientos de las manos con precisión excepcional. Varios preprocesadores de OpenPose están adaptados a requisitos de detección específicos, desde el análisis básico de poses hasta la captura detallada de matices faciales y manuales.
3.2.2. Modelo Tile Resample: Mejorando la resolución y los detalles de la imagen, el modelo Tile Resample se utiliza de manera óptima junto con una herramienta de ampliación, con el objetivo de enriquecer la calidad de la imagen sin comprometer la integridad visual.
3.2.3. Modelo IP-Adapter: Facilitando el uso innovador de imágenes como prompts, IP-Adapter integra elementos visuales de imágenes de referencia en las salidas generadas, fusionando las capacidades de difusión de texto a imagen para un contenido visual enriquecido.
3.2.4. Detector de bordes Canny: Venerado por sus capacidades de detección de bordes, el modelo Canny enfatiza la esencia estructural de las imágenes, permitiendo reinterpretaciones visuales creativas mientras mantiene las composiciones centrales.
3.2.5. Modelos de percepción de profundidad: A través de una variedad de preprocesadores de profundidad, ControlNet es experto en derivar y aplicar señales de profundidad de las imágenes, ofreciendo una perspectiva de profundidad en capas en las imágenes generadas.
3.2.6. Modelos LineArt: Convierta imágenes en dibujos artísticos de líneas con los preprocesadores LineArt, atendiendo diversas preferencias artísticas desde anime hasta bocetos realistas, ControlNet se adapta a un espectro de deseos estilísticos.
3.2.7. Procesamiento de garabatos: Con preprocesadores como Scribble HED, Pidinet y xDoG, ControlNet transforma imágenes en arte único de garabatos, ofreciendo varios estilos para la detección de bordes y la reinterpretación artística.
3.2.8. Técnicas de segmentación: Las capacidades de segmentación de ControlNet clasifican con precisión los elementos de la imagen, permitiendo una manipulación precisa basada en la categorización de objetos, ideal para construcciones de escenas complejas.
3.2.9. Modelo Shuffle: Introduciendo un método para la innovación de esquemas de color, el modelo Shuffle aleatoriza las imágenes de entrada para generar nuevos patrones de color, alterando creativamente el original mientras conserva su esencia.
3.2.10. Innovaciones del adaptador T2I: Los modelos del adaptador T2I, que incluyen Color Grid y CLIP Vision Style, impulsan a ControlNet hacia nuevos dominios creativos, combinando y adaptando colores y estilos para producir resultados visualmente atractivos que respetan el esquema de color o los atributos estilísticos del original.
3.2.11. MLSD (Detección de segmentos de línea móviles): Especializado en la detección de líneas rectas, MLSD es invaluable para proyectos enfocados en diseños arquitectónicos y de interiores, priorizando la claridad y precisión estructural.
3.2.12. Procesamiento de mapas normales: Utilizando datos de orientación de superficies, los preprocesadores de Normal Map replican la estructura 3D de imágenes de referencia, mejorando el realismo del contenido generado a través del análisis detallado de superficies.
