
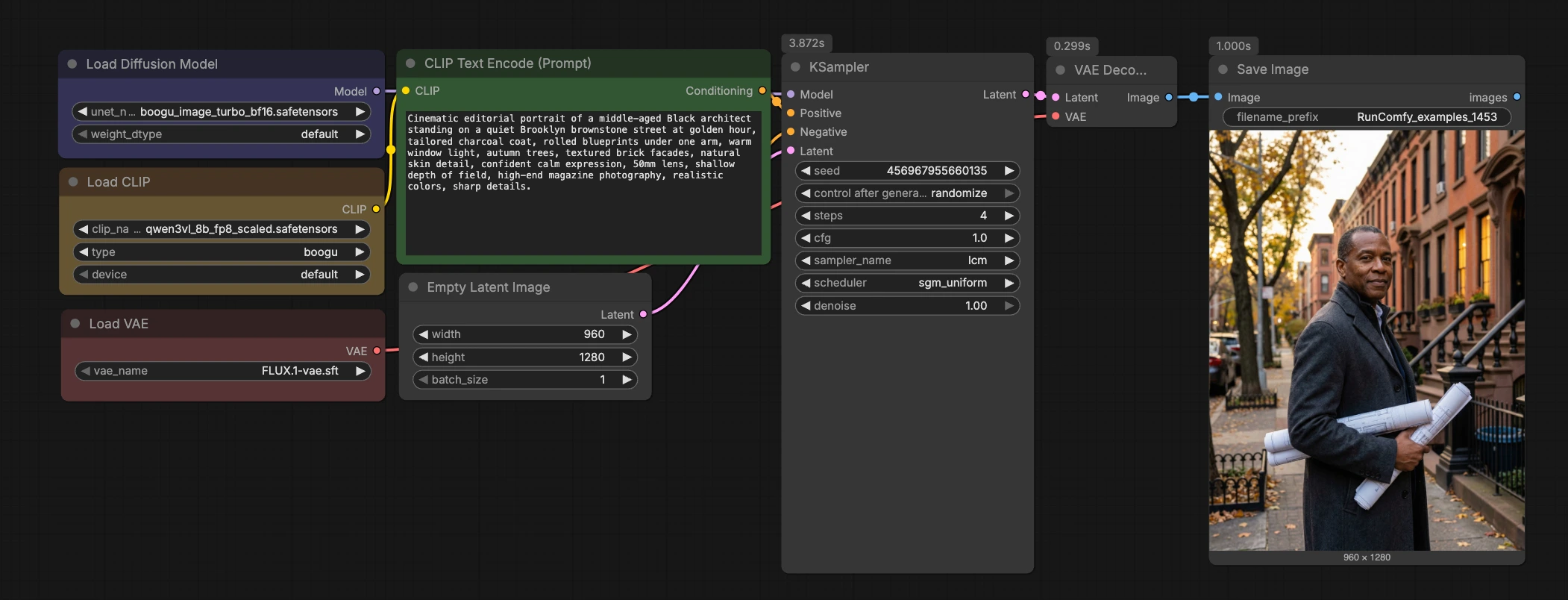






Boogu Turbo texto-a-imagen ComfyUI workflow#
Este flujo de trabajo Boogu Turbo texto-a-imagen ComfyUI es un camino limpio y rápido desde el prompt hasta la imagen utilizando el punto de control Boogu-Image-0.1-Turbo con muestreo LCM de cuatro pasos. Se combina el codificador de texto Qwen3-VL con el FLUX.1 VAE para que puedas iterar rápidamente mientras mantienes el gráfico minimalista y fácil de reutilizar en proyectos.
Diseñado para una exploración visual rápida, el flujo de trabajo sobresale en entornos cinematográficos, fondos estilo anime, paisajes atmosféricos, máquinas de productos imaginativas y escenas arquitectónicas. Si deseas un flujo de trabajo Boogu Turbo texto-a-imagen ComfyUI ligero que esté listo para RunComfy y sea simple de inspeccionar, esta plantilla es un punto de inicio sólido.
Modelos clave en el flujo de trabajo Comfyui Boogu Turbo texto-a-imagen ComfyUI#
- Boogu-Image-0.1-Turbo. La variante Turbo destilada está diseñada para texto-a-imagen fotorrealista rápido con inferencia típica de 3–4 pasos y escala de guía cercana a 1.0. Los pesos del modelo oficial y las instrucciones están disponibles en Hugging Face, con archivos reempaquetados listos para ComfyUI proporcionados por Comfy-Org. Ver Boogu/Boogu-Image-0.1-Turbo-fp8 y el paquete ComfyUI curado en Comfy-Org/Boogu-Image.
- Codificador de texto Qwen3-VL 8B. Esta moderna columna vertebral de visión-lenguaje se utiliza aquí únicamente como un codificador de texto para producir fuertes incrustaciones de prompt para el modelo de difusión. Los codificadores empaquetados para ComfyUI están alojados en Comfy-Org/Qwen3-VL y el repositorio oficial es QwenLM/Qwen3-VL.
- FLUX.1 VAE. El autoencoder de Black Forest Labs codifica y decodifica imágenes entre espacio de píxeles y latente, ayudando a preservar la fidelidad del color y el contraste. Los pesos de referencia y la documentación están en black-forest-labs/FLUX.1-dev.
Cómo usar el flujo de trabajo Comfyui Boogu Turbo texto-a-imagen ComfyUI#
A simple vista, el flujo de trabajo codifica tu prompt, inicializa un lienzo latente, ejecuta un muestreador LCM rápido a través de Boogu-Image-0.1-Turbo, decodifica con el FLUX.1 VAE y guarda el resultado. El gráfico es intencionalmente compacto para que puedas integrarlo en otros proyectos o extenderlo con LoRAs, ControlNets o cadenas de post-procesamiento.
Codificación de prompt con Qwen3-VL (CLIPLoader (#7) → CLIPTextEncode (#11))#
Esta etapa carga un codificador Qwen3-VL y convierte tu prompt de texto en vectores de acondicionamiento. Introduce tu prompt en CLIPTextEncode (#11) usando lenguaje natural; indicaciones fotográficas detalladas como lente, iluminación, hora del día y textura funcionan bien. La entrada negativa se anula intencionalmente a través de ConditioningZeroOut (#9) para mantener los resultados estables con el régimen de baja guía de Turbo. Si prefieres negativos explícitos, reemplaza ConditioningZeroOut con un segundo CLIPTextEncode para proporcionar un prompt negativo. Un buen manejo del prompt aquí reduce la necesidad de CFG alto o pasos adicionales más adelante.
Configuración latente y carga de modelo (EmptyLatentImage (#8) + UNETLoader (#2))#
EmptyLatentImage (#8) crea el lienzo latente. El aspecto por defecto de retrato 960×1280 es un punto de partida equilibrado para personas, interiores y tomas de productos altos; puedes establecer otros tamaños para cuadrados o panorámicas. UNETLoader (#2) carga los pesos de difusión de Boogu Turbo del paquete Comfy-Org, alineando el modelo con tu codificador y VAE elegidos. Cambiar entre variantes BF16 y FP8 es sencillo si necesitas equilibrar VRAM y rendimiento. Mantén la elección del modelo consistente en tu proyecto para mantener la continuidad de estilo.
Muestreo rápido LCM (KSampler (#32) con muestreador lcm)#
El KSampler está configurado para Modelos de Consistencia Latente para lograr alta calidad en alrededor de cuatro pasos. La destilación LCM apunta a valores de guía muy bajos, por eso este flujo de trabajo Boogu Turbo texto-a-imagen ComfyUI funciona de manera estable con CFG cerca de 1.0 mientras preserva la adherencia al prompt. Si deseas un poco más de micro-detalle, aumenta los pasos moderadamente y fija la semilla para comparaciones A/B. Para cambios de estilo o composición, re-lanza la semilla y refina el prompt en lugar de aumentar demasiado los pasos. La teoría de fondo sobre la inferencia de pocos pasos LCM se describe en el artículo original Latent Consistency Models.
Decodificar y guardar (VAELoader (#5) → VAEDecode (#3) → SaveImage (#58))#
El FLUX.1 VAE cargado en VAELoader (#5) decodifica latentes a RGB en VAEDecode (#3). Emparejar la familia VAE con tu columna vertebral de difusión generalmente produce colores y texturas más fieles, por eso este gráfico se envía con el FLUX.1 VAE. SaveImage (#58) escribe resultados en disco; cambia el prefijo de salida para organizar experimentos por prompt, semilla o relación de aspecto. Si luego encadenas ampliadores o post-fx, ramifica desde la salida Image de VAEDecode para preservar un historial limpio.
Nodos clave en el flujo de trabajo Comfyui Boogu Turbo texto-a-imagen ComfyUI#
CLIPTextEncode (#11)#
Este nodo alberga tu prompt de texto principal y produce el acondicionamiento positivo utilizado por el muestreador. Mantén los prompts concisos y agrega indicaciones de escena como longitud focal de cámara, hora del día y adjetivos de material. Si deseas usar prompts negativos, crea un segundo CLIPTextEncode y conéctalo a la entrada negativa del muestreador, eliminando ConditioningZeroOut (#9).
ConditioningZeroOut (#9)#
Esto desactiva el acondicionamiento negativo alimentando un vector cero en el puerto negativo del muestreador. Dejarlo en su lugar es una buena configuración por defecto para la configuración de baja guía de Turbo. Elimínalo solo cuando específicamente necesites prompts negativos y puedas articularlos claramente.
EmptyLatentImage (#8)#
Controla las dimensiones de salida y el tamaño de lote. Comienza en 960×1280 para retratos o 1280×960 para entornos más amplios; ajusta según el sujeto y el presupuesto de memoria. Latentes más grandes proporcionan más lienzo para detalles finos pero aumentan el uso de VRAM y el tiempo de decodificación.
UNETLoader (#2)#
Selecciona el punto de control Boogu-Image-0.1-Turbo para usar en la generación. Usa la variante BF16 para la mejor fidelidad en GPUs capaces o la variante FP8 para menor VRAM y cargas más rápidas, ambas disponibles en el paquete Comfy-Org. Los archivos del modelo y sus carpetas previstas están documentados en Comfy-Org/Boogu-Image.
KSampler (#32)#
Ejecuta el proceso de difusión con el muestreador lcm para inferencia de pocos pasos. Las palancas clave son la semilla, el número de pasos y CFG; Turbo está diseñado para funcionar con muy baja guía y pocos pasos mientras mantiene la calidad, como se refleja en las configuraciones oficiales de Turbo en la tarjeta de modelo en Boogu/Boogu-Image-0.1-Turbo-fp8. Para exploraciones controladas, fija la semilla y varía los pasos o la redacción del prompt un cambio a la vez.
VAELoader (#5) y VAEDecode (#3)#
Cargan y aplican el FLUX.1 VAE para decodificación. Mantenerse con la familia FLUX.1 mantiene los colores, el contraste y el comportamiento de textura consistentes con la configuración de entrenamiento del UNet. Mezclar VAEs es posible pero puede cambiar sutilmente la tonalidad o saturación; prueba antes de comprometerte a un nuevo aspecto. Pesos de referencia: black-forest-labs/FLUX.1-dev.
SaveImage (#58)#
Controla el nombre de salida y el destino. Usa prefijos significativos como nombre del proyecto, etiqueta de aspecto o semilla para mantener las ejecuciones organizadas. Al expandir la tubería, ramifica aquí para agregar ampliadores, gradación de color o subtituladores sin interrumpir la base de guardado.
Extras opcionales#
- Mantén CFG cerca de 1.0 y los pasos alrededor de cuatro para iteraciones más rápidas; pasa a 6–8 pasos solo cuando necesites un poco más de textura o estabilidad.
- Re-lanza la semilla para explorar la composición; fija la semilla para afinar el estilo y el micro-detalle.
- Prefiere pesos BF16 para la mejor calidad en GPUs de alta memoria; cambia a FP8 para acelerar la carga y reducir VRAM.
- Para legibilidad de texto en imagen, intenta una resolución ligeramente más alta e incluye indicaciones tipográficas explícitas en el prompt.
- Guarda favoritos intermedios a menudo; pequeños ajustes del prompt en este flujo de trabajo Boogu Turbo texto-a-imagen ComfyUI pueden producir escenas significativamente diferentes en segundos.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a RunningHub por la referencia del flujo de trabajo, Boogu por el repositorio de Boogu-Image y el modelo Boogu-Image-0.1-Turbo, Comfy-Org por los pesos de ComfyUI de Boogu y ComfyUI por el tutorial de Boogu por sus contribuciones y mantenimiento. Para obtener detalles autorizados, consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- Referencia de Workflow de RunningHub
- Documentos / Notas de versión: Publicación de RunningHub
- Sitio del proyecto Boogu
- Documentos / Notas de versión: boogu.org
- Repositorio de Boogu/Boogu Image
- GitHub: boogu-project/Boogu-Image
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- Modelo Boogu/Boogu-Image-0.1-Turbo
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- GitHub: boogu-project/Boogu-Image
- Pesos Comfy-Org/Boogu ComfyUI
- Hugging Face: Comfy-Org/Boogu-Image
- Tutorial de ComfyUI/Boogu
- Documentos / Notas de versión: Tutorial de ComfyUI
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.





